ZSim控制逻辑(banshee源码为例)
简单逻辑
banshee/buil/opt/init.cpp line337
x
} else if (type == "DramCache") { mem = new MemoryController(name, frequency, domain, config);此处调用MemoryController,接收参数为type,定义如下:
string type = config.get<const char*>("sys.mem.type", "Simple");该config指的是test目录下的.cfg类型的文件,执行方式为命令行执行即可,较为简单
xxxxxxxxxx./build/opt/zsim tests/xxx.cfg使用diff命令比较banshee与原生ZSim的init.cpp比较,除了上述改动之外,其余改动只是部分函数增加了config参数,因此init.cpp的逻辑几乎不用动。只需新增一个else if (type == "xxxx") {mem = new XXX(name,frequency,domain,config)};
因此,似乎只需要写好控制器,就能够完成整个系统的逻辑。至于统计输出也在控制器层面实现。
MemoryController —— 构造
以banshee实现为例,代码篇幅较长,大部分略去:
构造函数
构造函数初始化成员变量
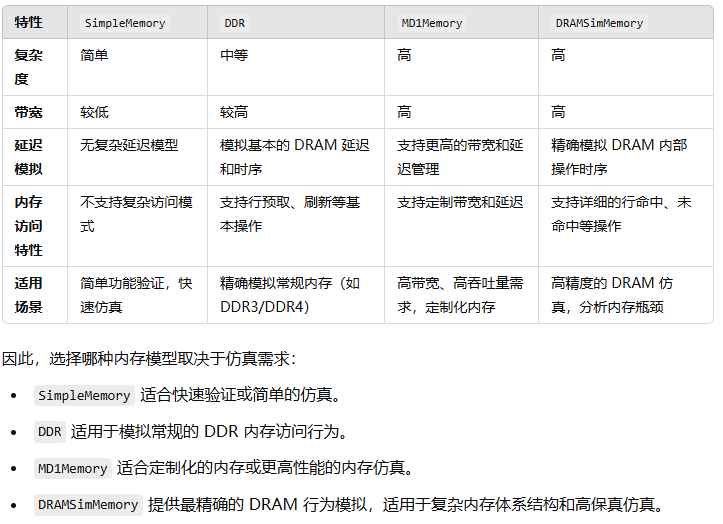
_name: 传入的内存控制器名称。_collect_trace: 是否收集内存访问跟踪。通过配置文件中的sys.mem.enableTrace参数决定。如果启用跟踪且当前控制器是mem-0,则初始化跟踪文件路径和文件。_sram_tag: 配置是否启用 SRAM 标记(从sys.mem.sram_tag获取)。_llc_latency: 配置 L3 缓存的延迟。_ext_type: 外部 DRAM 类型(通过sys.mem.ext_dram.type配置,可能是 Simple、DDR、MD1 或 DRAMSim)。_scheme: 内存控制器的缓存方案,通过sys.mem.cache_scheme配置,可能是NoCache、AlloyCache、UnisonCache、HybridCache等。_bw_balance: 是否启用带宽平衡(通过sys.mem.bwBalance配置)。
外部 DRAM 配置
外部 DRAM 的类型通过 _ext_type 配置,支持多种类型:
Simple: 使用
SimpleMemory模型初始化外部 DRAM。DDR: 使用
BuildDDRMemory函数创建 DDR 内存模型。MD1: 使用
MD1Memory创建一种新的 DRAM 模型。DRAMSim: 使用
DRAMSimMemory模型,并加载相关的配置文件。
内存控制器缓存配置
这里的Cache指的是DRAMCache,根据缓存方案(_scheme),初始化不同类型的缓存结构。缓存方案包括:
AlloyCache: 特定的缓存策略,要求granularity为 64 字节,num_ways为 1。UnisonCache: 另一种缓存策略,要求granularity为 4096 字节。HybridCache: 混合缓存策略,支持 4KB 或 2MB 页。NoCache: 没有缓存。Tagless: 不使用标签的缓存策略。
如果方案是 AlloyCache、UnisonCache 或 HybridCache,会根据配置初始化相关的缓存放置策略(例如,LinePlacementPolicy、PagePlacementPolicy)。
内存控制器模型的初始化
内存控制器的缓存模型(如
SimpleMemory、DDR、MD1Memory、DRAMSimMemory)通过不同的类型和配置进行初始化。片上堆叠内存或者HBM即这段代码中出现的
mc_dram。代码中根据
ext_dram和mc_dram的类型选择对应的内存初始化
缓存放置策略根据缓存方案不同被配置成不同的类型(如
LinePlacementPolicy、OSPlacementPolicy、PagePlacementPolicy)
在banshee/test/test.cfg中,ext_dram和mc_dram都使用的DDR
xxxxxxxxxxmem = { enableTrace = false; mapGranu = 64; controllers = 2; type = "DramCache"; cache_scheme = "AlloyCache"; ext_dram = { type = "DDR"; ranksPerChannel = 4; banksPerRank = 8; }; mcdram = { ranksPerChannel = 4; banksPerRank = 8; cache_granularity = 64; size = 512; mcdramPerMC = 8; num_ways = 1; sampleRate = 1.0; placementPolicy = "LRU"; type = "DDR"; }; };由于都选用了DDR作为ext_dram和mc_dram的类型,代码中实际调用了MemoryController::BuildDDRMemory函数:
