gem5::Process Class Refference
gem5本身是用C++编写的,并不直接支持Python作为脚本语言。为了增加灵活性和易用性,gem5可以通过Pybind将部分C++代码暴露给Python。这样,用户可以使用Python编写脚本来控制gem5的行为、设置模拟参数、执行实验等
Pybind
Pybind是一个用于将C++代码绑定到Python的开源库。它允许开发者通过简单的方式创建Python模块,将现有的C++代码暴露给Python解释器,使得这些C++代码可以像Python代码一样被调用和使用。
无需手动编写Python扩展模块:
Pybind提供了一种简单的方法来将C++类、函数、变量等直接暴露给Python,而无需编写复杂的Cython或者手动编写Python扩展模块的代码。
类型安全和高效:
Pybind生成的绑定代码保留了C++代码的类型安全性和性能,因此Python代码在调用C++函数时不会出现类型错误,并且可以享受到C++代码的高效执行速度。
支持C++11及以上标准:
Pybind支持现代C++的特性,如lambda函数、智能指针等,这些特性可以直接在Python中使用。
无缝集成:
Pybind可以与其他Python库(如NumPy、SciPy等)无缝集成,使得使用C++编写的高性能计算核心可以方便地被Python脚本调用。
广泛应用:
Pybind在科学计算、机器学习、图形处理等领域得到了广泛应用,特别是在需要高性能计算或者现有C++代码库的项目中,Pybind提供了一个快速、便捷的Python接口。
示例1:
int add(int a, int b) { return a + b;}namespace py = pybind11;PYBIND11_MODULE(example, m) { m.def("add", &add, "A function which adds two numbers");}在这个示例中,add 函数将被绑定到Python模块 example 中,Python代码可以通过 import example 导入并调用 add 函数。
示例2:
xxxxxxxxxx// 文件: simple_example.hhclass SimpleExample {public: SimpleExample() {} int add(int a, int b) { return a + b; }};// SIMPLE_EXAMPLE_HHxxxxxxxxxx// 文件: simple_example.ccnamespace py = pybind11;PYBIND11_MODULE(gem5_pybind_example, m) { py::class_<SimpleExample>(m, "SimpleExample") .def(py::init<>()) .def("add", &SimpleExample::add);}xxxxxxxxxx# 文件: test_simple_example.pyimport gem5_pybind_example# 创建SimpleExample对象example = gem5_pybind_example.SimpleExample()# 调用add方法计算两个数的和result = example.add(3, 5)print("Result of add(3, 5):", result)
More detailed information can be accessed at 简介 - pybind11中文文档 (charlottelive.github.io)
page_table
gem5: mem/page_table.cc Source File
map
Parameters
| vaddr | The starting virtual address of the range. |
|---|---|
| paddr | The starting physical address of the range. |
| size | The length of the range in bytes. |
| cacheable | Specifies whether accesses are cacheable. |
xxxxxxxxxxvoidEmulationPageTable::map(Addr vaddr, Addr paddr, int64_t size, uint64_t flags){ // flags如果不为1 则按位与的结果为0 否则为1 // 因此,这里检查传入的标志是否包含覆盖(clobber)标志。 bool clobber = flags & Clobber; // 确保起始虚拟地址是页面对齐的。如果不对齐,则会触发断言失败。 assert(pageOffset(vaddr) == 0); // 打印分配页面的日志信息。可在脚本中输入命令 --debug-flags=MMU 获得输出结果 DPRINTF(MMU, "Allocating Page: %#x-%#x\n", vaddr, vaddr + size); // 循环处理整个范围内的映射,每次处理一页大小的映射。 while (size > 0) { // 查找当前虚拟地址是否已经在页表中存在 auto it = pTable.find(vaddr); // 如果已经存在映射 if (it != pTable.end()) { // 检查是否允许覆盖。如果不允许覆盖,则触发panic。 panic_if(!clobber, "EmulationPageTable::allocate: addr %#x already mapped", vaddr); // 如果允许覆盖,则更新对应的物理地址和标志。 it->second = Entry(paddr, flags); } else { // 如果不存在,则在页表中插入新的映射条目 pTable.emplace(vaddr, Entry(paddr, flags)); } // 更新剩余大小,虚拟地址和物理地址,继续处理下一页。 size -= _pageSize; vaddr += _pageSize; paddr += _pageSize; }}
clobber定义在Line98 in page_table.hh
xxxxxxxxxx enum MappingFlags : uint32_t { Clobber = 1, Uncacheable = 4, ReadOnly = 8, };Clobber(值为1):表示覆盖已经存在的映射。
Uncacheable(值为4):表示映射的内存区域是不可缓存的。
ReadOnly(值为8):表示映射的内存区域是只读的。
_pageSize 为const Addr 类型 定义在Line70 in page_table.hh
remap
用于重新映射虚拟地址范围,将原来的虚拟地址范围 vaddr 移动到新的虚拟地址范围 new_vaddr。
xxxxxxxxxxvoidEmulationPageTable::remap(Addr vaddr, int64_t size, Addr new_vaddr){ // 确保起始虚拟地址和新的虚拟地址都是页面对齐的 assert(pageOffset(vaddr) == 0); assert(pageOffset(new_vaddr) == 0); // 打印调试信息,显示要移动的页范围和大小 DPRINTF(MMU, "moving pages from vaddr %08p to %08p, size = %d\n", vaddr, new_vaddr, size); // 循环处理每一页 while (size > 0) { // 查找新旧地址的迭代器,查找页表中是否存在 vaddr 和 new_vaddr 的映射。 [[maybe_unused]] auto new_it = pTable.find(new_vaddr); auto old_it = pTable.find(vaddr); // 断言检查:确保 vaddr 在页表中存在映射,而 new_vaddr 在页表中不存在映射 assert(old_it != pTable.end() && new_it == pTable.end()); // 插入新映射并删除旧映射:将旧地址 vaddr 的映射插入到新地址 new_vaddr 中,并删除旧地址的映射。 pTable.emplace(new_vaddr, old_it->second); pTable.erase(old_it); // 更新剩余大小和地址,减去已经处理的页面大小,更新虚拟地址和新虚拟地址,继续处理下一页 size -= _pageSize; vaddr += _pageSize; new_vaddr += _pageSize; }}
getMappings
用于获取当前页表中的所有虚拟地址和物理地址的映射,并将这些映射存储在一个 std::vector 中
xxxxxxxxxxvoidEmulationPageTable::getMappings(std::vector<std::pair<Addr, Addr>> *addr_maps){ // 这行代码使用范围循环遍历 pTable 中的所有元素。pTable是std::unordered_map<Addr,Entry>的容器 for (auto &iter : pTable) // 将映射添加到向量 addr_maps->push_back(std::make_pair(iter.first, iter.second.paddr));}addr_maps 是一个指向 std::vector<std::pair<Addr, Addr>> 的指针,这个向量用于存储从虚拟地址到物理地址的映射对。
pTable 是一个 std::unordered_map<Addr, Entry>,其中 Addr 是虚拟地址,Entry 是一个包含映射信息的类。
iter 是一个引用,指向 pTable 中的当前元素,它是一个键值对(key-value pair)。
iter.first 是虚拟地址(键)。
iter.second 是一个 Entry 对象,包含映射信息。
iter.second.paddr 是物理地址。
使用 std::make_pair 创建一个包含虚拟地址和物理地址的 std::pair<Addr, Addr> 对象,然后将这个对象添加到 addr_maps 向量中。
unmap
用于从页表中取消映射一段虚拟地址范围
xxxxxxxxxxvoidEmulationPageTable::unmap(Addr vaddr, int64_t size){ // 确保起始虚拟地址 vaddr 是页面对齐的。如果 vaddr 不是页面对齐的,将触发断言失败(程序终止)。 assert(pageOffset(vaddr) == 0); // 打印调试信息,显示将要取消映射的页面范围和大小 DPRINTF(MMU, "Unmapping page: %#x-%#x\n", vaddr, vaddr + size); // 取消映射循环 while (size > 0) { // 查找映射,使用 pTable.find(vaddr) 查找虚拟地址 vaddr 对应的映射 // 如果找到了映射,返回一个指向该映射的迭代器;否则,返回 pTable.end() auto it = pTable.find(vaddr); // 确保 vaddr 在页表中存在映射。如果不存在,将触发断言失败(程序终止) assert(it != pTable.end()); // 使用 pTable.erase(it) 从页表中删除找到的映射 pTable.erase(it); // 更新剩余大小和地址,将 size 减去页面大小 _pageSize,更新 vaddr 以指向下一个页面,继续处理下一页 size -= _pageSize; vaddr += _pageSize; }}
isUnmapped
用于检查给定的虚拟地址范围是否未映射
xxxxxxxxxxboolEmulationPageTable::isUnmapped(Addr vaddr, int64_t size){ // 起始地址必须是页面对齐的,否则断言失败 assert(pageOffset(vaddr) == 0); // 遍历范围内的每个页面,如果找到任何映射,返回false for (int64_t offset = 0; offset < size; offset += _pageSize) if (pTable.find(vaddr + offset) != pTable.end()) return false; // 如果所有页面都未映射,返回 true return true;}
lookup
用于在页表中查找给定虚拟地址的映射,并返回指向该映射的指针。如果没有找到对应的映射,则返回 nullptr。
xxxxxxxxxxconst EmulationPageTable::Entry *EmulationPageTable::lookup(Addr vaddr){ // 页面对齐:将虚拟地址 vaddr 对齐到页面边界。这个操作确保地址与页面大小对齐,使得查找操作针对正确的页面起始地址进行 Addr page_addr = pageAlign(vaddr); // 在页表中查找对齐后的虚拟地址 // 使用 pTable.find(page_addr) 在页表中查找对齐后的虚拟地址 page_addr。 // PTableItr 是 std::unordered_map<Addr, Entry>::iterator 类型的别名,表示页表的迭代器类型。 // 如果找到映射,find 返回指向该映射的迭代器;如果找不到,返回 pTable.end() PTableItr iter = pTable.find(page_addr); // 如果 iter 等于 pTable.end(),表示没有找到对应的映射,返回 nullptr if (iter == pTable.end()) return nullptr; // 如果找到了映射,返回指向 iter 所指向的 Entry 对象的指针 return &(iter->second);}这种查找操作对于模拟环境中的地址转换和内存管理非常有用
const EmulationPageTable::Entry *表示返回一个指向EmulationPageTable::Entry类型的常量指针。
xxxxxxxxxx struct Entry { Addr paddr; uint64_t flags; // 有参无参构造函数 Entry(Addr paddr, uint64_t flags) : paddr(paddr), flags(flags) {} Entry() {} };
translate (bool)
用于将虚拟地址转换为物理地址。如果转换成功,返回 true 并通过引用参数 paddr 返回物理地址;如果转换失败,返回 false
xxxxxxxxxxboolEmulationPageTable::translate(Addr vaddr, Addr &paddr){ // 查找虚拟地址 vaddr 对应的页表条目 const Entry *entry = lookup(vaddr); // 如果找不到条目,打印调试信息并返回 false if (!entry) { DPRINTF(MMU, "Couldn't Translate: %#x\n", vaddr); return false; } // 计算物理地址:pageOffset(vaddr) 计算虚拟地址 vaddr 在页面中的偏移量 // 将偏移量加上找到的页表条目中的物理地址 entry->paddr,得到最终的物理地址 paddr。 paddr = pageOffset(vaddr) + entry->paddr; DPRINTF(MMU, "Translating: %#x->%#x\n", vaddr, paddr); return true;}
translate (Fault)
用于将请求中的虚拟地址转换为物理地址。如果转换失败,则返回一个新的 GenericPageTableFault 对象;如果成功,则设置请求的物理地址,并检查请求是否跨越页面边界
xxxxxxxxxxFaultEmulationPageTable::translate(const RequestPtr &req){ Addr paddr; // 检查页面对齐:确保请求中的虚拟地址范围在同一页内。 // pageAlign:函数用于将地址对齐到页面边界。 // 不在同一页触发断言失败 assert(pageAlign(req->getVaddr() + req->getSize() - 1) == pageAlign(req->getVaddr())); // 调用 translate 函数:尝试将请求中的虚拟地址转换为物理地址。 // 如果转换失败,返回一个新的 GenericPageTableFault 对象,表示转换失败。 if (!translate(req->getVaddr(), paddr)) return Fault(new GenericPageTableFault(req->getVaddr())); // 将转换后的物理地址设置到请求对象中 req->setPaddr(paddr); // 检查跨页请求,检查请求是否跨越页面边界 // 计算偏移量:(paddr & (_pageSize - 1)) 计算物理地址在页面中的偏移量。 // 如果偏移量加上请求大小超过页面大小,则触发panic并输出错误信息 if ((paddr & (_pageSize - 1)) + req->getSize() > _pageSize) { panic("Request spans page boundaries!\n"); return NoFault; } return NoFault;}Details
为什么
(paddr & (_pageSize - 1))可以计算物理地址在页面中的偏移量 ?
