Blenda (MICRO'24)
【Title】Blenda: Dynamically-Reconfigurable Stacked DRAM
Comments
本文在概念上与DAC'23 Bumblebee类似,但本文工作基本在18年结束并挂在Arxiv上,是更早的工作。这就显得很有意思了。。。如果Reviewer看过类似的文章,实际上这篇工作就大概会被挂上“创新型不足”的标签,那大概率也就中不了MICRO了。但话又说回来了,至少背景各方面讲挺好,文章不管从写作再到实践都比Bumblebee好很多(但也没那么好,首先实验环境基于ZSim,是没有操作系统逻辑的,本文是算法是基于排序的,而硬件怎么能处理排序呢???这一部分是涉及到操作系统层面的开销的,而且对于热度的计算,一直以来都是系统层面不断在优化的方向,这边就相当于完全忽略了这部分的开销,这就.....)。本文不一定是个创新性很强的工作,也不一定是实验很可靠的工作,但至少一定是一篇适合刚接触这个领域新手入门必读的工作之一。
老实说看这篇论文之前,我一直以为MICRO会被HPCA难很多,但直接对比TDRAM和Blenda,Blenda还是差了TDRAM一大截。所以MICRO可能也还行??四大会还是ISCA最难。
Abstract
本文提出了Blenda,一种针对千兆级堆叠DRAM的动态分区内存-缓存混合架构。Blenda将堆叠DRAM部分设计为内存,部分设计为缓存,并根据工作负载需求动态调整各部分的大小。内存部分用于存放热数据对象,并高效地处理对这些数据的请求(即无需元数据开销)。缓存部分用于捕获临时数据,并过滤对带宽受限的片外DRAM的请求。Blenda提供了三个关键贡献:
Blenda以工作负载感知的方式分区堆叠DRAM的容量:不同的工作负载享有不同的内存-缓存配置。
Blenda具有反应性:配置会根据工作负载的阶段动态调整,且对应用程序透明,无需重启或用户干预。
Blenda在配置之间优雅过渡:大多数重新配置无需数据失效。我们模拟了15种不同的大数据工作负载在最新处理器上的运行情况,结果表明Blenda比性能最佳的现有架构提升了34%。Blenda的总存储开销每核不到100字节。
Introduction
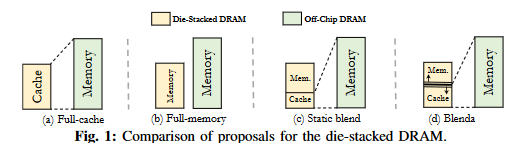
堆叠DRAM(Die-stacked DRAM)已不再只是一个概念:最新的处理器已经集成了数十甚至数百GB的堆叠DRAM。例如,Nvidia H100 [12] 和 Intel Sapphire Rapids [29] 分别配备了80GB和64GB的堆叠DRAM。随着HBM3技术的出现,其带宽显著高于前代技术[20],堆叠DRAM将变得更加普及。最近发布的AMD MI300X [2] 和 NVIDIA Blackwell [11] 都将搭载192GB的HBM3。与传统DDR技术相比,堆叠DRAM在延迟相近的情况下提供了显著更高的带宽(例如4倍)[19], [24], [41], [87]。然而,由于技术限制,其容量仍低于DDR(例如64GB vs. 4TB [6])。为了克服这一限制,大多数学术界和工业界的方案同时使用堆叠DRAM和片外DRAM,堆叠DRAM既可以作为内存端缓存[62], [85], [105], [107],也可以作为主内存的一部分[22], [77], [84],如图1-(a, b)所示。例如,Intel最新的Sapphire Rapids产品包含64GB堆叠DRAM,在启动时可以配置为DDR内存的大型硬件管理L4缓存,或者作为由软件管理的主内存的一部分。
缓存能够快速响应运行时变化:冷数据会被迅速淘汰,而频繁访问的数据会被缓存。然而,DRAM缓存深受元数据(标签)开销的影响。由于其规模在GB级别,DRAM缓存需要MB级别的存储空间来保存标签数组。由于提供如此大的SRAM结构是不现实的,标签通常保存在DRAM本身中[55], [72], [85], [97], [107]。然而,将标签保存在DRAM中会带来显著的延迟/带宽开销;对于每个请求,DRAM需要被访问两次:一次用于标签,一次用于数据。相反,将堆叠DRAM设计为主内存的一部分则消除了缓存的主要缺点:无需标签。然而,与缓存不同,内存无法快速响应数据工作集的运行时变化。最先进的“两级”内存架构[39], [67], [77], [101]通过在堆叠内存和片外内存之间交换页面,将频繁访问的页面保留在高带宽DRAM中。然而,由于页面交换成本极高(需要操作系统干预和TLB失效),它只能在较长的毫秒级周期间隔内执行。因此,短期内被高度利用的数据对象无法被捕获:它们全部由片外内存提供服务,从而压垮了其有限的带宽。
这里提到的“两级”,即Flat模式或称之为Tiering模式
“因此,短期内被高度利用的数据对象无法被捕获:它们全部由片外内存提供服务,从而压垮了其有限的带宽。” 不给参考文献,差评嗷!