xxxxxxxxxxDDRMemory* MemoryController::BuildDDRMemory(Config& config, uint32_t frequency, uint32_t domain, g_string name, const string& prefix, uint32_t tBL, double timing_scale) { uint32_t ranksPerChannel = config.get<uint32_t>(prefix + "ranksPerChannel", 4); uint32_t banksPerRank = config.get<uint32_t>(prefix + "banksPerRank", 8); // DDR3 std is 8 uint32_t pageSize = config.get<uint32_t>(prefix + "pageSize", 8*1024); // 1Kb cols, x4 devices const char* tech = config.get<const char*>(prefix + "tech", "DDR3-1333-CL10"); // see cpp file for other techs const char* addrMapping = config.get<const char*>(prefix + "addrMapping", "rank:col:bank"); // address splitter interleaves channels; row always on top
// If set, writes are deferred and bursted out to reduce WTR overheads bool deferWrites = config.get<bool>(prefix + "deferWrites", true); bool closedPage = config.get<bool>(prefix + "closedPage", true);
// Max row hits before we stop prioritizing further row hits to this bank. // Balances throughput and fairness; 0 -> FCFS / high (e.g., -1) -> pure FR-FCFS uint32_t maxRowHits = config.get<uint32_t>(prefix + "maxRowHits", 4);
// Request queues uint32_t queueDepth = config.get<uint32_t>(prefix + "queueDepth", 16); uint32_t controllerLatency = config.get<uint32_t>(prefix + "controllerLatency", 10); // in system cycles
auto mem = (DDRMemory *) gm_malloc(sizeof(DDRMemory)); new (mem) DDRMemory(zinfo->lineSize, pageSize, ranksPerChannel, banksPerRank, frequency, tech, addrMapping, controllerLatency, queueDepth, maxRowHits, deferWrites, closedPage, domain, name, tBL, timing_scale); return mem;}
MC_DRAM额外设置
由于banshee的论文,把mc_dram当成DRAMCache,因此在源代码中这部分主要就是设置banshee作为DRAMCache的模式:
AlloyCache是一种直接映射的 DRAM 缓存,它以细粒度存储数据。每个集合的标签和数据在 DRAM 缓存中是相邻存储的。对于每次标签探测,数据也会被预取加载。因此,在缓存命中时,延迟大致相当于一次 DRAM 访问的延迟。在缓存未命中时,Alloy Cache 会产生片上 DRAM 访问的延迟加上片外 DRAM 访问的延迟。在带宽消耗方面,Alloy Cache 需要 1)从 DRAM 缓存中加载标签和数据,2)从片外 DRAM 中加载数据,3)将访问的标签和数据插入 DRAM 缓存。因此,未命中和替换时,延迟和带宽消耗都会翻倍。原始的 Alloy Cache 论文 提出了并行发起对内包和片外 DRAM 的请求,以隐藏未命中延迟。然而,banshee假设采用的实现是串行访问,因为预取访问片外 DRAM 会显著增加对已经有限的片外 DRAM 带宽的压力。
UnisonCache以粗粒度存储数据并支持集合关联性。该设计依赖于路径预测来提供较低的命中延迟。在访问时,内存控制器读取集合中所有标签,并仅从预测的路径加载数据。数据加载是预取的。在命中并且路径预测正确的情况下,延迟大致相当于一次 DRAM 访问,因为预取的数据和标签访问一起返回。然后,标签会与更新后的 LRU 位一起存回内包 DRAM。对于未命中的情况,由于额外的片外 DRAM 访问,延迟会翻倍。在缓存未命中的带宽消耗方面,Unison Cache 1)加载预测路径中的标签和数据,2)进行缓存替换,将预测的页面足迹加载到片上 DRAM 中,3)将更新后的标签和 LRU 位存回 DRAM 缓存。如果页面足迹较大,缓存未命中和替换时的带宽消耗可能是缓存命中时的几十倍。
HybridCache不清楚是不是指的是论文中出现的HMA,如果是的话:
采用基于软件的解决方案来处理这些问题。操作系统(OS)定期对所有页面进行排名,并将热页面移入内包 DRAM(冷页面移出)。操作系统更新所有页表项(PTE),刷新所有 TLB 以保持一致性,并从所有片上缓存中刷新重新映射物理页面的缓存行以确保地址一致性。由于这个过程的高性能开销,重新映射只能以非常粗粒度(例如,100 毫秒到 1 秒)进行,以便摊销开销。因此,DRAM 缓存替换策略可能无法充分捕获应用程序中的时间局部性。此外,当页面在内包和外包 DRAM 之间移动时,系统中所有正在运行的程序都必须停止,这会导致不希望出现的性能下降。
NoCacheTagless:也采用地址重映射,但通过硬件管理的 TLB 一致性机制实现了频繁的缓存替换。具体来说,TDC 在主存中维护一个 TLB 目录结构,并在每次条目被插入或从系统中的任何 TLB 中移除时更新该目录。这种细粒度的 TLB 一致性带来了额外的设计复杂性。此外,随着核心数量的增加,目录的存储成本可能成为潜在的可扩展性瓶颈。TDC 没有讨论地址一致性问题,因此不清楚 TDC 是否采用了某种解决方案来解决地址一致性问题,或者是否存在这种解决方案。