在计算机系统中,内存通常是按页面(或页)来管理的,每一页有固定的大小,例如 4KB、8KB 或者其他大小。在这种情况下,页的大小通常用
_pageSize表示。
页面大小和偏移量
假设
_pageSize是页面的大小(通常是 4KB,即 4096 字节)。页面大小为 4096 字节,其二进制表示为
1000000000000。
位运算中的与操作(&)
在二进制中,一个数减去 1,数字的最低有效位的1会变成0,而这个1之后的所有0都会变成1,其它位保持不变。
应用
(paddr & (_pageSize - 1)),即paddr与页面大小减 1 的结果进行与运算,得到的是paddr在页面内偏移的部分,因为这个操作会清除掉paddr最高有效位(即大于等于页面大小的部分),只保留页面大小范围内的偏移部分。
e.g.当页面大小为 4KB(4096 字节)时,假设物理地址
paddr是0x12345,我们来计算它在页面中的偏移量。
_pageSize = 4096(1 0000 0000 0000)
paddr = 0x12345页面大小减 1 的二进制表示是
0 1111 1111 1111,即十六进制表示是0xFFF
(paddr & (_pageSize - 1))等价于(0x12345 & 0xFFF)xxxxxxxxxx0x12345 -> 0001 0010 0011 0100 01010xFFF -> 0000 0000 1111 1111 1111-------------------------------------Result -> 0000 0000 0011 0100 0101
translate (PageTableTranslationGen)
这段代码的主要功能是将给定的地址范围 range 进行页面对齐,然后尝试将每个地址翻译为物理地址。如果翻译失败,它将生成一个对应的错误对象,并将其记录在 range.fault 中
xxxxxxxxxxvoidEmulationPageTable::PageTableTranslationGen::translate(Range &range) const{ // 获取页面大小,pt 是一个指向 EmulationPageTable 对象的指针 // pageSize() 是 EmulationPageTable 中的一个方法,用于返回页面的大小 const Addr page_size = pt->pageSize(); // 计算下一个对齐地址: 将 range.vaddr 地址向上对齐到最接近的页面边界。 // roundUp 函数:通常是将 vaddr 向上取整到 page_size 的倍数,确保 next 是 vaddr 或者更大的页面对齐地址 Addr next = roundUp(range.vaddr, page_size); // 处理特殊情况 // 如果对齐后的地址与原始地址相同(即 vaddr 已经是页面对齐的),则将 next 增加一个页面大小,以确保 next 不等于 vaddr。 if (next == range.vaddr) next += page_size; // 更新地址范围大小 // 更新 range.size,确保 range.size 不超过从 vaddr 到 next 的大小,以确保不会超出原始范围的边界。 range.size = std::min(range.size, next - range.vaddr); // 调用地址翻译方法 // 将 range.vaddr 地址翻译为物理地址 range.paddr。 if (!pt->translate(range.vaddr, range.paddr)) range.fault = Fault(new GenericPageTableFault(range.vaddr));}
serialize
将 EmulationPageTable 对象的数据序列化到 CheckpointOut 对象 cp 中
这种序列化方法通常用于将对象的状态保存到文件或者网络传输中,以便稍后能够重新加载该对象的状态。
xxxxxxxxxxvoidEmulationPageTable::serialize(CheckpointOut &cp) const{ // 创建一个名为 "ptable" 的序列化区段,将数据序列化到 cp 中 ScopedCheckpointSection sec(cp, "ptable"); // 序列化表的大小:使用 paramOut 方法将 pTable 的大小序列化到 cp 中 paramOut(cp, "size", pTable.size()); // 使用 count 计数器迭代每个 pTable 中的表项 PTable::size_type count = 0; // 遍历并序列化每个表项 for (auto &pte : pTable) { ScopedCheckpointSection sec(cp, csprintf("Entry%d", count++)); paramOut(cp, "vaddr", pte.first); paramOut(cp, "paddr", pte.second.paddr); paramOut(cp, "flags", pte.second.flags); } // 确保 count 计数器的值与 pTable 的大小相等,即确保所有表项都已经被正确地序列化。 assert(count == pTable.size());}
unserialize
从 CheckpointIn 对象 cp 中反序列化数据,恢复 EmulationPageTable 对象的状态
这种反序列化方法通常用于从文件或网络接收的数据中恢复对象的状态,以便后续使用。
xxxxxxxxxxvoidEmulationPageTable::unserialize(CheckpointIn &cp){ int count; // 使用 ScopedCheckpointSection 创建一个序列化区段,名称为 "ptable" ScopedCheckpointSection sec(cp, "ptable"); // 使用 paramIn 方法从 cp 中读取名为 "size" 的参数,并将其存储到 count 变量中。这个参数表示了要反序列化的表项数量 paramIn(cp, "size", count); // 使用 for 循环迭代 count 次,即反序列化每个表项 for (int i = 0; i < count; ++i) { // 使用 ScopedCheckpointSection 创建一个名为 "EntryN" 的序列化区段,其中 N 是当前迭代的索引。 ScopedCheckpointSection sec(cp, csprintf("Entry%d", i)); // 使用 UNSERIALIZE_SCALAR 宏从 cp 中反序列化每个表项的虚拟地址 vaddr、物理地址 paddr 和标志 flags。 Addr vaddr; UNSERIALIZE_SCALAR(vaddr); Addr paddr; uint64_t flags; UNSERIALIZE_SCALAR(paddr); UNSERIALIZE_SCALAR(flags); // 使用 pTable.emplace(vaddr, Entry(paddr, flags)) 将反序列化的表项插入到 pTable 中。 pTable.emplace(vaddr, Entry(paddr, flags)); }}
externalize
将 EmulationPageTable 对象的状态外部化为一个字符串
通过迭代 pTable 中的每个表项,将虚拟地址和物理地址格式化为十六进制字符串,并用 ":" 和 ";" 分隔符组合成一个字符串序列
这种方法常用于将对象状态以文本格式输出,便于打印、调试或者与其他系统交互。
xxxxxxxxxxconst std::stringEmulationPageTable::externalize() const{ // 创建字符串流对象,用于将数据转换为字符串格式 std::stringstream ss; // 迭代 pTable 中的每个表项 // 使用 for 循环遍历 pTable 容器,其中 PTable 是 std::unordered_map<Addr, Entry> 的别名 // 表示虚拟地址到 Entry 结构的映射 for (PTable::const_iterator it=pTable.begin(); it != pTable.end(); ++it) { // 下注-> ss << std::hex << it->first << ":" << it->second.paddr << ";"; } //返回序列化后的字符串 return ss.str();}对每个表项执行以下操作:
std::hex:设置流输出为十六进制格式。it->first:获取当前表项的虚拟地址(键)。it->second.paddr:获取当前表项的物理地址。将虚拟地址和物理地址格式化为字符串,并用 ":" 分隔。
使用 ";" 分隔每个表项的输出,形成一个格式化的字符串序列。
Process
gem5: sim/process.cc Source File
process.hh
xxxxxxxxxxnamespace gem5{// gem5 命名空间中包含了一个内部命名空间 loader,在 loader 中声明了 ObjectFile 类。namespace loader{class ObjectFile;} // namespace loader
// 这些是前向声明,表明这些类和结构将在其他地方定义struct ProcessParams;class EmulatedDriver;class EmulationPageTable;class SEWorkload;class SyscallDesc;class SyscallReturn;class System;class ThreadContext;
// Process 类继承自 SimObject 类,表示它是一个模拟对象class Process : public SimObject{ public: Process(const ProcessParams ¶ms, EmulationPageTable *pTable, loader::ObjectFile *obj_file); // 这些函数分别用于初始化、状态保存和恢复、初始化状态、draining以及系统调用处理。 void serialize(CheckpointOut &cp) const override; void unserialize(CheckpointIn &cp) override; void init() override; void initState() override; DrainState drain() override; virtual void syscall(ThreadContext *tc) { numSyscalls++; } // 进程标识符函数,这些内联函数用于获取和设置进程的各种标识符,例如用户ID、组ID、进程ID等 // 这是进程所属用户的唯一标识符。每个用户在系统中都有一个唯一的UID,操作系统通过它来确定进程的所有者 inline uint64_t uid() { return _uid; } /* Effective User ID (EUID): 这是进程在执行某些操作时使用的用户ID。 EUID通常用于权限检查,允许进程以其他用户的权限执行任务。*/ inline uint64_t euid() { return _euid; } /* Group ID (GID): 这是进程所属组的唯一标识符。每个组在系统中都有一个唯一的GID,用于管理用户权限和访问控制*/ inline uint64_t gid() { return _gid; } /* Effective Group ID (EGID): 这是进程在执行某些操作时使用的组ID。 EGID通常用于权限检查,允许进程以其他组的权限执行任务*/ inline uint64_t egid() { return _egid; } /* Process ID (PID): 这是进程的唯一标识符。每个进程在系统中都有一个唯一的PID,用于进程管理和调度。*/ inline uint64_t pid() { return _pid; } /* Parent Process ID (PPID): 这是父进程的唯一标识符。每个进程都有一个父进程,PPID用于表示该父进程的PID */ inline uint64_t ppid() { return _ppid; } /* Process Group ID (PGID): 这是进程组的唯一标识符。 进程组用于将一组相关进程聚集在一起,以便进行统一的信号处理和作业控制*/ inline uint64_t pgid() { return _pgid; } /* 设置 Process Group ID: 这个函数用于设置进程的PGID*/ inline void pgid(uint64_t pgid) { _pgid = pgid; } /* Thread Group ID (TGID): 在多线程环境中,TGID用于标识线程组。 通常,TGID等于主线程的PID,用于将一个进程中的所有线程聚集在一起*/ inline uint64_t tgid() { return _tgid; } xxxxxxxxxx /* 用于返回进程的可执行文件的名称 */ const char *progName() const { return executable.c_str(); } /* 在进程的已加载驱动程序中查找指定的驱动程序 */ EmulatedDriver *findDriver(std::string filename); // This function acts as a callback to update the bias value in // the object file because the parameters needed to calculate the // bias are not available when the object file is created. /* 用于更新对象文件的偏移值 */ void updateBias(); /* 获取对象文件的偏移值 */ Addr getBias(); /* 返回进程的起始程序计数器(PC) */ Addr getStartPC(); /* 返回用于解释可执行文件的解释器对象 */ loader::ObjectFile *getInterpreter(); // This function allocates physical memory as backing store, and then maps // it into the virtual address space of the process. The range of virtual // addresses being configured starts at the address "vaddr" and is of size // "size" bytes. If some part of this range of virtual addresses is already // configured, this function will error out unless "clobber" is set. If // clobber is set, then those existing mappings will be replaced. // // If the beginning or end of the virtual address range does not perfectly // align to page boundaries, it will be expanded in either direction until // it does. This function will therefore set up *at least* the range // requested, and may configure more if necessary.