本质上,这两种设计都不完美,每种设计根据数据访问的性质提供不同程度的性能表现。例如,稳定使用的数据项更适合内存架构,因为它可以在没有元数据开销的情况下提供数据。相反,临时使用的动态数据更适合缓存架构,它仅在数据被使用时将其保留在容量有限的堆叠DRAM中。在本文中,我们研究了堆叠DRAM级别的数据访问,并观察到在各种大数据工作负载中,存在大量访问频率极高的热页面。基于这一观察,我们将应用程序的数据集分为“热数据集”和“临时数据集”。
“hot datasets” and “transient datasets.”
热数据集(Hot datasets)指的是被应用程序持续使用的数据对象,它们服务于大量的内存访问。临时数据集(Transient datasets)则是在短时间内被高度利用的数据结构。例如,在图分析中,频繁访问的热门顶点[27]可以被视为热数据集;而计算与通信比率较低的顶点[78],其计算是短暂完成的,可以被视为临时数据集。在本研究中,我们提出了Blenda,一种混合内存-缓存架构,以在千兆级堆叠DRAM的背景下利用这种异构性。
Blenda将堆叠DRAM设计为内存-缓存混合架构。内存部分用于存放热数据集,而缓存部分则用于捕获临时数据集。重要的是,与CAMEO [35] 和 CHAMELEON [64] 等先前工作不同,Blenda将(部分)堆叠DRAM用作内存的目的是为了提高性能,而不是增加软件可见的内存容量(参见第VIII节)。Blenda将热页面放入堆叠DRAM的内存部分,并在处理对这些页面的请求时无需支付元数据开销(带宽和/或延迟),而这些开销在全缓存架构中是不可避免的。此外,缓存部分还用于过滤对片外内存的临时数据请求,这些数据无法被内存部分捕获。Blenda的一个重要创新是其基于工作负载感知的动态容量分区。与[102]采用的固定容量分区(图1-(c))不同,Blenda不仅为不同工作负载提供不同的配置,还在运行时动态调整容量分区(图1-(d))。我们观察到,不同工作负载适合不同的容量配置:一些工作负载适合大内存小缓存,而另一些则相反。为此,我们开发了一种新颖的算法来为每个工作负载找到最佳配置,并通过硬件/软件协同的方法动态切换到该配置。
Blenda的另一个重要贡献是实现了配置之间的优雅过渡。任何动态缓存大小调整方法面临的主要挑战是需要频繁且代价高昂的缓存刷新操作[86], [89], [100]。当缓存大小调整时,地址与物理位置之间的映射会发生变化;为了保持一致性,缓存必须被刷新。然而,Blenda采用了一种新颖的重新配置机制,使得地址-位置映射的变化不会引发任何一致性问题。该方案是堆叠DRAM背景下动态缓存大小调整的首个尝试,消除了大多数缓存刷新操作。
总结来说,我们做出了以下贡献:
我们开发了一种新颖的容量分区算法。该算法基于工作负载的数据行为 特征,确定应将多少容量用作内存,多少容量用作缓存,以最大化整体性能。我们证明,在实践中,该算法的分区对大多数工作负载接近最优。
我们提出了一种实用的设计,用于在线实现我们的分区算法,从而将堆叠DRAM设计为一种基于工作负载感知的动态内存-缓存混合架构。在完全对应用程序和用户透明的情况下,堆叠DRAM会根据工作负载的不同(执行阶段)进行重新配置。我们的设计仅需最小的硬件开销:一些用于收集硬件级统计信息(如缓存命中率)的计数器,作为分区算法的输入。
我们提出了优雅过渡的技术,使得大多数重新配置无需任何缓存刷新即可完成。
我们使用基于Intel Sapphire Rapids [29] 建模的处理器运行15种工作负载来评估Blenda。我们将Blenda与八种最先进的学术和工业堆叠DRAM方案进行了比较。结果表明,Blenda在性能上优于最佳的全缓存/全内存设计,分别提升了39.2%和65.8%,同时比最佳的静态内存-缓存混合架构平均提升了34%,最高可达80%。
Background