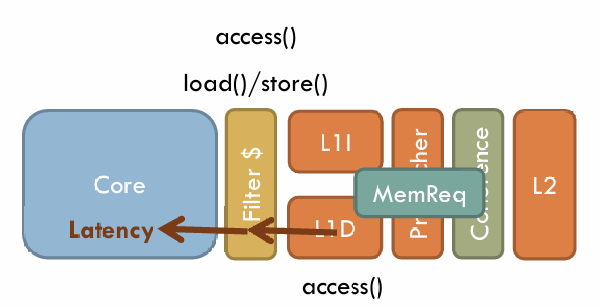
MemReq
memory_hierarchy.h
MemReq 结构体表示一个内存请求,它包含了请求的地址、访问类型、MESI 状态、请求到达的周期、同步锁等信息。标志位用于标记请求的特殊行为,例如指令获取、预取、写回等。通过这些信息,系统能够管理内存访问、同步、缓存一致性等任务。
/* Memory request */struct MemReq { Address lineAddr; AccessType type; uint32_t childId; MESIState* state; uint64_t cycle; //cycle where request arrives at component
//Used for race detection/sync lock_t* childLock; MESIState initialState;
//Requester id --- used for contention simulation uint32_t srcId;
//Flags propagate across levels, though not to evictions //Some other things that can be indicated here: Demand vs prefetch accesses, TLB accesses, etc. enum Flag { IFETCH = (1<<1), //For instruction fetches. Purely informative for now, does not imply NOEXCL (but ifetches should be marked NOEXCL) NOEXCL = (1<<2), //Do not give back E on a GETS request (turns MESI protocol into MSI for this line). Used on e.g., ifetches and NUCA. NONINCLWB = (1<<3), //This is a non-inclusive writeback. Do not assume that the line was in the lower level. Used on NUCA (BankDir). PUTX_KEEPEXCL = (1<<4), //Non-relinquishing PUTX. On a PUTX, maintain the requestor's E state instead of removing the sharer (i.e., this is a pure writeback) PREFETCH = (1<<5), //Prefetch GETS access. Only set at level where prefetch is issued; handled early in MESICC }; uint32_t flags;
inline void set(Flag f) {flags |= f;} inline bool is (Flag f) const {return flags & f;}};主要字段解释
地址 (
lineAddr):lineAddr存储了与该内存请求相关的内存地址(通常是缓存行地址)。这通常是一个表示地址的类型(如uint64_t)。该地址用于标识请求操作的缓存行或内存块。
访问类型 (
type):type是一个枚举类型,表示内存请求的类型(比如读取、写入等)。具体的类型定义在AccessType枚举中(该部分代码未显示)。常见的类型有READ、WRITE或者特定的访问类型(如IFETCH用于指令获取)。
子请求 ID (
childId):childId用于标识子请求的 ID。这个字段可能与事务或内存操作的级别相关,帮助追踪请求的源头。
MESI 状态 (
state):state指向一个MESIState对象,该对象表示内存请求时该缓存行的 MESI 状态。MESI 协议用于跟踪缓存行在多个缓存之间的状态,确保数据一致性。
请求到达周期 (
cycle):cycle表示请求到达组件的周期,通常用于模拟时间和延迟,确保在正确的时钟周期进行内存操作。
子锁 (
childLock):这个字段用于同步或竞争检测。它是一个锁指针,用于防止不同组件或处理器间的竞态条件,确保内存请求的正确同步。
初始状态 (
initialState):initialState存储请求发起时缓存行的初始 MESI 状态。这个状态在处理过程中用于检测是否发生了状态变化。
请求源 ID (
srcId):srcId表示发起请求的源的 ID,用于模拟请求的来源,通常用于处理内存访问争用或追踪访问源。
标志位 (flags)
flags 字段使用了一组标志位,表示不同的内存请求特征,这些标志在内存请求传播或缓存一致性处理过程中起到了重要作用。以下是各个标志位的作用:
IFETCH:表示这是一次指令获取操作。通常用于指令读取,主要用于区分与数据访问的请求。该标志用于表示这是一次纯粹的指令请求,但不会影响缓存一致性协议中的排他性(
NOEXCL)。
NOEXCL:表示在进行
GETS请求时,不需要返回排他(Exclusive)状态,即缓存一致性协议在这一请求中变为 MSI(Modified, Shared, Invalid)协议,而不是标准的 MESI 协议。
NONINCLWB:表示这是一次非包含性写回。该请求不会假定目标缓存行已经在较低层次的缓存中,常见于某些非统一缓存架构(如 NUCA)。
PUTX_KEEPEXCL:用于 PUTX 请求时,保持请求源的排他性状态(E),而不是移除共享者。用于写回操作,确保在写回时不会影响该缓存行的排他状态。
