GhostRace [USENIX Security'24]
[Title] GhostRace: Exploiting and Mitigating Speculative Race Conditions
[By the way] 顺便回顾一下操作系统的并发控制
Abstract
当多个线程试图在没有适当同步的情况下访问共享资源时,就会出现竞争条件,经常导致concurrent use-after-free等漏洞。为了减少它们的发生,操作系统依赖于同步原语,如互调器、自旋锁等。
在本文中,我们介绍了 GhostRace,这是对推测执行代码路径上的这些同步原语进行的首次安全分析。我们的主要发现是,所有常见的同步原语都可以在投机路径上被微体系结构绕过,从而将所有体系结构上race-free的临界区域变成投机race conditions(SRC)。为了研究SRC的严重性,本文重点研究了SCUAF(Speculative Concurrent Use-After-Free),并在Linux内核中发现了1,283个可能被利用的gadgets。此外,本文还证明了针对内核的 SCUAF 针对内核的信息泄露攻击不仅实用,而且其可靠性可与传统的 Spectre (幽灵)攻击相媲美,我们的概念验证以 12 KB/s 的速度泄露内核内存。最重要的是,本文开发了一种创建无限制race-window的新技术,可在单个race window中容纳端到端攻击所需的任意数量的 SCUAF 调用。为了应对新的攻击面,我们还提出了一种通用的 SRC 缓解方法,以强化 Linux 上所有受影响的同步原语。
Concurrency Review
为了应对并发程序在临界资源可能导致的并发bug,有许多的并发控制手段被采用,比如同步原语中的互斥锁和自旋锁等等。
互斥:Stop the world 消灭并发
自旋
x/*Author:jyy 自旋 示意*/void spin_lock(lock_t *lk) {retry: int got = atomic_xchg(&lk->status, ❌); if (got != ✅) { goto retry; }}
void spin_unlock(lock_t *lk) { atomic_xchg(&lk->status, ✅);}lock/unlock 并没有stop the world
只是同一把锁保护的代码被串行化了
例子:线程T2和T1仍然有数据竞争data race.相当于线程T2忘记上锁。
xxxxxxxxxxT1: spin_lock(&lk); sum++; spin_unlock(&lk);T2: sum++;
仅仅自旋就能正确实现互斥?但注意还有中断!
中断可以理解为一根线,CPU接收到这根线的高电平信号,就会进行中断处理(前提是中断打开)
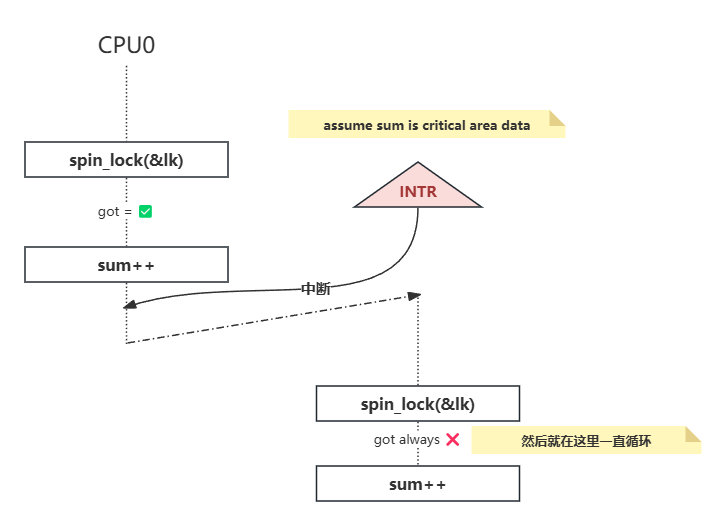
操作系统内核中的自旋锁不仅要实现处理器间的互斥,还要正确处理中断,以及锁的嵌套。当多个需求叠加时,作出一个正确的实现就不再显然
用自旋锁实现 sum++:更多的处理器,更差的性能
使用场景:操作系统内核的并发数据结构 (短临界区) 临界区几乎不 “拥堵”,迅速结束
应用程序自旋的后果
性能问题 (1)
除了进入临界区的线程,其他处理器上的线程都在空转
争抢锁的处理器越多,利用率越低
如果临界区较长,不如把处理器让给其他线程
性能问题 (2)
应用程序不能关中断……
持有自旋锁的线程被切换
导致 100% 的资源浪费
(如果应用程序能 “告诉” 操作系统就好了)
互斥锁
应用程序实现互斥
把锁的实现放到操作系统里就好啦(利用系统调用)
xxxxxxxxxxsyscall(SYSCALL_lock, &lk);试图获得
lk,但如果失败,就切换到其他线程
xxxxxxxxxxsyscall(SYSCALL_unlock, &lk);释放
lk,如果有等待锁的线程就唤醒
使用互斥锁实现同步:我们可以让每一个等待同步的线程都首先试图获取一把 “绝对不可能得到” 的锁——它们会等待,然后由后来的同步者释放这把锁。
使用互斥锁实现计算图:通过在一个线程获得互斥锁,在另一个线程释放,我们能实现 “计算图” 的计算。在这里,每条边上的互斥锁充当了一单位的 “许可”,release 和 acquire 形成了代表同步的 happens-before 关系。
同步