Cache Architectures
将堆叠DRAM用作缓存(图1-(a))通过将活跃数据集持续保留在高带宽DRAM中来提升性能。然而,如此庞大的缓存需要MB级别的元数据(例如标签、最近使用信息),这些元数据无法全部存储在SRAM中,因此必须保存在DRAM缓存本身。DRAM内元数据的主要问题是引入的延迟和带宽开销:对于每个请求,DRAM缓存需要被访问两次;一次用于标签,另一次用于数据。先前的研究已经广泛解决了这一问题。一些方案[55], [85]通过推测性地同时加载标签和数据来减轻延迟开销。然而,这种方式不仅没有减少带宽开销,而且在推测错误时还会增加开销。另一种方法是将元数据缓存在SRAM中以减轻这两种开销[32], [52]。然而,这种方法不具备可扩展性,仅在DRAM缓存规模为MB级别时实用(参见第VII-G节)。
先前的研究[62], [68], [107]提出了“无标签”(tagless)DRAM缓存,通过以操作系统页(OS page)粒度缓存数据并利用页表(page table)和TLB(Translation Lookaside Buffer)元数据访问数据,以减少标签开销。然而,这些缓存面临一些挑战。由于DRAM写操作(SRAM缓存的脏数据写回)缺乏页表元数据,因此需要通过标签匹配来验证相应页面是否在DRAM缓存中,这导致仍需在DRAM中保留标签,并产生完整的元数据开销。此外,与其他DRAM缓存类似,无标签缓存仍需为每页保留元数据以支持替换策略决策,从而导致类似于标签带宽开销的带宽开销(参见第VII-A1节)。
Memory Architectures
将堆叠DRAM设计为内存(图1-(b))消除了对标签的需求。数据访问高效,无需任何延迟/带宽开销。然而,内存无法持续保留活跃数据集:与缓存不同,内存无法快速淘汰冷数据并用当前使用的数据替换它。先前的研究[82]提出了在运行时将活跃页面迁移到堆叠内存中。然而,这种方法由于频繁的TLB失效而带来显著的开销。当一个页面被迁移时,必须在所有核心之间保持一致性,从而导致TLB失效。迁移的开销可能非常高,以至于超过其带来的收益[77]。
为了减轻这些开销,最先进的内存架构[23], [40], [66], [69], [77], [103], [104]以较长的周期间隔执行页面迁移。这些方法在一个间隔内监控页面访问,并在间隔结束时将热页面迁移到高带宽内存中,将冷页面迁移出去。页面访问通常通过页表1或与页表并行的辅助数据结构[67]进行跟踪。操作系统根据页面的访问次数对其进行排序,并将最热的页面放入堆叠内存中。通过足够长的间隔(100ms − 1s [77])和一次性迁移多个页面,大量的TLB失效开销得以分摊。然而,这些方法无法捕获短期内被高度利用的数据对象(临时数据集),这些数据全部由带宽受限的片外内存提供服务。
Static Memory-Cache Blend Architectures
先前的研究[98], [102]也将堆叠DRAM用作内存-缓存混合架构,但采用的是静态、固定的方式(图1-(c))。我们证明静态分区是次优的(参见第VII-A2节),并提出了一种动态分区的算法和实现机制。
Motivation
Hot Pages Revisited
我们重新审视了堆叠DRAM访问中的“热页面”现象:少数页面服务于大部分内存请求。图2展示了我们工作负载中内存访问的累积分布函数(CDF),以内存占用比例表示(参见第VI节)。CDF向左倾斜揭示了热页面的存在。例如,在pr中,仅10%的页面服务于92%的请求。该图进一步揭示了许多临时页面的存在。同样在pr中,剩余的8%访问分布在90%的页面中,且访问次数相似(即没有页面明显比其他页面更热;CDF呈线性而非倾斜)。
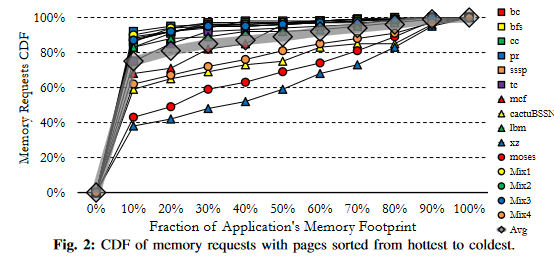
热页面现象还是很容易看出的,临时页面也没这么显然吧?