PREFETCH:表示这是一次预取请求。预取请求在处理时通常与正常的内存访问有所不同,可能不需要参与完整的缓存一致性协议。
内联函数
set(Flag f):将特定的标志位设置为 1。用于在请求中标记特定的操作类型。is(Flag f):检查是否设置了特定的标志位。如果标志位已设置,返回true。
InvReq
x
/* Invalidation/downgrade request */struct InvReq { Address lineAddr; InvType type; // NOTE: writeback should start false, children pull it up to true bool* writeback; uint64_t cycle; uint32_t srcId;};
其它
xxxxxxxxxxtypedef enum { // 获取缓存行的副本,不需要独占权限(例如处理器进行加载操作)。这个请求通常表示从缓存中读取数据,且允许多个处理器共享这个缓存行。不会要求排他性(Exclusive)权限。 GETS, // 获取缓存行并且需要独占权限(例如处理器进行存储或原子操作)。这个请求通常表示一个处理器需要对缓存行进行写入,并要求其他处理器无法访问这个缓存行的副本,因此需要独占权限。 GETX, // 写回操作,表示将缓存行从缓存中“清洁”地写回到更低层次的缓存,且该缓存行未被修改(没有脏数据)。这个操作通常发生在较低层次的缓存(例如 L2 或 L3)将缓存行从其缓存中逐出时。 PUTS, // 写回操作,表示将缓存行从缓存中“脏”地写回到更低层次的缓存,且该缓存行已经被修改(有脏数据)。这种操作通常用于将修改过的数据写回到较低层次的缓存,或者当缓存行被逐出时。 PUTX } AccessType;
/* Types of Invalidation. An Invalidation is a request issued from upper to lower * levels of the hierarchy. */typedef enum { // 完全失效该缓存行。即使该缓存行在较低层次的缓存中被共享,也会使其无效,并要求缓存行被删除。 INV, // 失效该缓存行的独占访问权限(即失效排他性)。这个请求允许较低层次的缓存保留一个非独占的副本,但失效该缓存行的排他性状态。通常用于使其他处理器能够访问该缓存行,但失效该行的排他访问权限。 INVX, // 不失效该缓存行,而是仅将数据发送给上层请求者。这个操作通常在目录(如目录缓存)中使用。它仅适用于缓存行处于共享(S)状态的情况下,且不会导致缓存行被失效。 FWD, } InvType;
/* Coherence states for the MESI protocol */typedef enum { I, // invalid 缓存行处于失效状态,意味着该缓存行不包含有效的数据,缓存行可以被其他处理器访问或加载数据。 S, // shared (and clean) 缓存行处于共享状态,表示该缓存行可以被多个处理器共享且没有被修改。该行的副本存在于多个缓存中,且所有缓存行都是只读的 E, // exclusive and clean 缓存行处于独占状态,意味着该缓存行仅存在于当前缓存中且未被修改。当前缓存是该缓存行的唯一副本,并且数据可以被修改(写入) M // exclusive and dirty 缓存行处于脏状态,意味着缓存行的副本是唯一的且已被修改。该缓存行包含的数据已被修改,且它未被写回到主内存中} MESIState;说白了就是GETS适合读,GETX适合写,PUTS适合处理干净数据,PUTX适合处理脏数据(写回)
MemoryController —— Access
根据上面的PPT和代码的意思,Access函数返回的是一个latency。篇幅有限,不贴所有代码。
x
switch (req.type) { case PUTS: case PUTX: *req.state = I; break; case GETS: *req.state = req.is(MemReq::NOEXCL)? S : E; break; case GETX: *req.state = M; break; default: panic("!?"); }这是banshee MemoryController::Access中的第一段代码,也在mem_ctrl.cpp中出现。说白了就是根据请求类型,修改MESI状态。
对于
PUTS和PUTX请求,缓存将该行的状态设置为I(Invalid,失效)。解释:
PUTS和PUTX都是写回操作,通常表示缓存行要被逐出并写回到更低层的缓存或内存中。因此,这里将缓存行的状态设置为I表示失效,意味着当前缓存不再持有该行的数据,也不允许访问。对于
GETS请求,代码检查是否请求了非独占权限 (req.is(MemReq::NOEXCL))。如果是非独占请求,缓存行状态设置为
S(Shared,共享),表示该行可以被多个缓存共享。否则,将状态设置为
E(Exclusive,独占),表示该缓存是唯一持有该行的缓存,并且缓存行未被修改。
解释:
GETS请求通常用于读取数据。如果请求不需要独占权限(即其他缓存可以共享),则状态设置为S;如果需要独占访问权限(即不允许其他缓存共享),则状态设置为E。对于
GETX请求,缓存行状态设置为M(Modified,独占且脏)。解释:
GETX请求通常表示写操作,缓存行需要独占访问并可能会被修改。因此将状态设置为M,表示该缓存行是唯一的副本且已被修改。
x
if (_scheme == NoCache) { /////// load from external dram req.cycle = _ext_dram->access(req, 0, 4); _numLoadHit.inc(); futex_unlock(&_lock); return req.cycle; //////////////////////////////////// } 这段代码的意思是现在启用的模式没有DRAM Cache,因此访问直接去ext_dram