/* 为进程分配物理内存并映射到虚拟地址空间,必要时调整地址范围以对齐到页面边界 * Addr vaddr: 虚拟地址的起始位置。 * int64_t size: 分配的内存大小(字节)。 * bool clobber: 如果为 true,则覆盖现有的映射,否则在存在映射时会出错。 */ void allocateMem(Addr vaddr, int64_t size, bool clobber=false); /* 修复在给定虚拟地址发生的错误 */ bool fixupFault(Addr vaddr); // After getting registered with system object, tell process which // system-wide context id it is assigned. /* 将一个线程上下文ID分配给进程,分配并记录进程使用的线程上下文ID */ void assignThreadContext(ContextID context_id) { contextIds.push_back(context_id); } /* 销并移除指定的线程上下文ID */ void revokeThreadContext(int context_id); /* 指示内存映射区域是否向下增长。默认返回 true,表示向下增长 */ virtual bool mmapGrowsDown() const { return true; } /* 将物理内存映射到虚拟地址空间 */ bool map(Addr vaddr, Addr paddr, int64_t size, bool cacheable = true); /* 在新线程上下文中复制指定的页面,必要时分配新的页面 * Addr vaddr: 虚拟地址。 * Addr new_paddr: 新的物理地址。 * ThreadContext *old_tc: 旧的线程上下文。 * ThreadContext *new_tc: 新的线程上下文。 * bool alloc_page: 是否分配页面 */ void replicatePage(Addr vaddr, Addr new_paddr, ThreadContext *old_tc, ThreadContext *new_tc, bool alloc_page); /* 克隆进程和线程上下文,将旧上下文的状态复制到新上下文和新进程对象中 */ virtual void clone(ThreadContext *old_tc, ThreadContext *new_tc, Process *new_p, RegVal flags);xxxxxxxxxx // thread contexts associated with this process // 存储与该进程相关联的线程上下文ID列表 std::vector<ContextID> contextIds; // system object which owns this process // 指向拥有该进程的系统对象的指针 System *system;
//用于仿真该进程的工作负载对象的指针 SEWorkload *seWorkload; // flag for using architecture specific page table // 指示是否使用架构特定的页表 bool useArchPT; // running KVM requires special initialization // 运行 KVM 需要特殊的初始化 bool kvmInSE; // flag for using the process as a thread which shares page tables // 是否将进程用作共享页表的线程 bool useForClone; EmulationPageTable *pTable; // Memory proxy for initial image load. //在进程初始化时加载初始内存映像 /* std::unique_ptr: 这是C++标准库中的一个智能指针类型,负责独占所有权管理。它确保所指向的对象在超出作用域时被自动销毁,从而避免内存泄漏。 unique_ptr 不允许多个指针同时拥有同一个对象,这意味着它的所有权是独占的。 SETranslatingPortProxy: 这是一个类,通常用于内存代理,负责在仿真环境中翻译和访问内存地址。 在 gem5 中,SETranslatingPortProxy 提供了一种方式,可以通过这个代理来访问进程的虚拟内存。 具体来说,它可以翻译虚拟地址到 物理地址并进行相应的内存操作。*/ std::unique_ptr<SETranslatingPortProxy> initVirtMem;xxxxxxxxxx // Loader 类是一个内部类,用于加载进程实例。它是一个单例类,禁止拷贝和赋值。 class Loader { public: Loader(); /* Loader instances are singletons. */ Loader(const Loader &) = delete; void operator=(const Loader &) = delete; virtual ~Loader() {} virtual Process *load(const ProcessParams ¶ms, loader::ObjectFile *obj_file) = 0; }; // Try all the Loader instance's "load" methods one by one until one is // successful. If none are, complain and fail. static Process *tryLoaders(const ProcessParams ¶ms, loader::ObjectFile *obj_file); loader::ObjectFile *objFile; // 存储进程的内存映像 loader::MemoryImage image; // 存储解释器的内存映像(用于动态链接的情况) loader::MemoryImage interpImage; // 存储传递给进程的命令行参数 std::vector<std::string> argv; // 存储传递给进程的环境变量 std::vector<std::string> envp; // 存储进程的可执行文件路径 std::string executable; // 将给定路径转换为绝对路径 std::string absolutePath(const std::string &path, bool host_fs); // 检查并返回重定向后的路径 std::string checkPathRedirect(const std::string &filename); // 存储进程的目标当前工作目录 std::string tgtCwd; // 存储主机的当前工作目录 std::string hostCwd; // Syscall emulation uname release. // 存储系统调用模拟的uname释放版本 std::string release; // Id of the owner of the process uint64_t _uid; uint64_t _euid; uint64_t _gid; uint64_t _egid; // pid of the process and it's parent uint64_t _pid; uint64_t _ppid; uint64_t _pgid; uint64_t _tgid; // Emulated drivers available to this process // 存储进程可用的模拟驱动程序列表 std::vector<EmulatedDriver *> drivers; // 存储进程的文件描述符数组的智能指针 std::shared_ptr<FDArray> fds; // 指示进程是否处于退出组状态的布尔指针 bool *exitGroup; // 存储进程内存状态的智能指针 std::shared_ptr<MemState> memState; // 存储需要在子进程中清除的线程ID uint64_t childClearTID; // Process was forked with SIGCHLD set. // 指示进程是否被forked并设置了SIGCHLD信号的布尔指针 bool *sigchld; // Contexts to wake up when this thread exits or calls execve // 存储在vfork操作中需要唤醒的上下文ID列表 std::vector<ContextID> vforkContexts; // Track how many system calls are executed // 统计并存储该进程执行的系统调用次数 statistics::Scalar numSyscalls;}; } // namespace gem5 // __PROCESS_HH__
process.cc
anonymous namespace
xxxxxxxxxxnamespace{ typedef std::vector<Process::Loader *> LoaderList; LoaderList &process_loaders(){ static LoaderList loaders; return loaders;} } // anonymous namespacenamespace { ... }:这是一个匿名命名空间。匿名命名空间中的内容在该编译单元内是私有的,也就是说,它们不会与其他编译单元中的同名实体发生冲突。typedef std::vector<Process::Loader *> LoaderList;:这里定义了一个类型别名
LoaderList,它代表了一个std::vector,其中存储的是指向Process::Loader对象的指针。
LoaderList & process_loaders() { ... }:这是一个返回
LoaderList引用的函数。该函数的作用是提供对一个静态局部变量
loaders的引用。
static LoaderList loaders;:在函数内部定义了一个静态局部变量
loaders,它的类型是LoaderList。静态局部变量在函数的所有调用中保持其值,且只在程序的生命周期内初始化一次。
return loaders;:函数返回对
loaders变量的引用。
完整地看,这段代码的作用是定义了一个匿名命名空间,内部包含了一个LoaderList类型的静态变量loaders,以及一个函数process_loaders,该函数返回loaders的引用。由于匿名命名空间的存在,这些定义在该编译单元内是私有的,不会与其他编译单元中的同名实体冲突。
总结起来,这段代码可以实现一个单例模式的容器,用于存储Process::Loader的指针集合,并确保这个容器在整个程序运行期间是唯一且可访问的。
匿名命名空间(anonymous namespace)是一种在C++中用于限制命名空间中的标识符(变量、函数、类型等)的作用域仅在当前编译单元(通常是单个源文件)内的方法。使用匿名命名空间可以防止标识符与其他编译单元中的同名标识符发生冲突,增强封装性和代码模块化。
在C++中,匿名命名空间通过
namespace { ... }语法来定义。匿名命名空间内的所有内容在当前编译单元内是私有的,不会暴露给其他编译单元。下面是一个示例,帮助理解匿名命名空间的使用:
xxxxxxxxxxnamespace {int secret_number = 42;void print_secret() {std::cout << "The secret number is: " << secret_number << std::endl;}}int main() {print_secret(); // 可以调用匿名命名空间中的函数// std::cout << secret_number << std::endl; // 直接访问匿名命名空间中的变量也是可以的return 0;}在这个示例中,
secret_number变量和print_secret函数都定义在匿名命名空间内。它们在当前编译单元内是私有的,无法被其他源文件访问。
xxxxxxxxxx// 全局变量int global_number = 100;namespace MyNamespace {int namespace_number = 200;void print_namespace_number() {std::cout << "Namespace number is: " << namespace_number << std::endl;}}namespace {int local_number = 300;void print_local_number() {std::cout << "Local number is: " << local_number << std::endl;}}int main() {std::cout << "Global number is: " << global_number << std::endl;MyNamespace::print_namespace_number();print_local_number(); // 调用匿名命名空间中的函数return 0;}在这个示例中,有一个全局变量
global_number,一个在MyNamespace命名空间中的变量namespace_number和函数print_namespace_number,以及一个在匿名命名空间中的变量local_number和函数print_local_number。匿名命名空间中的内容仅在当前编译单元内可见,其他源文件无法访问或引用这些内容。
匿名命名空间适用于那些只在单个源文件中使用的实体,而普通命名空间适用于需要在多个源文件中共享的实体。
Loader::Loader()
在 Process::Loader 类的每个对象构造时,将对象的指针添加到一个静态 LoaderList 容器中。这种设计可以用于跟踪和管理所有已创建 Process::Loader 对象的集合,这在需要动态管理对象集合时非常有用。
xxxxxxxxxxProcess::Loader::Loader(){ process_loaders().emplace_back(this);}xxxxxxxxxxprocess_loaders(){static LoaderList loaders;return loaders;}
tryLoaders
使用一组加载器(存储在 process_loaders() 返回的容器中),尝试加载给定的对象文件 obj_file 中的进程信息。它会逐个调用加载器的 load 函数,直到找到一个能够成功加载的加载器为止,然后返回相应的 Process 对象指针;如果所有加载器都无法成功加载,则返回 nullptr。
这种设计适用于需要动态选择加载器,并且希望在加载成功时立即返回的情况。