临时页面应该是短时间被大量访问,随后就不会被访问的页面。按这个图说的“剩余的8%访问分布在90%的页面中,且访问次数相似”,实际上就指的是冷页面了。。。这感觉就把概念换了一下,以突出cache的重要性。。。按理来说,临时页面和冷页面是不等价的。顶多有一定的不能量化的关联性。
Memory VS Cache
如果目标是将堆叠DRAM用作内存,最好的方法是从一开始就将最热的页面放入其中。图3显示了使用4GB堆叠内存时,片外请求的数量与4GB基于页面的缓存[56]的对比结果。我们遍历内存访问轨迹,找到最热的页面并将其分配到堆叠内存中。结果表明,与将堆叠DRAM用作缓存相比,将其全部容量用作内存会使片外请求增加十倍以上。原因是堆叠内存无法捕获临时数据,且容量不足以分配整个数据集。

原图就1/2栏,放大就糊了
这一段没什么篇幅,结论确实比较显然。
Memory-Cache Blend
尽管全内存架构无法像全缓存架构那样有效过滤片外请求,但热页面的存在促使我们找到它们,并将部分堆叠DRAM用作内存来存放这些页面。这样,许多请求将由高带宽DRAM提供服务,而无需支付标签的延迟/带宽开销。如前所述,内存架构的缺点是无法快速响应运行时的变化。随着时间的推移,许多临时数据对象会出现,但由于未分配到堆叠内存中,它们将由片外内存提供服务。
这导致内存架构的命中率比缓存低一个数量级(片外访问更多)。因此,如果混合内存-缓存设计能够提供与全缓存相似的整体命中率,它将不会失去任何优势。为了确定在不损失缓存优势的情况下,可以将多少堆叠DRAM转换为内存,我们将堆叠DRAM视为一组“Frames”。每frame是一个物理位置,可以存放页面粒度的数据,无论DRAM是缓存还是内存。我们首先将堆叠DRAM视为一个大缓存,并计算每帧的平均命中数(AHF)。AHF是每个帧在特定工作负载下预期提供的命中次数的线索。然后,我们将每帧转换为内存,并将最热的未分配页面分配给它,直到AHF小于缓存的AHF。通过这种方式,我们确保混合架构提供与缓存一样高的命中率;同时,由于尽可能多的帧被转换为内存,它最大限度地享受了内存的优势(即无元数据开销)。算法1总结了这些步骤。
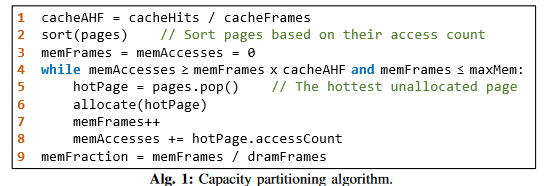
该算法确定了分配给内存的总帧数的比例(第9行)。最初,它假设没有帧专用于内存(第3行)。然后,它逐步增加内存帧的数量(第7行),直到AHF降至低于cacheAHF。在每次迭代中,算法会检查对热页面的访问次数是否足以证明增加另一个内存帧;如果是,则继续处理下一个热页面;如果不是,则停止,因为下一个热页面也无法证明其合理性,因为它们是根据访问次数排序的(第2行)。此检查涉及验证当前内存帧的AHF是否大于cacheAHF(第4行的第一个条件)。如果此条件不满足,则将另一帧专用于内存会导致整体AHF低于cacheAHF。
来了,经典问题:内存控制器硬件怎么完成排序??还是需要软件(操作系统)介入的。
本文的实验基于ZSim,没有OS逻辑的pin-based trace driven的模拟器。排序的OS开销,热度的监测开销(如果不加一层新的抽象)完全无法被ZSim模拟。所以emmm,这就......