单纯点进access的话会遇到纯虚函数和其重载版本的虚函数
virtual uint64_t access(MemReq& req) = 0;virtual uint64_t access(MemReq& req, int type, uint32_t data_size) { assert(false); }; // return access(req); };
assert(false);的用意可能是提醒开发者,应该使用其他实现版本,或在子类中重载这个版本的access函数以实现特定行为。
这种设计意图上可能是将 access 的大多数实现都集中在第一个函数 access(MemReq& req) 中,避免子类中重载 access(MemReq& req, int type, uint32_t data_size) 带来的复杂性。具体来说:
如果子类只需基本的内存访问,不涉及类型或数据大小的复杂逻辑,它只需实现第一个函数。
如果子类需要用到
type和data_size参数,它可以重载第二个函数来处理这些参数。
因此如前面所述,不管是ext_dram还是mc_dram都是DDR,所以实际调用的access是ddr_mem.cpp里的DDRMemory::access,这部分代码将在稍后介绍。
上述的代码还出现了futex_unlock(&_lock),这与access最开始的futex_lock(&_lock)配对。除了PUTS这种干净数据写回操作之外,都需要这个互斥锁进行保护。关于互斥锁及其相关的并发控制问题请参见我在USENIX Security关于GhostRace的博客(ghostrace)。
注意:ZSim这里的互斥锁是不公平的!如果Design需要一个(相对)公平的锁,需要谨慎使用futex_lock
以上述代码为例:
在
_scheme == NoCache的条件下,req.cycle会通过调用外部 DRAM 的access函数来处理。锁保证只有一个线程能够在某一时刻访问ext_dram,从而避免竞争。
其它代码也是相似的,由于ZSim应该是支持多线程的,因此实现正确的并发控制是需要的,这与gem5 SE模式的内存控制不同。
接下来回过去看看DDRMemory::access
/* Bound phase interface */// data_size is the number of burstsuint64_t DDRMemory::access(MemReq& req, int type, uint32_t data_size) { switch (req.type) { case PUTS: case PUTX: *req.state = I; break; case GETS: *req.state = req.is(MemReq::NOEXCL)? S : E; break; case GETX: *req.state = M; break;
default: panic("!?"); } assert(data_size % 2 == 0); if (req.type == PUTS) { return req.cycle; //must return an absolute value, 0 latency } else { bool isWrite = (req.type == PUTX); // TODO If length > 1 cacheline, add 4 cycle for each cacheline uint64_t respCycle = req.cycle + (isWrite? minWrLatency : minRdLatency) + memToSysCycle(data_size - 1); if (zinfo->eventRecorders[req.srcId]) { // accessing multiple lines is modeled as multiple requests. // All the requests can be processed in parallel. // DDRMemoryAccEvent* memEv = new (zinfo->eventRecorders[req.srcId]) DDRMemoryAccEvent(this, isWrite, req.lineAddr, data_size, domain, preDelay, isWrite? postDelayWr : postDelayRd); if (type == 0) // default. The only record. { memEv->setMinStartCycle(req.cycle); TimingRecord tr = {req.lineAddr, req.cycle, respCycle, req.type, memEv, memEv}; assert(!zinfo->eventRecorders[req.srcId]->hasRecord()); zinfo->eventRecorders[req.srcId]->pushRecord(tr); } else if (type == 1) { // append the current event to the end of the previous one TimingRecord tr = zinfo->eventRecorders[req.srcId]->popRecord(); memEv->setMinStartCycle(tr.reqCycle); assert(tr.endEvent); tr.endEvent->addChild(memEv, zinfo->eventRecorders[req.srcId]); // XXX when to