xxxxxxxxxxProcess *Process::tryLoaders(const ProcessParams ¶ms, loader::ObjectFile *obj_file){ for (auto &loader_it : process_loaders()) { Process *p = loader_it->load(params, obj_file); if (p) return p; } return nullptr;}Process * Process::tryLoaders(const ProcessParams ¶ms, loader::ObjectFile *obj_file)是Process类的一个成员函数,返回类型为Process*,接受两个参数:params是ProcessParams类型的引用,obj_file是loader::ObjectFile类型的指针。for (auto &loader_it : process_loaders()):这是一个范围循环(range-based for loop),遍历了process_loaders()函数返回的LoaderList容器中的每一个元素。loader_it是一个指向Process::Loader*的指针,即加载器对象的指针。Process *p = loader_it->load(params, obj_file);:对当前加载器对象调用load函数,传入params和obj_file作为参数。load函数的目的是尝试从obj_file中加载进程信息,如果成功则返回一个Process对象指针,否则返回nullptr。if (p):如果load函数返回非空指针p,表示加载成功。return p;:直接返回指向成功加载的Process对象的指针p。
normalize
规范化给定的目录路径 directory。它确保目录路径以斜杠 / 结尾,如果输入的 directory 参数的末尾没有斜杠,则在其末尾添加一个斜杠;如果已经以斜杠结尾,则直接返回原始的 directory 字符串。
xxxxxxxxxxstatic std::stringnormalize(const std::string& directory){ if (directory.back() != '/') return directory + '/'; return directory;}
Process::Process()
实现了 Process 类的构造函数 Process::Process,它接受多个参数并使用成员初始化列表(member initializer list)来初始化 Process 对象的各个成员变量
xxxxxxxxxxProcess::Process(const ProcessParams ¶ms, EmulationPageTable *pTable, loader::ObjectFile *obj_file) // 调用 SimObject 的构造函数,传递 params 参数 // 初始化 system 成员变量为 params.system : SimObject(params), system(params.system), // 尝试将 system->workload 转换为 SEWorkload* 类型,并初始化 seWorkload seWorkload(dynamic_cast<SEWorkload *>(system->workload)), useArchPT(params.useArchPT), kvmInSE(params.kvmInSE), useForClone(false), pTable(pTable), objFile(obj_file), argv(params.cmd), envp(params.env), executable(params.executable == "" ? params.cmd[0] : params.executable), tgtCwd(normalize(params.cwd)), hostCwd(checkPathRedirect(tgtCwd)), release(params.release), _uid(params.uid), _euid(params.euid), _gid(params.gid), _egid(params.egid), _pid(params.pid), _ppid(params.ppid), _pgid(params.pgid), drivers(params.drivers), fds(std::make_shared<FDArray>( params.input, params.output, params.errout)), childClearTID(0), ADD_STAT(numSyscalls, statistics::units::Count::get(), "Number of system calls"){ fatal_if(!seWorkload, "Couldn't find appropriate workload object."); fatal_if(_pid >= System::maxPID, "_pid is too large: %d", _pid); auto ret_pair = system->PIDs.emplace(_pid); fatal_if(!ret_pair.second, "_pid %d is already used", _pid); _tgid = params.pid; exitGroup = new bool(); sigchld = new bool(); // 调用 objFile 的 buildImage() 函数,返回一个 Image 对象,并赋值给 image 成员变量,构建了进程的映像 image = objFile->buildImage(); if (loader::debugSymbolTable.empty()) loader::debugSymbolTable = objFile->symtab();}
clone
用于复制一个进程的状态到另一个进程对象 np 中,根据传入的 flags 参数来选择性地复制不同的状态和资源
这种设计允许在多线程或进程复制场景下,根据需要选择性地复制不同的状态和资源,以实现进程或线程的克隆操作。
xxxxxxxxxxvoidProcess::clone(ThreadContext *otc, ThreadContext *ntc, Process *np, RegVal flags){ // 定义一些宏,如果未定义,则将它们设为0 // // 如果 CLONE_VM 在 flags 中被设置 if (CLONE_VM & flags) { // 删除 np 的页表对象 delete np->pTable; // 将当前进程的页表赋值给 np 的页表 np->pTable = pTable; // // 将当前进程的内存状态赋值给 np 的内存状态 np->memState = memState; } else { // 如果 CLONE_VM 没有在 flags 中被设置 // 定义一个类型为 std::vector<std::pair<Addr,Addr>> 的容器 mappings typedef std::vector<std::pair<Addr,Addr>> MapVec; MapVec mappings; // 从当前进程的页表中获取映射关系并存储到 mappings 中 pTable->getMappings(&mappings); // 遍历 mappings 中的每一个映射 for (auto map : mappings) { Addr paddr, vaddr = map.first; // 如果 np 的页表无法将 vaddr 翻译为物理地址,则分配一个新的页面 bool alloc_page = !(np->pTable->translate(vaddr, paddr)); // 复制页面到 np 的页表中,alloc_page:是否分配页面 np->replicatePage(vaddr, paddr, otc, ntc, alloc_page:是否分配页面); } // // 将当前进程的内存状态复制到 np 的内存状态中 *np->memState = *memState; } // 如果 CLONE_FILES 在 flags 中被设置 if (CLONE_FILES & flags) { // 将当前进程的文件描述符数组赋值给 np 的文件描述符数组 np->fds = fds; } else {// 如果 CLONE_FILES 没有在 flags 中被设置 // 创建一个 np 的文件描述符数组的共享指针,并赋值给 nfds std::shared_ptr<FDArray> nfds = np->fds; // 遍历当前进程的文件描述符数组中的每一个文件描述符 for (int tgt_fd = 0; tgt_fd < fds->getSize(); tgt_fd++) { // 获取当前文件描述符数组中索引为 tgt_fd 的文件描述符 std::shared_ptr<FDEntry> this_fde = (*fds)[tgt_fd]; if (!this_fde) {// 如果当前文件描述符为空 // 将 np 的文件描述符数组中索引为 tgt_fd 的位置设置为空 nfds->setFDEntry(tgt_fd, nullptr); continue; } // 克隆当前文件描述符,并将克隆后的对象赋值给 np 的文件描述符数组中索引为 tgt_fd 的位置 nfds->setFDEntry(tgt_fd, this_fde->clone()); // 如果当前文件描述符是 HBFDEntry 类型 auto this_hbfd = std::dynamic_pointer_cast<HBFDEntry>(this_fde); if (!this_hbfd) continue; // 获取当前文件描述符关联的仿真文件描述符 int this_sim_fd = this_hbfd->getSimFD(); // 如果仿真文件描述符小于等于2,则继续下一个循环 if (this_sim_fd <= 2) continue; // 复制当前文件描述符到 np 的文件描述符中,并确保复制成功 int np_sim_fd = dup(this_sim_fd); assert(np_sim_fd != -1); // 获取 np 的文件描述符数组中索引为 tgt_fd 的文件描述符,并设置仿真文件描述符 auto nhbfd = std::dynamic_pointer_cast<HBFDEntry>((*nfds)[tgt_fd]); nhbfd->setSimFD(np_sim_fd); } } // 如果 CLONE_THREAD 在 flags 中被设置 if (CLONE_THREAD & flags) { np->_tgid = _tgid;// 将当前进程的进程组 ID 赋值给 np 的进程组 ID delete np->exitGroup;// 删除 np 的退出组对象 np->exitGroup = exitGroup;// 将当前进程的退出组对象赋值给 np 的退出组对象 } // 如果 CLONE_VFORK 在 flags 中被设置 if (CLONE_VFORK & flags) { // 将当前线程的上下文 ID 添加到 np 的 vfork 上下文列表中 np->vforkContexts.push_back(otc->contextId()); } // 将当前进程的命令行参数 argv 添加到 np 的命令行参数 argv 中 np->argv.insert(np->argv.end(), argv.begin(), argv.end()); // 将当前进程的环境变量 envp 添加到 np 的环境变量 envp 中 np->envp.insert(np->envp.end(), envp.begin(), envp.end());}共享指针
自动内存管理
共享指针提供自动内存管理功能,当所有引用指向同一对象的共享指针都销毁时,对象本身会被自动释放。这避免了手动管理内存的复杂性和潜在的内存泄漏问题。
引用计数
共享指针使用引用计数机制来跟踪有多少指针共享同一个对象。当一个新的共享指针被赋值给现有的对象时,引用计数会增加。当一个共享指针被销毁时,引用计数会减少到0,最后一个指针被销毁时,对象会被释放。
共享资源
在并发环境中(例如多线程或多进程),多个线程或进程可能需要访问和操作同一个资源(例如文件描述符数组)。共享指针允许这些资源在多个所有者之间安全地共享,而无需担心对象的生命周期问题。这样可以确保在所有引用对象的共享指针销毁之前,资源始终可用。
简化代码
使用共享指针可以简化代码逻辑,使代码更清晰。例如,在复制文件描述符数组时,使用共享指针可以直接赋值,而不需要考虑深拷贝或手动管理内存的问题。
在这个 clone 函数中,使用共享指针 (std::shared_ptr) 可以有效管理文件描述符数组 (FDArray) 和文件描述符条目 (FDEntry),确保资源在多线程或多进程环境中的安全共享和自动释放。这不仅提高了代码的安全性和可维护性,还减少了内存管理的复杂性。
FDEntry
FDEntry是一个基类,用于表示文件描述符条目。这个类通常包含与文件描述符相关的基本功能,如打开、关闭、读写等操作。
HBFDEntry
HBFDEntry继承了FDEntry类,并增加了一些特定于后备文件描述符(HBFD)的功能。例如,HBFDEntry可能包含指向主机文件描述符的指针,并提供与之交互的方法。
revokeThreadContext
用于撤销(删除)进程中的一个线程上下文(ThreadContext)。函数的主要任务是从 contextIds 列表中找到给定的 context_id 并将其移除。
xxxxxxxxxxvoidProcess::revokeThreadContext(int context_id){ std::vector<ContextID>::iterator it; for (it = contextIds.begin(); it != contextIds.end(); it++) { if (*it == context_id) { contextIds.erase(it); return; } } warn("Unable to find thread context to revoke");}
init
用于初始化进程。这个函数的主要任务是更新动态可执行文件的 ld_bias 和构建解释器(如果存在)的内存映像
xxxxxxxxxxvoidProcess::init(){ // Patch the ld_bias for dynamic executables. updateBias(); if (objFile->getInterpreter()) interpImage = objFile->getInterpreter()->buildImage();}
initState
用于初始化进程的状态。它执行一系列操作以确保进程正确设置并准备好执行
xxxxxxxxxxvoidProcess::initState(){ /* 检查 contextIds 列表是否为空 * 如果 contextIds 列表为空,表示该进程没有与任何硬件上下文关联, * 这会导致一个致命错误。fatal 函数会打印错误信息并终止程序 */ if (contextIds.empty()) fatal("Process %s is not associated with any HW contexts!\n", name()); // 获取第一个线程上下文并启用 // 获取与该进程关联的第一个线程上下文(ThreadContext)。 ThreadContext *tc = system->threads[contextIds[0]]; // 调用 activate 方法将该线程上下文标记为活动状态,使其开始计时或执行。 tc->activate(); /*调用页表(PageTable)的 initState 方法初始化页表的状态。这一步通常包括设置页表条目和准备内存管理相关的数据结构*/ pTable->initState(); /* 初始化虚拟内存代理 */ /* 创建一个新的 SETranslatingPortProxy 对象,并将其分配给 initVirtMem。 * 这个代理用于在虚拟内存和物理内存之间进行地址转换。 * SETranslatingPortProxy 的构造函数参数包括一个线程上下文和一个转换策略(SETranslatingPortProxy::Always) */ initVirtMem.reset(new SETranslatingPortProxy( tc, SETranslatingPortProxy::Always)); // 将可执行文件加载到目标内存 /* 调用 image 和 interpImage 的 write 方法,将可执行文件和解释器的映像写入目标内存。 * initVirtMem 代理用于执行实际的内存写入操作 */ image.write(*initVirtMem); interpImage.write(*initVirtMem);}