同步:在某个时刻,线程 (状态机中的多个执行流) 达成某种一致的状态,进而从而从等待到继续,即为同步。(有点先来先等待的意思)
条件变量
把条件用一个变量来替代
条件不满足时等待,条件满足时唤醒
xxxxxxxxxxmutex_lock(&lk);if (!condition) { cond_wait(&cv, &lk);}// Wait for someone for wake-up.assert(condition);mutex_unlock(&lk);xxxxxxxxxxcond_signal(&cv); // Wake up a (random) threadcond_broadcast(&cv); // Wake up all threads条件变量的正确打开方式
使用 while 循环和 broadcast
总是在唤醒后再次检查同步条件
总是唤醒所有潜在可能被唤醒的人
xxxxxxxxxxmutex_lock(&mutex);while (!COND) { wait(&cv, &mutex);}assert(cond);
...
mutex_unlock(&mutex);生产者-消费者问题:在解决同步问题时,关键在于理解 “同步成功” 的条件是什么。然后各个线程在条件不满足时等待,直到条件满足方可继续。这个思路自然地引出了 “条件变量” 这一同步机制。
并发控制的机制完全是 “后果自负” 的
互斥锁 (lock/unlock) 实现原子性
忘记上锁——原子性违反 (Atomicity Violation, AV)
条件变量/信号量 (wait/signal) 实现先后顺序同步
忘记同步——顺序违反 (Order Violation, OV)
实际上,“原子性” 一直是并发控制的终极目标。对编程者而言,理想情况是一段代码的执行要么看起来在瞬间全部完成,要么好像完全没有执行过。代码中的副作用:共享内存写入、文件系统写入等,则都是实现原子性的障碍。
因为 “原子性” 如此诱人,在计算机硬件/系统层面提供原子性的尝试一直都没有停止过:从数据库事务 (transactions, tx) 到软件和硬件支持的 Transactional Memory (“an idea ahead its time”) 到 Operating System Transactions,直到今天我们依然没有每个程序员都垂手可得的可靠原子性保障。
而保证程序的执行顺序就更困难了。Managed runtime 实现自动内存管理、channel 实现线程间通信等,都是减少程序员犯错的手段。
Introduction
【相关概念:熔断和幽灵】熔断漏洞利用计算机系统乱序执行的方式,结合旁信道攻击原理推测出内核地址内容;幽灵漏洞利用计算机系统预测执行的方式,结合旁信道攻击推测出内核地址内容。旁信道攻击(Side-Channel Attack)是一种基于对加密算法运行时的物理实现特征分析,主要利用加密电子设备在运行过程中的时间消耗、功率消耗或电磁辐射等旁信道信息对加密设备进行攻击,从而获取密钥等保密信息的攻击方式。假设我们的密码是Wyt……,首先以a试探第一位密码,经过时间t1后返回错误,再次以b试探第一位密码,仍然经过时间t1后返回错误,以此类推,逐一试探字母,直到以W试探第一位密码,经过时间t2 (t2 > t1)后返回错误。在比对正确的第一位密码后,继续比对第二位密码错误返回,程序运行时间较长,以此推测出第一位密码是W,依此类推可破解所有的密码。此例中旁信道是验证密码所用时间,时间差暴露了信息正确与否。
自发现 Spectre 以来,安全研究人员一直在争分夺秒地查找受害软件中所有可利用的片段或小工具。
Background
Transient Execution
Transient Execution
涉及到了分支预测和乱序执行的概念
xxxxxxxxxxif(x < array1_size){ y = array2[array1[x]*0x1000];}在给定的代码段中,如果存在一个条件分支,而条件分支的判断依赖于一个尚未从内存加载到缓存的数据(比如 array1_size),处理器可能会进行以下操作:
推测执行:处理器可能会假设条件分支的结果,例如假设
array1_size > x为真或假。启动分支预测和乱序执行:如果处理器预测条件分支为真,它会继续执行条件分支之后的指令,即使条件分支的判断依赖于尚未从内存加载的数据。