update respCycle //tr.respCycle = respCycle; tr.type = req.type; tr.endEvent = memEv; zinfo->eventRecorders[req.srcId]->pushRecord(tr); } else if (type == 2) { // append the current event to the end of the previous one // but the current event is not on the critical path TimingRecord tr = zinfo->eventRecorders[req.srcId]->popRecord(); memEv->setMinStartCycle(tr.reqCycle); assert(tr.endEvent); tr.endEvent->addChild(memEv, zinfo->eventRecorders[req.srcId]); //tr.respCycle = respCycle; tr.type = req.type; zinfo->eventRecorders[req.srcId]->pushRecord(tr); } } //info("Access to %lx at %ld, %ld latency", req.lineAddr, req.cycle, minLatency); return respCycle; }}这段代码实现了 DDRMemory::access 函数,用于模拟 DDR 内存访问的延迟和事件记录。这段代码还没有实现大于一个cacheline大小时需要增加额外的延迟。代码的主要流程如下:
(1)设置一致性状态
在执行内存访问前,代码会根据请求类型 (req.type) 更新缓存一致性状态:(这与先前提到的一致)
PUTS和PUTX请求会将缓存行状态设置为失效 (I),表示缓存行不再有效。GETS请求会根据MemReq::NOEXCL标志来决定设置为共享 (S) 还是独占 (E) 状态。GETX请求会将缓存行状态设置为修改 (M) 状态。
(2)计算响应周期 (respCycle)
对于写回请求 (PUTS),函数直接返回当前周期 req.cycle,即零延迟。对于其他请求,函数基于以下逻辑计算 respCycle:
请求类型为
PUTX时,将其视为写请求,否则视为读请求。延迟的基础为写入最小延迟 (
minWrLatency) 或读取最小延迟 (minRdLatency),再加上额外的memToSysCycle(data_size - 1)的延迟。这里的
memToSysCycle(data_size - 1)是基于data_size(表示突发数)的系统延迟转换。
(3)事件记录
如果在 zinfo->eventRecorders[req.srcId] 中存在事件记录器(即启用了事件跟踪),会记录该请求的详细访问信息。事件记录的逻辑根据 type 的不同而有所变化:
type == 0:创建DDRMemoryAccEvent事件,记录访问开始的最小周期 (req.cycle) 及请求信息,并将其记录为独立事件。type == 1:将当前事件附加在上一个事件的末尾,并设置当前事件的开始周期为上一个事件的请求周期,形成依赖链。type == 2:将当前事件附加到上一个事件的末尾,但不属于关键路径。
(4)返回响应周期
在所有操作完成后,函数返回 respCycle,即请求的响应时间。
Note:
data_size为突发传输的数量。
回到banshee的access代码
ReqType type = (req.type == GETS || req.type == GETX)? LOAD : STORE; Address address = req.lineAddr; uint32_t mcdram_select = (address / 64) % _mcdram_per_mc; Address mc_address = (address / 64 / _mcdram_per_mc * 64) | (address % 64); //printf("address=%ld, _mcdram_per_mc=%d, mc_address=%ld\n", address, _mcdram_per_mc, mc_address); Address tag = address / (_granularity / 64); uint64_t set_num = tag % _num_sets; uint32_t hit_way = _num_ways; //uint64_t orig_cycle = req.cycle; uint64_t data_ready_cycle = req.cycle; MESIState state;这段代码主要实现了一种基于地址映射的内存访问管理。它确定请求的类型(加载或存储)、地址的分布、行缓存映射等信息,具体如下:
确定请求类型 (ReqType type)
ReqType type = (req.type == GETS || req.type == GETX) ? LOAD : STORE;根据请求类型,将其归类为
LOAD或STORE。如果请求类型为
GETS(获取共享)或GETX(获取独占),则类型为 (LOAD);否则为 (STORE)。
地址与 MCDRAM 通道选择
Address address = req.lineAddr;uint32_t mcdram_select = (address / 64) % _mcdram_per_mc;address是请求的(cacheline)行地址(req.lineAddr)。mcdram_select表示选择哪个 MCDRAM 通道。它通过计算地址除以 64 字节(通常是一个 cache line 大小),再对 MCDRAM 通道总数_mcdram_per_mc取模,来决定当前请求的内存通道。