drain
用于在进程的排空操作(drain operation)中更新文件描述符的文件偏移,并返回一个表示排空状态的值
xxxxxxxxxxDrainStateProcess::drain(){ fds->updateFileOffsets(); return DrainState::Drained;}
allocateMem
用于分配虚拟内存,并将其映射到物理内存。它处理内存页的对齐、查重和映射操作。
xxxxxxxxxxvoidProcess::allocateMem(Addr vaddr, int64_t size, bool clobber){ const auto page_size = pTable->pageSize(); //获取当前页表的页面大小。 // roundDown: This function is used to align addresses in memory. const Addr page_addr = roundDown(vaddr, page_size);// 将虚拟地址对齐到页面边界 // Check if the page has been mapped by other cores if not to clobber. // When running multithreaded programs in SE-mode with DerivO3CPU model, // there are cases where two or more cores have page faults on the same // page in nearby ticks. When the cores try to handle the faults at the // commit stage (also in nearby ticks/cycles), the first core will ask for // a physical page frame to map with the virtual page. Other cores can // return if the page has been mapped and `!clobber`. // 检查页面是否已映射 /* 如果 clobber 为 false,则检查页面是否已映射。关于clobber,参见page_table map * 使用 pTable->lookup(page_addr) 查看页面表项是否存在。如果存在,打印警告信息并返回。 */ if (!clobber) { const EmulationPageTable::Entry *pte = pTable->lookup(page_addr); if (pte) { warn("Process::allocateMem: addr %#x already mapped\n", vaddr); return; } } // 使用 divCeil 函数计算所需的页面数量。 // divCeil(size, page_size) 确保即使 size 不是页面大小的整数倍,也能分配足够的页面。 const int npages = divCeil(size, page_size); // 调用 seWorkload->allocPhysPages(npages) 分配物理页面,返回物理地址 paddr。 const Addr paddr = seWorkload->allocPhysPages(npages); // 计算总页面大小 const Addr pages_size = npages * page_size; // 将虚拟地址映射到物理地址 /* 调用 pTable->map 将虚拟地址 page_addr 映射到物理地址 paddr, 映射的大小为 pages_size。映射标志根据 clobber 的值设置,如果 clobber 为 true,则使用 EmulationPageTable::Clobber,否则使用默认标志。 */ pTable->map(page_addr, paddr, pages_size, clobber ? EmulationPageTable::Clobber : EmulationPageTable::MappingFlags(0));}
replicatePage
将一个虚拟地址对应的物理页面复制到新的物理页面,并在新的线程上下文中进行映射。函数支持条件性分配新的物理页面,并复制页面内容
xxxxxxxxxxvoidProcess::replicatePage(Addr vaddr, Addr new_paddr, ThreadContext *old_tc, ThreadContext *new_tc, bool allocate_page){ // 如果 allocate_page 为 true,则从工作负载中分配一个新的物理页面,并更新 new_paddr。 if (allocate_page) new_paddr = seWorkload->allocPhysPages(1); // 读取旧物理页面的内容. // 定义一个缓冲区 buf_p,其大小与页面大小相同 // 使用 SETranslatingPortProxy 对象和旧的线程上下文 old_tc,从虚拟地址 vaddr 读取页面内容到缓冲区 buf_p。 uint8_t buf_p[pTable->pageSize()]; SETranslatingPortProxy(old_tc).readBlob(vaddr, buf_p, sizeof(buf_p)); // Create new mapping in process address space by clobbering existing // mapping (if any existed) and then write to the new physical page. // 在进程地址空间中创建新的映射 // 使用页表 pTable 将虚拟地址 vaddr 映射到新的物理地址 new_paddr,覆盖(clobber)任何现有的映射 bool clobber = true; pTable->map(vaddr, new_paddr, sizeof(buf_p), clobber); // 使用 SETranslatingPortProxy 对象和新的线程上下文 new_tc, // 将缓冲区 buf_p 中的内容写入虚拟地址 vaddr 对应的新物理页面。 SETranslatingPortProxy(new_tc).writeBlob(vaddr, buf_p, sizeof(buf_p));}
fixupFault
xxxxxxxxxxboolProcess::fixupFault(Addr vaddr){ return memState->fixupFault(vaddr);}
serialize
用于将进程的状态序列化到检查点输出流 CheckpointOut &cp 中
xxxxxxxxxxvoidProcess::serialize(CheckpointOut &cp) const{ // 调用 memState 对象的 serialize 方法,将进程的内存状态序列化到检查点输出流 cp 中。 memState->serialize(cp); // 调用 pTable 对象的 serialize 方法,将进程的页表信息序列化到检查点输出流 cp 中。 pTable->serialize(cp); // 调用 fds 对象的 serialize 方法,将进程的文件描述符表信息序列化到检查点输出流 cp 中 fds->serialize(cp); // 输出一条警告消息,提示当前实现中不支持管道、设备驱动和套接字的检查点功能 warn("Checkpoints for pipes, device drivers and sockets do not work.");}
unserialize
xxxxxxxxxxvoidProcess::unserialize(CheckpointIn &cp){ memState->unserialize(cp); pTable->unserialize(cp); fds->unserialize(cp, this); warn("Checkpoints for pipes, device drivers and sockets do not work."); // The above returns a bool so that you could do something if you don't // find the param in the checkpoint if you wanted to, like set a default // but in this case we'll just stick with the instantiated value if not // found.}
map
xxxxxxxxxxboolProcess::map(Addr vaddr, Addr paddr, int64_t size, bool cacheable){ pTable->map(vaddr, paddr, size, cacheable ? EmulationPageTable::MappingFlags(0) : EmulationPageTable::Uncacheable); return true;}
findDriver
xxxxxxxxxxEmulatedDriver *Process::findDriver(std::string filename){ for (EmulatedDriver *d : drivers) { if (d->match(filename)) return d; } return nullptr;}
checkPathRedirect
用于检查给定文件名 filename 是否需要进行路径重定向,并返回重定向后的路径
xxxxxxxxxxstd::stringProcess::checkPathRedirect(const std::string &filename){ // If the input parameter contains a relative path, convert it. // The target version of the current working directory is fine since // we immediately convert it using redirect paths into a host version. // 调用 absolutePath 函数获取文件名 filename 的绝对路径,false 参数表示不展开符号链接 auto abs_path = absolutePath(filename, false); // 遍历系统中配置的所有重定向路径 redirectPaths for (auto path : system->redirectPaths) { // Search through the redirect paths to see if a starting substring of // our path falls into any buckets which need to redirected. // 如果 `abs_path` 以当前重定向路径 `path` 的应用程序路径 `appPath` 开头,则提取出剩余的路径作为 `tail`。 if (startswith(abs_path, path->appPath())) { std::string tail = abs_path.substr(path->appPath().size()); // If this path needs to be redirected, search through a list // of targets to see if we can match a valid file (or directory). // 搜索可用的主机路径 for (auto host_path : path->hostPaths()) { // 对于当前重定向路径 path 的每个主机路径 host_path,构建完整路径 full_path。 // 使用 access 函数检查 full_path 是否可读,如果可读,则返回该路径作为重定向后的路径。 if (access((host_path + tail).c_str(), R_OK) == 0) { // Return the valid match. return host_path + tail; } } // The path needs to be redirected, but the file or directory // does not exist on the host filesystem. Return the first // host path as a default. // 如果没有找到可读的主机路径,则返回当前重定向路径 path 的第一个主机路径加上 tail 作为默认路径 return path->hostPaths()[0] + tail; } } // The path does not need to be redirected. return abs_path;}
updateBias
主要用于更新进程的加载偏移量(bias),以便在加载可重定位的解释器时调整内存映射区域