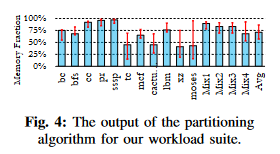
图4中的柱状图显示了该算法对我们工作负载套件的输出结果,基于相同的页面缓存[56]。柱状图上方的区间显示了输出在执行过程中的波动范围。图中显示,堆叠DRAM的很大一部分(平均71.1%)可以作为内存管理,而不会损失缓存优势。此外,图4还显示不同工作负载适合不同的配置。例如,xz的内存比例为41%,而pr的内存比例为96%。这与我们的热页面分析一致。在图2中,CDF也不相同:某些工作负载的CDF更向左倾斜。这是因为热页面的利用率在所有工作负载中并不相似;例如,在xz中,最热的10%页面仅服务于38%的请求,而在pr中,最热的10%页面服务于超过92%的请求。图4还显示,对于tc、xz和moses等工作负载,分区在执行过程中波动很大:并非所有程序阶段都表现出相同的热页面利用率。
Proposal
我感觉Design都不用看了,感觉没什么意思。说了一大堆OS-level的东西,又不是基于Full System Simulator做的实验,实验效果就看看得了。至于动态可变的概念既然Bumblebee已经这样干了,那其实也没有太想深入看的点。无非就是,Bumblebee考虑了HBM高带宽对局部性好的数据更友好,根据局部性和热度动态调整cHBM比例。而本文就是很单纯的觉得有“临时页面”,根据这个来动态调整cHBM的比例。
所以这部分就流水账一下,以后当故事看就行了。实在要看,其实看个流程图也就大概知道了。当然,如果未来需要复现对比实验,那还是需要好好挖掘一下细节的,包括怎么在ZSim里把OS-level的东西抽象进来。
Memory Portion
Blenda的内存部分用于存放热页面。我们使用HMA [77] 来管理它。虽然也提出了其他方法[69], [70], [76], [95], [103],但它们大多针对其他混合内存系统(如DRAM+NVM),并依赖于内存模块之间的延迟差异等因素,这些因素不适用于我们研究的HBM+DDR系统。然而,HMA专门为堆叠DRAM设计,且硬件开销最小,因此更适用于我们的工作。HMA通过页表项(PTE)跟踪页面访问。具体来说,它重新利用了PTE的未使用位(参见第II节)来统计对相应页面的内存访问次数。因此,它扩展了TLB条目以统计对缓存PTE对应页面的请求次数。每次最后一级SRAM缓存(LLSC)未命中时,相应TLB条目的访问计数器会增加,而当条目从TLB中淘汰时,其计数器值会被添加到页表中的PTE计数器中。这一切仅需要极少的片上存储来扩展TLB(几十字节),并对硬件页表遍历逻辑进行最小修改以执行访问计数器的读-改-写操作。
在较长的周期间隔内,HMA使用PTE中的访问计数器来识别热页面。具体来说,在每个间隔结束时,应用程序的执行会被中断暂停:设计时指定的一个内存控制器向所有核心和缓存/内存控制器广播“暂停”消息。核心停止取指令,提交其指令,并向内存控制器发送“完成”消息。缓存控制器和其他内存控制器等待所有挂起操作(例如脏数据写回)完成,并通知发起暂停的内存控制器。随后,操作系统级别的中断处理例程被执行,该例程根据页面的访问次数对其进行排序,并将前N个页面识别为热页面,并将其放入堆叠内存中。3 此过程类似于Intel [5] 和 AMD [80] 处理器中的性能监控中断(PMI)。最后,PTE被更新,计数器被清除,并发出系统范围的TLB失效以保持一致性。
暂停执行,引入中断,Top-K?