计算 MCDRAM 物理地址 (mc_address)
x
Address mc_address = (address / 64 / _mcdram_per_mc * 64) | (address % 64);mc_address表示将请求分配给指定通道后的 MCDRAM 地址。地址计算通过
(address / 64 / _mcdram_per_mc * 64)部分完成,它将地址除以缓存行大小和通道数,得到每个通道的基础地址,再保留地址内的偏移量(address % 64)。这样,
mc_address保证地址的低位 64 字节对齐,同时在不同 MCDRAM 通道上分散地址。
如果是顺序访问的话,基本上能够在所有通道上均匀分布,否则如果是跨步式访问(按照通道数跨步的话),会使得请求在一个通道上集中,带来排队延迟(这部分模拟器是有可能模拟出来的吗?不确定。)
计算 Cache 组 (set) 和标签 (tag)
x
Address tag = address / (_granularity / 64);uint64_t set_num = tag % _num_sets;tag是基于指定粒度_granularity计算的地址标签,用于表示缓存行的唯一标识符。_granularity是一个表示内存或缓存系统中数据分配或访问单位大小的参数,具体意义取决于上下文。它可以是以下几种之一:缓存块的大小(例如,4KB 的缓存块)。
内存页面的大小(例如,操作系统中的内存页面通常是 4KB、2MB 或更大)。
存储块的大小。
在这段代码中,我们假设
_granularity表示的是更大的内存块的大小,例如一个 页面 的大小,或者某种大内存区域的单位。举例来说,假设_granularity的值为 4096 字节(即 4KB,通常是内存页面的大小)。address是指内存中的某个地址,你希望访问或操作的内存位置。为什么用
address / (_granularity / 64)?缓存系统中的内存地址是按照缓存行(cache line)来管理的,通常一个缓存行的大小为 64 字节。在计算机系统中,内存是按这些 64 字节的单位进行读取和写入的。
_granularity / 64的作用是:将更大的内存单位(例如页面大小或存储块)映射到缓存行级别。
进行缩放,将较大的单位划分成 64 字节为基础的小单元。
将
address / (_granularity / 64)作为计算tag的方法,实际上是 将内存地址映射到某个更大的块或页面,并将该块划分为若干个 64 字节的缓存行。计算出来的tag实际上是在缓存行级别的映射。这个过程并不直接与操作系统中的页面大小等价,但它有助于在缓存系统中定位和管理数据块。
set_num是缓存集合索引,用于确定该地址应映射到哪个缓存组(_num_sets表示缓存集合的总数)。
老实说,我没理解这里为什么不是Address tag = address / 64 / (_granularity / 64);
设置默认变量
xxxxxxxxxxuint32_t hit_way = _num_ways;uint64_t data_ready_cycle = req.cycle;MESIState state;hit_way设为_num_ways,代表初始状态下未找到匹配的缓存位置。data_ready_cycle初始化为请求的当前周期 (req.cycle),表示数据准备好时的周期。state用于存储缓存行的缓存一致性协议状态(MESI),表示缓存行是处于 Modified、Exclusive、Shared 还是 Invalid 状态。
xxxxxxxxxx if (_scheme == CacheOnly) { /////// load from mcdram req.lineAddr = mc_address; req.cycle = _mcdram[mcdram_select]->access(req, 0, 4); req.lineAddr = address; _numLoadHit.inc(); futex_unlock(&_lock); return req.cycle; //////////////////////////////////// }enum Scheme{ AlloyCache, UnisonCache, HMA, HybridCache, NoCache, CacheOnly, Tagless};Scheme的模式有哪些,可以参见论文6.1.1节(但似乎也不全)
根据论文描述:CacheOnly模式只有片内DRAM,且容量无限大。
这段代码的意思是,如果是CacheOnly模式的话,就会根据请求计算得到的通道内对齐地址和通道,计算访问对应通道对应地址的时延并返回。需要注意的是,这里请求的lineAddr需要复原成原来的address(毕竟是引用类型,别的地方可能也会用得到,同时需要加互斥锁保护起来)。对于状态位改变。
xxxxxxxxxx uint64_t step_length = _cache_size / 64 / 10;
// whether needs to probe tag for HybridCache. // need to do so for LLC dirty eviction and if the page is not in TB bool hybrid_tag_probe = false; if (_granularity >= 4096) { if (_tlb.find(tag) == _tlb.end()) _tlb[tag] = TLBEntry {tag, _num_ways, 0, 0, 0}; if (_tlb[tag].way != _num_ways) { hit_way = _tlb[tag].way; assert(_cache[set_num].ways[hit_way].valid && _cache[set_num].ways[hit_way].tag == tag); } else if (_scheme != Tagless) { // for Tagless, this assertion takes too much time. for (uint32_t i = 0; i < _num_ways; i ++) assert(_cache[set_num].ways[i].tag != tag || !_cache[set_num].ways[i].valid); }