xxxxxxxxxxvoidProcess::updateBias(){ // 通过 objFile 获取当前进程的解释器对象 auto *interp = objFile->getInterpreter(); // 如果解释器不存在或者不是可重定位的,则直接返回,因为不需要进行偏移量调整 if (!interp || !interp->relocatable()) return; // Determine how large the interpreters footprint will be in the process // address space. // 计算解释器在进程地址空间中的映射大小,并对其进行页对齐(使用 roundUp 函数 Addr interp_mapsize = roundUp(interp->mapSize(), pTable->pageSize()); // We are allocating the memory area; set the bias to the lowest address // in the allocated memory region. // 获取当前进程的 mmap 结束地址,即进程地址空间中的最后一个地址 Addr mmap_end = memState->getMmapEnd(); // 根据进程地址空间的增长方向(mmapGrowsDown()), // 计算解释器应该加载的偏移量 ld_bias。如果地址空间向下增长, // 则 ld_bias 是 mmap_end - interp_mapsize;否则,ld_bias 就是 mmap_end Addr ld_bias = mmapGrowsDown() ? mmap_end - interp_mapsize : mmap_end; // Adjust the process mmap area to give the interpreter room; the real // execve system call would just invoke the kernel's internal mmap // functions to make these adjustments. // 根据地址空间的增长方向,调整 mmap_end 的值,确保为解释器腾出空间 mmap_end = mmapGrowsDown() ? ld_bias : mmap_end + interp_mapsize; // 将更新后的 mmap_end 设置回 memState,以记录进程地址空间的最后地址 memState->setMmapEnd(mmap_end); // 调用解释器对象的 updateBias 方法,传入计算得到的加载偏移量 ld_bias,以更新解释器在进程中的加载位置。 interp->updateBias(ld_bias);}适应可重定位解释器:用于在加载可重定位的解释器时,调整进程的地址空间,确保解释器能够正确加载并运行。
计算偏移量:根据解释器的大小和进程地址空间的可用空间,计算出解释器应该加载的偏移量。
更新地址空间:通过调整 mmap_end 和更新 memState,确保解释器能够在正确的地址范围内加载。
这段代码关键在于处理进程在加载可重定位解释器时的内存管理问题,确保系统可以正确地调整和分配地址空间以支持解释器的加载和执行
getInterpreter
xxxxxxxxxxloader::ObjectFile *Process::getInterpreter(){ return objFile->getInterpreter();}
getBias
xxxxxxxxxxAddrProcess::getBias(){ auto *interp = getInterpreter(); return interp ? interp->bias() : objFile->bias();}
getStartPC
xxxxxxxxxxAddrProcess::getStartPC(){ auto *interp = getInterpreter(); return interp ? interp->entryPoint() : objFile->entryPoint();}
absolutePath
xxxxxxxxxxstd::stringProcess::absolutePath(const std::string &filename, bool host_filesystem){ // 如果 filename 是空的或者已经以 '/' 开头,则直接返回 filename,因为它已经是绝对路径 if (filename.empty() || startswith(filename, "/")) return filename; // Construct the absolute path given the current working directory for // either the host filesystem or target filesystem. The distinction only // matters if filesystem redirection is utilized in the simulation. // 根据 host_filesystem 参数决定使用主机文件系统 (hostCwd) 还是目标文件系统 (tgtCwd) 的当前工作目录作为基础路径 auto path_base = std::string(); if (host_filesystem) { path_base = hostCwd; assert(!hostCwd.empty()); } else { path_base = tgtCwd; assert(!tgtCwd.empty()); } // 调用 normalize 函数,确保基础路径 path_base 以 '/' 结尾,以确保路径的正确性和一致性。 // Add a trailing '/' if the current working directory did not have one. path_base = normalize(path_base); // 将文件名 filename 连接到基础路径 path_base 后面,形成完整的绝对路径 absolute_path // Append the filename onto the current working path. auto absolute_path = path_base + filename; return absolute_path;}主机文件系统与目标文件系统
在虚拟化或模拟环境中,通常会涉及到两种不同的文件系统概念:主机文件系统(Host File System)和目标文件系统(Target File System)。它们的区别在于它们所处的上下文和角色
主机文件系统(Host File System)
定义:
主机文件系统指的是运行虚拟化或模拟的物理机器上的实际文件系统。这是实际硬件或操作系统提供的文件系统,例如在服务器或个人电脑上的本地文件系统。
用途:
主机文件系统用于存储和管理主机上的所有文件和目录,包括操作系统文件、应用程序、用户数据等。它是物理机器上的实际存储结构,虚拟化或模拟的环境中可以访问和操作这些文件。
示例:
如果你在一台运行Linux操作系统的服务器上运行虚拟机,那么主机文件系统就是该服务器上的Linux文件系统,包括
/home、/var、/usr等目录。
目标文件系统(Target File System)
定义:
目标文件系统指的是在虚拟化或模拟环境中运行的虚拟或模拟系统内部的文件系统。这是虚拟化或模拟环境中提供给虚拟机或模拟器使用的文件系统抽象。
用途:
目标文件系统通常是一个虚拟的或模拟的文件系统,它可以是在内存中模拟的,也可以是在宿主文件系统上的一部分虚拟映像文件。虚拟机或模拟器中的应用程序和操作系统会认为它们在访问和操作真实文件系统一样访问和操作目标文件系统。
示例:
如果你在QEMU模拟器中运行一个ARM架构的Linux内核,那么目标文件系统就是QEMU虚拟出来的文件系统,这个文件系统可能是在宿主文件系统上的一个镜像文件,例如
.img文件,包含模拟的根文件系统结构。
在模拟环境中,比如模拟器或虚拟机,需要处理这两种文件系统,以便正确地模拟和管理应用程序的文件访问和操作,从而确保在模拟的环境中能够正确地运行和调试应用程序。
ProcessParams::create()
xxxxxxxxxxProcess *ProcessParams::create() const{ // If not specified, set the executable parameter equal to the // simulated system's zeroth command line parameter // 确定可执行文件路径: // 如果没有指定 executable 参数,则使用 cmd 数组的第一个参数作为可执行文件路径 exec const std::string &exec = (executable == "") ? cmd[0] : executable; // 调用 loader::createObjectFile 函数,根据 exec 路径创建对象文件 obj_file auto *obj_file = loader::createObjectFile(exec); fatal_if(!obj_file, "Cannot load object file %s.", exec); // 调用 Process::tryLoaders 函数,尝试使用当前 ProcessParams 对象和加载的对象文件 obj_file 创建进程对象 process Process *process = Process::tryLoaders(*this, obj_file); fatal_if(!process, "Unknown error creating process object."); return process;}
packet
不包含所有的代码
getAddrRange
xxxxxxxxxxAddrRangePacket::getAddrRange() const{ return RangeSize(getAddr(), getSize());}
trySatisfyFunctional
用于尝试通过功能访问(functional access)满足对数据包的操作。该函数的主要功能是检查数据包与传入的数据范围是否有交集,并根据数据包的类型(读或写)来处理数据。
Printable *obj:一个可打印的对象,用于打印请求的状态。
Addr addr:起始地址。
bool is_secure:安全标志,表示是否是安全访问。
int size:数据的大小。
uint8_t *_data:指向数据的指针。
xxxxxxxxxxboolPacket::trySatisfyFunctional(Printable *obj, Addr addr, bool is_secure, int size, uint8_t *_data){ // 当前数据包的起始和结束地址 const Addr func_start = getAddr(); const Addr func_end = getAddr() + getSize() - 1; // 传入的数据范围的起始和结束地址 const Addr val_start = addr; const Addr val_end = val_start + size - 1; // 如果安全标志不匹配或者地址范围没有交集,则返回 false。 if (is_secure != _isSecure || func_start > val_end || val_start > func_end) { // no intersection return false; } // check print first since it doesn't require data // 如果请求是打印类型,不需要数据,仅进行打印操作 if (isPrint()) { assert(!_data); safe_cast<PrintReqState*>(senderState)->printObj(obj); return false; } // we allow the caller to pass NULL to signify the other packet // has no data // 如果传入的数据指针为空,则返回 false if (!_data) { return false; } // 计算重叠区域 // val_offset 和 func_offset:分别表示重叠区域在传入数据和当前数据包中的偏移 const Addr val_offset = func_start > val_start ? func_start - val_start : 0; const Addr func_offset = func_start < val_start ? val_start - func_start : 0; // overlap_size:重叠区域的大小 const Addr overlap_size = std::min(val_end, func_end)+1 - std::max(val_start, func_start); // 处理读操作 // 如果是读操作,将数据从传入的数据范围复制到当前数据包中,并更新有效字节的跟踪 // 最后返回是否所有字节都有效 if (isRead()) { std::memcpy(getPtr<uint8_t>() + func_offset, _data + val_offset, overlap_size); // initialise the tracking of valid bytes if we have not // used it already // 它确保在第一次使用该数组时,将其大小调整为数据包的大小,并将所有元素初始化为 false if (bytesValid.empty()) bytesValid.resize(getSize(), false); // track if we are done filling the functional access bool all_bytes_valid = true; int i = 0; // check up to func_offset // 检查 func_offset 之前的字节 // 这个循环从索引 0 开始,一直到 func_offset,检查在此之前的所有字节是否都已经有效。 // all_bytes_valid 初始化为 true,表示假设所有字节都是有效的。 // 在循环中,如果 bytesValid[i] 为 false,则 all_bytes_valid 也会变为 false。 // 这个操作保证了只要有一个字节无效,all_bytes_valid 就会变成 false 并保持不变。 for (; all_bytes_valid && i < func_offset; ++i) all_bytes_valid &= bytesValid[i]; // update the valid bytes // 更新有效字节 // 这个循环从 func_offset 开始,一直到 func_offset + overlap_size,将重叠区域中的字节标记为有效。 // 这意味着这些字节已经成功读取,并被标记为有效 for (i = func_offset; i < func_offset + overlap_size; ++i) bytesValid[i] = true; // check the bit after the update we just made // 检查更新之后的字节 // 这个循环从 func_offset + overlap_size 开始,一直到数据包的末尾,检查在更新之后的所有字节是否都有效 for (; all_bytes_valid && i < getSize(); ++i) all_bytes_valid &= bytesValid[i]; return all_bytes_valid; } else if (isWrite()) {// 处理写操作:如果是写操作,将数据从当前数据包复制到传入的数据范围 std::memcpy(_data + val_offset, getConstPtr<uint8_t>() + func_offset, overlap_size); } else { panic("Don't know how to handle command %s\n", cmdString()); } // keep going with request by default return false;}
xxxxxxxxxxvoid* memcpy(void* dest, const void* src, std::size_t count);