Cache Portion
Blenda的缓存部分用于过滤对分配到片外的页面的请求(即未被识别为热页面的页面)。我们评估了三种主要架构来管理缓存部分,分别是基于块的缓存、基于页面的缓存和基于页表(即无标签)的缓存。
基于块的缓存[72], [85]以SRAM缓存的粒度(例如64字节)缓存数据,以优化内存带宽。
基于页面的缓存[55], [56]使用更大的粒度(例如4KB),通过空间局部性提高命中率。
基于页表的缓存[68], [107]将缓存粒度与操作系统页面对齐,通过页表和TLB跟踪页面。
Blenda: αMemory + (1 − α)Cache
Blenda以全缓存模式启动:所有堆叠DRAM帧都专用于缓存部分。随着时间的推移,它逐渐转变为内存-缓存混合模式。在较长的周期间隔内,操作系统运行算法1,对其输出进行四舍五入(如第IV-E节所述),并确定内存和缓存部分的大小。在不失一般性的情况下,我们假设内存是第一部分,缓存是第二部分(如图1-(c, d)所示)。Blenda首先需要了解工作负载从DRAM缓存中受益的程度,即算法1中的cacheAHF。这是一个硬件级别的统计量;为了计算它,我们在内存控制器(MC)中添加硬件计数器,并在缓存命中时增加计数器。在间隔期间,操作系统读取计数器(例如使用内存映射寄存器),并计算cacheAHF。接下来,HMA的操作开始。页面被排序,并选择最热的页面。Blenda与HMA等全内存架构的区别在于,只要整个堆叠DRAM的AHF不小于cacheAHF(算法1第4行的第一个条件),就会执行此操作。也就是说,与内存架构不同,内存架构会将热页面放入堆叠DRAM直到其完全填满,而Blenda则会在整个设计的整体AHF小于全缓存AHF时停止此操作。
在识别热页面并确定缓存和内存帧的数量后,重塑操作(即改变容量分区)开始。为此,首先需要将脏缓存帧写回到片外内存。4 我们称此操作为缓存脏数据清理(CDS)。CDS由内存控制器(MC)执行,可以通过逐一检查缓存帧的元数据(我们的实现)或通过跟踪脏条目并批量写回[92]来加速。随后,操作系统向MC宣布新的分区,并开始在DRAM之间迁移页面。在内存部分缩小的情况下,页面迁移也可能发生在堆叠DRAM内部:当热页面驻留在必须转换为缓存的内存帧中时,该页面将被迁移到新的内存部分。这种DRAM内部迁移没有复杂性:与其他迁移类似,页面从先前的位置读取并写入新位置。迁移完成后,会发出系统范围的TLB失效以保持一致性。重要的是,从分区到交换的整个操作都是在操作系统的监督下完成的——是操作系统驱动硬件,而不是相反。操作系统宣布间隔,收集缓存命中计数器,确定分区,交换页面,更新PTE,并发出TLB失效。硬件仅执行操作系统的命令,暂停执行,执行CDS,并重置缓存命中计数器。
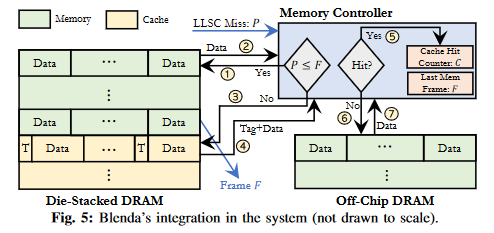
图5以基于块的直接映射缓存[85]为例,概括了Blenda的操作。内存控制器(MC)接收到对物理地址P的请求。通过将P与堆叠DRAM最后一个内存帧的地址(保存在寄存器F中)进行比较,MC决定堆叠DRAM的哪一部分应处理该请求。
如果P ≤ F,表示请求的数据分配在堆叠DRAM的内存部分;
数据从堆叠内存中获取,无需任何元数据开销。这是Blenda相对于全缓存设计改进的主要来源。
否则,请求进入缓存部分。MC计算相应的缓存集并将请求发送到正确的存储体。