后果:如果推测执行和分支预测正确,处理器可以节省等待从内存加载数据的时间,提前执行后续指令,从而加快整体执行速度。但如果预测错误,处理器需要回滚到分支点重新执行,浪费了之前推测执行的计算结果。
当 x 是越界的(可能导致条件分支的结果不确定)且 array1_size 尚未在缓存中可用时,处理器可能会根据历史执行情况和分支预测算法进行推测执行。这种推测执行能力是现代处理器性能优化的一部分,但在攻击者利用这种行为进行侧信道攻击时,可以利用处理器的推测执行特性来获取敏感信息(比如 array1_size)。
Transient Execution这段的攻击原理
分支预测和乱序执行:处理器在执行代码时,根据以往的执行历史和分支预测算法,可能会预测条件
x < array1_size为真或假。如果之前多次执行时x在界内(即x < array1_size),处理器可能会继续推测x依然在界内,即使当前x是越界的。越界访问的推测执行:如果处理器推测
x仍然在界内,它可能会继续执行array1[x]的访问,即使实际上x是越界的。这样会导致对array1的越界访问。缓存的影响:如果
array2的某些部分未被缓存,那么访问这些未缓存的部分可能会导致处理器加载这些数据到缓存中,因为处理器会尝试预取数据以提高效率。侧信道攻击:攻击者利用这些行为进行侧信道攻击。他们可以通过测量从
array2中访问不同位置所需的时间来推断出某个特定字节的值。因为访问缓存中的数据速度通常比从主存中获取数据快,攻击者可以推断出访问速度较快的位置对应的数据被缓存了,从而泄露了array2中特定位置的字节值。
Concurrency Bugs
use-after-free UAF
Use-after-free 并发 bug 是一种常见的内存管理漏洞,出现在程序在释放内存后仍然使用已释放的内存区域。这种漏洞特别容易在并发程序中发生,因为多个线程可能同时操作共享内存区域,导致竞态条件和未定义行为。
Use-after-free 并发 Bug 的原理
内存分配和释放:
程序分配一块内存区域来存储数据。
程序在完成对该内存的使用后,释放该内存区域。
悬挂指针:
释放内存后,指向该内存的指针没有被清除或更新。此时,这些指针成为悬挂指针(Dangling Pointer)。
并发访问:
如果多个线程访问共享内存区域,一个线程可能在释放内存后,另一个线程仍然持有对该内存区域的引用。
这种情况下,使用已释放的内存区域会导致极其严重的未定义行为。
UAF代码示例
xxxxxxxxxx
struct Data { int value;};
// writer 线程分配 Data 对象的内存,将指针赋值给 data_ptr,然后释放内存。void writer(Data*& ptr) { while (true) { ptr = new Data{42}; std::this_thread::sleep_for(std::chrono::milliseconds(100)); delete ptr; ptr = nullptr; std::this_thread::sleep_for(std::chrono::milliseconds(100)); }}
// reader 线程不断检查 data_ptr 是否非空,并打印其中的 value。void reader(Data*& ptr) { while (true) { if (ptr) { std::cout << ptr->value << std::endl; // Use-after-free potential } std::this_thread::sleep_for(std::chrono::milliseconds(50)); }}
// 如果 reader 线程在 writer 线程释放内存后但在指针被清空前访问 data_ptr,则会出现 use-after-free bug。int main() { Data* data_ptr = nullptr; std::thread t1(writer, std::ref(data_ptr)); std::thread t2(reader, std::ref(data_ptr));
t1.join(); t2.join();
return 0;}
Definitions and Thread Model
Definitions