void* dest:目标地址的指针,表示数据将被复制到的内存地址。
const void* src:源地址的指针,表示数据将从这里开始复制。
std::size_t count:要复制的字节数。返回目标地址
dest的指针。
copyResponderFlags
xxxxxxxxxxvoidPacket::copyResponderFlags(const PacketPtr pkt){ // 断言当前数据包是一个请求包。这意味着这个方法只能在请求包上调用。 assert(isRequest()); // If we have already found a responder, no other cache should // commit to responding // 这个断言检查两个条件:要么传入的 pkt 没有响应,要么当前数据包没有响应。两个都响应会导致冲突 assert(!pkt->cacheResponding() || !cacheResponding()); // pkt->flags & RESPONDER_FLAGS:使用按位与运算符 & 提取 pkt 中的响应者标志 flags.set(pkt->flags & RESPONDER_FLAGS);} xxxxxxxxxx // Flags that are used to create reponse packets RESPONDER_FLAGS = 0x00000009,xxxxxxxxxx // Snoop co-ordination flag to indicate that a cache is // responding to a snoop. See setCacheResponding below. CACHE_RESPONDING = 0x00000008,嗅探协调: 嗅探(snoop)是多处理器系统中缓存一致性协议的一部分。在这种协议中,处理器或缓存会嗅探(检查)总线上传输的消息,以确定它们是否需要响应或采取行动。
CACHE_RESPONDING 标志用于指示缓存是否正在响应嗅探请求。如果某个缓存设置了这个标志,意味着它对当前嗅探请求做出了响应。
xxxxxxxxxxassert(!pkt->cacheResponding() || !cacheResponding());断言确保在执行 copyResponderFlags 方法时,不能有多个缓存同时对嗅探请求响应。这是为了避免缓存一致性协议中的冲突
pushSenderState
用于管理 Packet 对象的 SenderState 栈。SenderState 是与数据包相关联的一些状态信息,通常用于跟踪数据包在系统中的路径和状态变化。
xxxxxxxxxxvoidPacket::pushSenderState(Packet::SenderState *sender_state){ // 这确保了在后续操作中不会出现空指针解引用的错误 assert(sender_state != NULL); // 这一行代码将当前的 senderState 保存到新 sender_state 的 predecessor 成员中 // predecessor 是一个指针,指向上一个 SenderState 对象,这样可以形成一个链表结构,追踪数据包经过的所有状态。 sender_state->predecessor = senderState; // 更新 senderState senderState = sender_state;}在 Packet 类中,SenderState 通常用于保存和恢复与数据包相关联的状态信息。当数据包在系统中传递时,它可能经过多个组件,每个组件可能会修改数据包的状态。在这种情况下,使用 pushSenderState 方法可以将当前状态保存起来,以便在处理完成后恢复。
popSenderState
用于从 Packet 对象的状态栈中弹出一个 SenderState 对象,并返回该对象。这个方法与 pushSenderState 方法相对应,用于恢复之前保存的状态。
xxxxxxxxxxPacket::SenderState *Packet::popSenderState(){ // 使用 assert 检查 senderState 指针是否不为 NULL。如果 senderState 为 NULL,程序将在调试模式下中断。 // 这确保了在后续操作中不会出现空指针解引用的错误 assert(senderState != NULL); // 将当前的 senderState 保存到局部变量 sender_state 中,这样可以暂存当前的状态,准备返回给调用者。 SenderState *sender_state = senderState; // 将 senderState 更新为当前 sender_state 的 predecessor,即前一个状态 // 这相当于从状态栈中弹出一个状态,恢复到之前的状态 senderState = sender_state->predecessor; // 将弹出的 sender_state 的 predecessor 设置为 NULL // 这样做是为了断开与之前状态的链接,防止不必要的引用保持。 sender_state->predecessor = NULL; return sender_state;}这个方法与 pushSenderState 方法一起使用,可以有效管理 Packet 对象的状态栈,保存和恢复数据包的状态信息。
getUintX
于从数据包中获取指定大小的无符号整数,并根据指定的字节序(大小端序)进行转换
xxxxxxxxxxuint64_tPacket::getUintX(ByteOrder endian) const{ auto [val, success] = gem5::getUintX(getConstPtr<void>(), getSize(), endian); panic_if(!success, "%i isn't a supported word size.\n", getSize()); return val;}调用
gem5::getUintX函数来从数据包中获取无符号整数。getConstPtr<void>()返回数据包的常量指针,指向数据包的内存起始地址。getSize()返回数据包的大小。endian是一个枚举值,表示字节序(大端或小端)。
这个方法依赖于 gem5 库中的 getUintX 函数,它的作用是根据指定的字节序从给定地址的内存中提取指定大小的无符号整数。具体实现可能会根据不同的字节序处理数据的排列顺序
例子:
假设 getConstPtr<void>() 返回指向内存地址 0x1000 的常量指针,getSize() 返回 4,endian 是 ByteOrder::little_endian(小端序)。
调用 getUintX 方法将从地址 0x1000 开始的 4 个字节解析为一个小端序的无符号整数,并将其作为 uint64_t 类型返回。
字节序(Byte Order)是指在存储或传输多字节数据时,字节的排列顺序。主要有两种常见的字节序,即大端序(Big Endian)和小端序(Little Endian),它们区别在于字节的高位(Most Significant Byte,MSB)和低位(Least Significant Byte,LSB)的存储顺序。
在大端序中,数据的高位字节(MSB)存储在低地址,低位字节(LSB)存储在高地址。这意味着在内存中,数据的各个字节按照从高地址到低地址的顺序排列。例如,一个 32 位整数
0x12345678在内存中的存储顺序如下(地址从低到高):xxxxxxxxxx地址: 0x1000 0x1001 0x1002 0x1003数据: 0x12 0x34 0x56 0x78
在小端序中,数据的低位字节(LSB)存储在低地址,高位字节(MSB)存储在高地址。因此,数据的各个字节按照从低地址到高地址的顺序排列。以同样的 32 位整数
0x12345678为例,在小端序中的存储顺序如下:xxxxxxxxxx地址: 0x1000 0x1001 0x1002 0x1003数据: 0x78 0x56 0x34 0x12
x86 架构使用小端序,而 PowerPC 和大多数 RISC 架构使用大端序。在网络上传输数据,可以使用网络字节序(通常是大端序),例如使用
htonl(主机到网络长整型)和ntohl(网络到主机长整型)等函数
setUintX
xxxxxxxxxxvoidPacket::setUintX(uint64_t w, ByteOrder endian){ bool success = gem5::setUintX(w, getPtr<void>(), getSize(), endian); panic_if(!success, "%i isn't a supported word size.\n", getSize());}
用于将 Packet 对象的信息输出到给定的输出流 o 中,以便调试或日志记录目的
xxxxxxxxxxvoidPacket::print(std::ostream &o, const int verbosity, const std::string &prefix) const{ ccprintf(o, "%s%s [%x:%x]%s%s%s%s%s%s", prefix, cmdString(), getAddr(), getAddr() + getSize() - 1, req->isSecure() ? " (s)" : "", req->isInstFetch() ? " IF" : "", req->isUncacheable() ? " UC" : "", isExpressSnoop() ? " ES" : "", req->isToPOC() ? " PoC" : "", req->isToPOU() ? " PoU" : "");}o:一个std::ostream的引用,表示输出流,用于将信息输出到指定的输出设备(如控制台、文件)。verbosity:一个整数,用于指定输出详细程度的级别,但在这段代码中并没有直接使用。prefix:一个std::string的引用,表示输出信息的前缀,用于标识或区分不同的输出信息。
print()
xxxxxxxxxxstd::stringPacket::print() const { std::ostringstream str; print(str); // 调用 std::ostringstream 的 str() 方法,将流中的数据作为 std::string 返回 return str.str();}创建了一个
std::ostringstream对象str,它是一个输出字符串流。std::ostringstream类提供了一个内存缓冲区,可以将各种数据类型的数据以字符串的形式输出到其中。调用
Packet类中的另一个print方法,传递str作为输出流。这里利用了函数重载的特性,将字符串输出的操作委托给了前面解释过的print(std::ostream &o)方法
matchBlockAddr
用于检查当前数据包是否匹配给定的块地址和安全性标志
xxxxxxxxxxboolPacket::matchBlockAddr(const Addr addr, const bool is_secure, const int blk_size) const{ return (getBlockAddr(blk_size) == addr) && (isSecure() == is_secure);}xxxxxxxxxx Addr getBlockAddr(unsigned int blk_size) const { return getAddr() & ~(Addr(blk_size - 1)); }getAddr():调用Packet类中的getAddr方法,获取当前数据包的地址。blk_size - 1:计算块大小减一。Addr(blk_size - 1):将块大小减一转换为Addr类型,这里假设Addr是一个整数类型,通常用于表示地址。~(Addr(blk_size - 1)):对Addr(blk_size - 1)取反,即按位取反操作,得到一个掩码,该掩码用于将地址的低位块地址部分清零。getAddr() & ~(Addr(blk_size - 1)):使用按位与操作,将getAddr()的地址值与上述掩码进行按位与操作,从而得到块地址。假设
pkt的地址是0x12345678,并且blockSize是64,那么根据上述计算:blk_size - 1将是63。~(Addr(63))按位取反后的结果将是一个掩码,例如0xFFFFFFFFFFFFFFC0。getAddr() & ~(Addr(63))将是0x12345678 & 0xFFFFFFFFFFFFFFC0,结果将是0x12345600,这就是计算得到的块地址。
matchBlockAddr
这段代码是 Packet 类中的 matchBlockAddr 方法的重载版本,接受一个 PacketPtr 类型的参数 pkt 和一个 int 类型的参数 blk_size。它用于检查当前数据包是否与另一个数据包 pkt 的块地址和安全性匹配。
pkt:一个 PacketPtr,即指向 Packet 对象的智能指针。
blk_size:一个 int,表示块大小
xxxxxxxxxxboolPacket::matchBlockAddr(const PacketPtr pkt, const int blk_size) const{ return matchBlockAddr(pkt->getBlockAddr(blk_size), pkt->isSecure(), blk_size);}pkt->getBlockAddr(blk_size):调用 pkt 指向的 Packet 对象的 getBlockAddr 方法,获取 pkt 的块地址。
pkt->isSecure():调用 pkt 指向的 Packet 对象的 isSecure 方法,获取 pkt 的安全性。
matchBlockAddr(addr, is_secure, blk_size):调用当前对象的另一个 matchBlockAddr 方法,传递 pkt 的块地址、安全性和给定的块大小作为参数。
这段代码允许比较当前
Packet对象与另一个Packet对象pkt的块地址和安全性。这在处理器缓存管理或其他涉及地址对齐和安全性匹配的系统级操作中非常有用。
matchAddr
用于比较当前数据包的地址和安全性标志是否与给定的地址和安全性标志匹配
xxxxxxxxxxboolPacket::matchAddr(const Addr addr, const bool is_secure) const{ return (getAddr() == addr) && (isSecure() == is_secure);}这段代码通常用于数据包处理的逻辑中,特别是在需要确定数据包的目标地址和访问权限时非常有用。例如,在处理器或网络设备的数据包路由和权限控制中,可以使用这种方法来验证数据包是否符合预期的目标地址和访问权限。
matchAddr
这段代码是 Packet 类中的 matchAddr 方法的一个重载版本,接受一个 PacketPtr 类型的指针参数,并使用其指向的 Packet 对象的地址和安全性标志来调用另一个 matchAddr 方法进行比较。
xxxxxxxxxxboolPacket::matchAddr(const PacketPtr pkt) const{ return matchAddr(pkt->getAddr(), pkt->isSecure());}这段代码允许比较当前 Packet 对象与另一个 Packet 对象 pkt 的地址和安全性标志。这在处理器缓存管理、网络数据包路由或其他需要比较地址和安全性的场景中非常有用.