获取标签和数据(带宽开销),MC执行标签检查。如果标签匹配,则为缓存命中;
缓存命中计数器(C)增加,数据被发送到片上。图中未显示的是,如果缓存部分是组相联的,还会有其他与堆叠DRAM的通信以更新元数据(例如LRU)。
如果标签不匹配,则为缓存未命中;请求继续到片外DRAM,
数据从片外DRAM中获取。图中未显示的是,在每个间隔,缓存命中计数器(C)被重置,寄存器F根据新配置更新。
硬件开销:比较电路、寄存器
Q:缓存如果动态变化,元数据的存储开销也在动态变化。看图是tag与数据未分离,那就很难内存对齐和扩展了?在cHBM不断变化的过程中,tag+data数据变化,有没有可能产生很多新的内部碎片??? 感觉这样设计如果是在未来真实硬件上,感觉就不太现实。很想知道审稿人的RevExp是多少。
Stalemate
到目前为止描述的机制存在一个潜在问题:如果整个堆叠DRAM变为内存,它将永远不会恢复到内存-缓存混合模式。这可能发生,因为Blenda基于缓存优势(即cacheAHF)来分区容量。如果在某个间隔内没有对运行的工作负载应用DRAM缓存,其优势将因此未定义;这会导致算法1由于除以零而崩溃(第1行)。为了解决这个问题,我们将内存部分的大小限制在预定义的阈值以下,确保堆叠DRAM的一小部分始终保留为缓存,即使完全将其用作内存可能会提高性能。这就是为什么算法1的第4行检查第二个条件。在本文中,小缓存部分(SCP)设置为堆叠DRAM大小的1/16。
这个倒是没啥问题
Graceful Transition
缓存通常通过地址的几位(或其哈希值)进行索引,并通过无法通过缓存集推断出的地址部分进行标记。索引基于缓存集的数量;例如,block_address % num_sets。当Blenda被重塑时,缓存集的数量会发生变化。这有两个影响:(i)标签位的数量发生变化。这使元数据的解释复杂化(例如,区分“标签”和“最近使用”)。(ii)未来的请求可能映射到不同的集,在不幸的情况下,可能会找到错误或过时的匹配,导致执行错误。1)标签扩展:为了解决第一个问题,我们扩展了标签字段,以考虑最大变化(全缓存)和最小变化(SCP)缓存中的标签大小。也就是说,我们扩展了标签字段,以捕获SCP的所有标签位。5 当实际标签大小小于标签字段宽度时,地址的高位存储在额外空间中。我们称新标签为扩展标签(E-Tag)。2)避免刷新:对于第二个问题,一个简单的解决方案是在重塑时刷新缓存部分。然而,刷新一个多GB的缓存可能代价高昂。与仅对脏块/页面执行的CDS不同,刷新必须对整个缓存执行,这会带来巨大的开销。此外,如第IV-C节所述,如果CDS在某些设置中开销较高,可以采用写回批处理等技术来加速;然而,缓存刷新无法通过此类技术改进,从而带来可扩展性挑战。
为了避免频繁刷新,我们提出了三种互补的技术。在描述它们之前,我们指出了动态可调整大小缓存可能引发的两个问题:
错误匹配:处理器请求地址X,但缓存提供地址Y,其中X ≠ Y。如果X和Y映射到同一集且它们的扩展标签(E-Tag)匹配,则可能发生这种情况。
陈旧匹配:处理器请求地址X,缓存提供X的旧副本。这种情况可能发生在以下场景中:当缓存大小为Size1时,地址X缓存在集S1中。然后,缓存调整为Size2,X映射到集S2。地址X在S2中被修改。随后,缓存调整为Size3。在Size3下,地址X再次映射到集S1。处理器请求X;请求在S1中命中,但S1不包含地址X的最新值。
后续略去,感觉没什么太需要看的了