if (_scheme == UnisonCache) { //// Tag and data access. For simplicity, use a single access. if (type == LOAD) { req.lineAddr = mc_address; //transMCAddressPage(set_num, 0); //mc_address; req.cycle = _mcdram[mcdram_select]->access(req, 0, 6); _mc_bw_per_step += 6; _numTagLoad.inc(); req.lineAddr = address; } else { assert(type == STORE); MemReq tag_probe = {mc_address, GETS, req.childId, &state, req.cycle, req.childLock, req.initialState, req.srcId, req.flags}; req.cycle = _mcdram[mcdram_select]->access(tag_probe, 0, 2); _mc_bw_per_step += 2; _numTagLoad.inc(); } /////////////////////////////// } if (_scheme == HybridCache && type == STORE) { if (_tag_buffer->existInTB(tag) == _tag_buffer->getNumWays() && set_num >= _ds_index) { _numTBDirtyMiss.inc(); if (!_sram_tag) hybrid_tag_probe = true; } else _numTBDirtyHit.inc(); } if (_scheme == HybridCache && _sram_tag) req.cycle += _llc_latency; }最开始的那一段蛮简单的,就是看看tag(对应的大块或者说Segment吧)有没有在TLB里,没有的话就加上去。加完后不管怎么样都有了。
接下来就是命中检查,之前的hit_way初始化为_num_ways,而合法的(命中过)取值为0 - _num_ways-1。因此如果_tlb[tag].way != _num_ways即表示TLB命中的话,hit_way就会更新为_tlb[tag].way并检查缓存中的有效性和标签匹配。
对于 非 Tagless 模式,它会遍历 set_num 的所有 ways,确保不存在重复的有效标签。Tagless 模式下省略这一检查,可能是为了减少计算开销。
UnisonCache 模式处理
分成 LOAD 和 STORE 两种操作,两种操作存在较大差异。
首先就是访问时候突发传输的次数,在banshee的代码中,UnisonCache LOAD时access(req, 0, 6),STORE时access(tag_probe, 0, 2),一个是6一个是2。为什么是2下面有解释,但为什么是6,这个不太清楚。其他方面,LOAD和前面CacheOnly差不多,但是多了一个状态的改变:
if (type == LOAD) { req.lineAddr = mc_address; //transMCAddressPage(set_num, 0); //mc_address; req.cycle = _mcdram[mcdram_select]->access(req, 0, 6); _mc_bw_per_step += 6; _numTagLoad.inc(); req.lineAddr = address; }STORE就完全是另一个东西了
x
else { assert(type == STORE); MemReq tag_probe = {mc_address, GETS, req.childId, &state, req.cycle, req.childLock, req.initialState, req.srcId, req.flags}; req.cycle = _mcdram[mcdram_select]->access(tag_probe, 0, 2); _mc_bw_per_step += 2; _numTagLoad.inc(); }为什么会出现这个差异,这涉及到缓存写回的策略。Cache的结构中,标签和数据块是分离的。标签用于识别缓存中存储的数据地址,数据块则是实际的数据内容。当一个STORE操作发生时,如果缓存采用写回(Write-Back)策略,数据的写入通常会首先只在缓存中进行,而不会立即写回到片上内存或主内存。因此,只有在数据块被驱逐(Evict)出缓存时,才需要更新片上内存或主内存中的数据。
当有STORE请求时,数据直接写入缓存,并且将该缓存行标记为“脏”(Dirty),表示数据已经被修改,但还没有写回片上内存。在数据块被驱逐之前,缓存只需要更新标签状态,不需要立即写入数据内容。因此,这时标签探测即可满足需求,而不需要耗费带宽去执行完整的写入操作。只有当数据块被替换时,缓存才会将“脏”数据块写回片上内存或主内存。
标签探测的目的是确认缓存中是否存在该地址的数据块,或者更新其状态。标签探测过程中,只需检查或更新标签相关的信息,而不涉及实际的数据传输。因此,标签探测操作的带宽消耗较低,也无需进行大规模的突发传输。这正是为什么在STORE操作中,我们只需消耗2个突发传输的原因