传统的data race需要两个线程访问同一内存位置,其中一个线程执行写操作,而没有同步原语保护共享访问。当data race影响到程序的正确性时,就会被称为race condition。
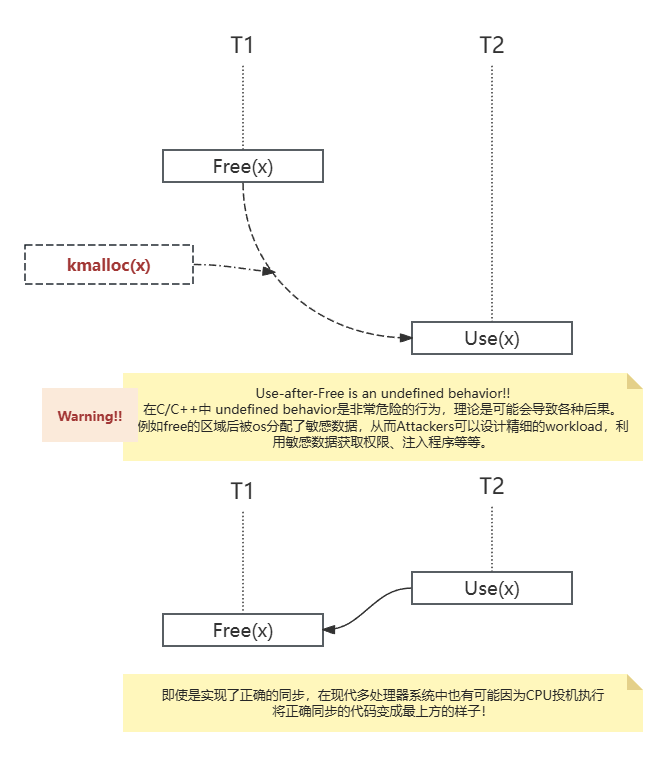
我们的定义是,当两个线程访问同一内存位置时,一个线程执行架构写操作,另一个线程执行瞬时访问,从而对推测执行程序的正确性产生影响,这就是推测竞赛条件(SRC)。
直观地说,由于投机执行,两个线程中的一个可以绕过同步原语,如排他锁。见最上方的use-after-free。
Thread Model
我们考虑了一个典型的跨域 Spectre 威胁模型,即本地无特权攻击者能够向受害内核发出系统调用。攻击者试图利用内核中一个architecture-race-free的关键区域中的推测性race condition,泄漏任意内核数据。我们假设针对瞬时执行攻击的最先进的缓解措施已全部启用,而其他类别(如软件)的漏洞则不在我们的研究范围内--例如,正交缓解措施。此后,在不失一般性的前提下,我们特别关注在英特尔 x86-64 上运行的 Linux 内核。
Architecture-Race-Free 原则
ARF 原则旨在设计和实现能够避免(数据竞争/死锁/饥饿和公平性问题)的并发系统。具体来说,ARF 系统通常具有以下特性:
确定性并发:
系统的行为在给定输入下总是确定的,不会因为线程的调度顺序不同而变化。
确定性并发可以通过严格的同步机制和一致的内存访问模式来实现。
无数据竞争:
确保多个线程不会同时访问和修改同一个共享资源。
可以通过使用互斥锁、读写锁等同步原语来保护共享资源。
死锁预防:
设计系统时避免可能导致死锁的资源分配策略。
例如,采用资源分配图和银行家算法来确保系统始终处于安全状态。
一致性内存模型:
确保所有线程看到的一致性内存视图,不会出现内存可见性问题。
现代处理器和编译器通常提供内存屏障(Memory Barrier)和同步操作来保证内存一致性。
一些代码示例片段
xxxxxxxxxx
int shared_resource = 0;std::mutex mtx;
void increment() { for (int i = 0; i < 1000; ++i) { std::lock_guard<std::mutex> lock(mtx); ++shared_resource; }}
void decrement() { for (int i = 0; i < 1000; ++i) { std::lock_guard<std::mutex> lock(mtx); --shared_resource; }}
int main() { std::thread t1(increment); std::thread t2(decrement);
t1.join(); t2.join();
std::cout << "Final value of shared_resource: " << shared_resource << std::endl;
return 0;}在这个例子中,increment 和 decrement 函数分别增加和减少共享资源 shared_resource 的值。通过使用 std::mutex 和 std::lock_guard,确保对共享资源的访问是互斥的,避免了竞态条件。
std::lock_guard<std::mutex> 是 C++11 引入的一种 RAII(资源获取即初始化)机制,用于管理互斥锁的生命周期。lock_guard 在构造时会自动加锁,在销毁时会自动解锁,这使得锁的管理更加简洁和安全,避免了手动加锁和解锁可能引发的错误。
具体表现和工作原理
加锁和解锁过程
加锁:当一个
std::lock_guard<std::mutex>对象被创建时,它会立即尝试获取并持有传递给它的std::mutex对象的锁。
xxxxxxxxxxstd::lock_guard<std::mutex> lock(mtx); // 加锁解锁:当这个
std::lock_guard<std::mutex>对象超出其作用域时(例如,函数结束,或者在一个代码块结束时),它会自动调用其析构函数,从而释放所持有的锁。
xxxxxxxxxx{ std::lock_guard<std::mutex> lock(mtx); // 代码块内的操作受到锁的保护} // 这里lock超出作用域,自动解锁
GhostRace Attacks