PrintReqState::PrintReqState
段代码定义了 Packet::PrintReqState 类的构造函数
PrintReqState 是 Packet 类的一个嵌套类或成员类。这种结构在软件设计中常见,允许将相关的功能和数据组织在一起,提高代码的模块化和可维护性
xxxxxxxxxxPacket::PrintReqState::PrintReqState(std::ostream &_os, int _verbosity) : curPrefixPtr(new std::string("")), os(_os), verbosity(_verbosity){ // 通过传递空字符串 "" 和 curPrefixPtr(指向空字符串的指针)来创建一个 LabelStackEntry 对象 // 并加入labelStack labelStack.push_back(LabelStackEntry("", curPrefixPtr));}curPrefixPtr(new std::string("")):curPrefixPtr是一个指向std::string的指针。
通过
new std::string("")创建了一个空的std::string对象,并将其地址赋给curPrefixPtr。这意味着
curPrefixPtr指向了一个新分配的空字符串对象。
os(_os):os是一个引用类型的成员变量,初始化为传入的_os(即外部传入的std::ostream对象)。
verbosity(_verbosity):verbosity是一个int类型的成员变量,初始化为传入的_verbosity。
xxxxxxxxxxPacket::PrintReqState::LabelStackEntry::LabelStackEntry(const std::string &_label, std::string *_prefix) : label(_label), prefix(_prefix), labelPrinted(false){}
PrintReqState::pushLabel
lbl:一个 const std::string& 类型的引用,表示要推入的标签。
prefix:一个 const std::string& 类型的引用,表示要添加到当前前缀字符串末尾的前缀内容。
xxxxxxxxxxvoidPacket::PrintReqState::pushLabel(const std::string &lbl, const std::string &prefix){ // 将标签推入 labelStack labelStack.push_back(LabelStackEntry(lbl, curPrefixPtr)); // 更新当前前缀字符串指针 curPrefixPtr = new std::string(*curPrefixPtr); *curPrefixPtr += prefix;}PrintReqState::popLabel
xxxxxxxxxxvoidPacket::PrintReqState::popLabel(){ delete curPrefixPtr; curPrefixPtr = labelStack.back().prefix; labelStack.pop_back(); assert(!labelStack.empty());}PrintReqState::printLabels
xxxxxxxxxxvoidPacket::PrintReqState::printLabels(){ if (!labelStack.back().labelPrinted) { LabelStack::iterator i = labelStack.begin(); LabelStack::iterator end = labelStack.end(); while (i != end) { if (!i->labelPrinted) { ccprintf(os, "%s%s\n", *(i->prefix), i->label); i->labelPrinted = true; } i++; } }}
makeHtmTransactionalReqResponse
用于将一个HTM(硬件事务内存)事务请求转换为响应,并设置相应的状态码
xxxxxxxxxxvoidPacket::makeHtmTransactionalReqResponse( const HtmCacheFailure htm_return_code){ // 确保当前数据包需要响应。如果数据包不需要响应,则会触发断言失败,程序终止 assert(needsResponse()); // 确保当前数据包是一个请求。如果数据包不是请求,则会触发断言失败,程序终止 assert(isRequest()); // 将当前数据包的命令类型转换为响应命令类型。responseCommand 方法根据请求命令类型返回相应的响应命令类型。 cmd = cmd.responseCommand(); // 设置HTM事务在缓存中失败的返回代码。htm_return_code 是一个 HtmCacheFailure 类型的参数,表示HTM事务的失败原因 setHtmTransactionFailedInCache(htm_return_code); // responses are never express, even if the snoop that // triggered them was // 清除 EXPRESS_SNOOP 标志。即使触发响应的嗅探是快速的,响应也从不快速 flags.clear(EXPRESS_SNOOP);}硬件事务内存(Hardware Transactional Memory,HTM)是一种并行编程技术,它允许程序员使用事务的概念来管理内存操作,从而简化并发编程并提高性能。HTM的主要目标是提高多线程程序的性能,同时简化对共享数据的访问。
事务:
类似于数据库中的事务,HTM中的事务是一组要么全部执行,要么全部回滚的操作。事务保证了操作的原子性和一致性。
内存冲突检测:
在事务执行期间,硬件会监视内存访问以检测冲突。如果多个事务同时访问相同的内存位置并且至少有一个是写操作,硬件将检测到冲突并回滚其中的一个或多个事务。
回滚和重试:
如果事务冲突或遇到其他问题(如缓存溢出),硬件会回滚事务的所有操作。程序可以选择重试事务。
原子性:
事务中的所有操作要么全部成功并提交,要么全部回滚,保持系统状态的一致性
setHtmTransactionFailedInCache
用于设置 HTM(硬件事务内存)事务在缓存中失败的返回代码,并根据情况标记事务失败的标志
htm_return_code 是一个 HtmCacheFailure 枚举类型的参数,表示 HTM 事务在缓存中失败的具体原因
xxxxxxxxxxvoidPacket::setHtmTransactionFailedInCache( const HtmCacheFailure htm_return_code){ // 检查 htm_return_code 是否为 NO_FAIL。NO_FAIL 通常表示没有发生失败 if (htm_return_code != HtmCacheFailure::NO_FAIL) // 如果 htm_return_code 不等于 NO_FAIL,则设置数据包的 FAILS_TRANSACTION 标志,表明该数据包对应的事务失败 flags.set(FAILS_TRANSACTION); // 将 htm_return_code 赋值给数据包的 htmReturnReason 成员变量,记录事务失败的具体原因。 htmReturnReason = htm_return_code;}假设我们有一个 HTM 事务请求数据包 pkt,并且事务在缓存中失败,失败原因是 HtmCacheFailure::CACHE_MISS。可以这样调用该函数:
Packet pkt;HtmCacheFailure htm_cache_failure = HtmCacheFailure::CACHE_MISS;pkt.setHtmTransactionFailedInCache(htm_cache_failure);
htmTransactionFailedInCache
检查数据包的 FAILS_TRANSACTION 标志是否被设置,判断事务是否在缓存中失败。
x
boolPacket::htmTransactionFailedInCache() const{ return flags.isSet(FAILS_TRANSACTION);}getHtmTransactionFailedInCacheRC
返回 HTM 事务在缓存中失败的原因。
xxxxxxxxxxHtmCacheFailurePacket::getHtmTransactionFailedInCacheRC() const{ assert(htmTransactionFailedInCache()); return htmReturnReason;}setHtmTransactional
设置数据包为 HTM 事务包,并存储事务的唯一标识符(UID)。
xxxxxxxxxxvoidPacket::setHtmTransactional(uint64_t htm_uid){ flags.set(FROM_TRANSACTION); htmTransactionUid = htm_uid;}isHtmTransactional
检查数据包是否是 HTM 事务包。
x
boolPacket::isHtmTransactional() const{ return flags.isSet(FROM_TRANSACTION);}getHtmTransactionUid
返回 HTM 事务包的唯一标识符(UID)。
x
uint64_tPacket::getHtmTransactionUid() const{ assert(flags.isSet(FROM_TRANSACTION)); return htmTransactionUid;}
allocate
这段代码定义了 Packet 类中的 allocate 方法,用于为数据包分配内存。
xxxxxxxxxx/** Allocate memory for the packet. */ void allocate() { // if either this command or the response command has a data // payload, actually allocate space // 检查当前命令或响应命令是否有数据负载。如果有数据负载,则需要分配内存 if (hasData() || hasRespData()) { // 保证在分配内存之前,数据包没有使用静态或动态数据。 assert(flags.noneSet(STATIC_DATA|DYNAMIC_DATA)); // 设置 DYNAMIC_DATA 标志,表示数据包使用动态分配的数据。 flags.set(DYNAMIC_DATA); // 为数据包分配大小为 getSize() 的内存,并将指针存储在 data 成员变量中。 data = new uint8_t[getSize()]; } }为什么需要确保在分配内存之前,数据包没有使用静态或动态数据?
避免重复分配:
如果数据包已经使用了静态或动态数据(即已经分配了内存),再次调用
allocate方法可能会导致内存泄漏或内存重复分配,从而造成程序性能下降或内存使用不稳定。
数据包状态管理:
数据包对象可能会在其生命周期内多次调用
allocate方法或进行其他操作,为了确保对象状态的一致性和正确性,需要在分配内存之前清除已有的数据状态。这样可以确保每次分配都是基于当前对象的状态和需求进行的。
程序逻辑正确性:
程序设计上,通常会通过标志或状态来管理数据包是否已经分配了内存。在执行
allocate方法之前清除这些标志或状态是良好的编程实践,可以确保操作的顺序和执行的逻辑是正确的。
断言检查:
使用
assert(flags.noneSet(STATIC_DATA|DYNAMIC_DATA));的断言,可以在调试阶段检测和捕获潜在的错误状态。如果发现数据包已经使用了静态或动态数据,断言会触发,提醒开发者需要处理或调整代码逻辑。
deleteData
用于删除数据包中的数据,并清除相关的标志和指针
xxxxxxxxxx /** * delete the data pointed to in the data pointer. Ok to call to * matter how data was allocted. */ void deleteData() { // 如果数据包的 DYNAMIC_DATA 标志被设置,表示数据是通过动态分配内存得到的,那么调用 delete [] data; 将释放这块内存 if (flags.isSet(DYNAMIC_DATA)) delete [] data; // 清除 STATIC_DATA 和 DYNAMIC_DATA 标志,以确保数据包不再被标记为已分配静态或动态数据 flags.clear(STATIC_DATA|DYNAMIC_DATA); // 将 data 指针设置为 NULL,以避免在释放后意外访问已释放的内存地址 data = NULL; }
XBar
BaseXBar::BaseXBar
这段代码是一个构造函数实现,属于gem5模拟器中的 BaseXBar 类的构造函数。
xxxxxxxxxxBaseXBar::BaseXBar(const BaseXBarParams &p) : ClockedObject(p), frontendLatency(p.frontend_latency),// 前端延迟初始化 forwardLatency(p.forward_latency),// 转发延迟初始化 responseLatency(p.response_latency),// 响应延迟初始化 headerLatency(p.header_latency),// 头部延迟初始化 width(p.width),// 宽度(指并行处理能力)初始化 // gotAddrRanges的初始化,长度为两个连接数的和,默认初始化为false gotAddrRanges(p.port_default_connection_count + p.port_mem_side_ports_connection_count, false), // gotAllAddrRanges的初始化为false // 默认端口ID初始化为InvalidPortID gotAllAddrRanges(false), defaultPortID(InvalidPortID), // 是否使用默认范围的初始化 useDefaultRange(p.use_default_range), // 统计数据项transDist的初始化,用于记录事务分布 ADD_STAT(transDist, statistics::units::Count::get(), "Transaction distribution"), ADD_STAT(pktCount, statistics::units::Count::get(), "Packet count per connected requestor and responder"), ADD_STAT(pktSize, statistics::units::Byte::get(), "Cumulative packet size per connected requestor and responder"){}ClockedObject(p):调用了基类 ClockedObject 的构造函数,并使用参数 p 进行初始化。这表明 BaseXBar 类继承自 ClockedObject,具有时钟相关的行为和属性。
~BaseXBar
这段析构函数的作用是释放XBar设备管理的所有端口对象所占用的内存。这种方式确保在销毁XBar对象时,所有动态分配的资源都被正确地释放,防止内存泄漏和资源泄露问题。
xxxxxxxxxxBaseXBar::~BaseXBar(){ // 这个循环遍历存储在 memSidePorts 中的每个端口 for (auto port: memSidePorts) delete port; // 这个循环遍历存储在 cpuSidePorts 中的每个端口 for (auto port: cpuSidePorts) delete port;}~BaseXBar():这是 BaseXBar 类的析构函数,用于释放对象在其生命周期中动态分配的资源。
析构函数(Destructor)是一种特殊类型的成员函数,它在对象被销毁时自动调用,用于释放对象所持有的资源和执行清理工作。在C++中,析构函数的命名规则是在类名前加上波浪号
~,例如~ClassName()。
getPort
xxxxxxxxxxPort &BaseXBar::getPort(const std::string &if_name, PortID idx){ if (if_name == "mem_side_ports" && idx < memSidePorts.size()) { // the memory-side ports index translates directly to the vector // position return *memSidePorts[idx]; } else if (if_name == "default") { return *memSidePorts[defaultPortID]; } else if (if_name == "cpu_side_ports" && idx < cpuSidePorts.size()) { // the CPU-side ports index translates directly to the vector position return *cpuSidePorts[idx]; } else { return ClockedObject::getPort(if_name, idx); }}
calPacketTiming [NOT COMPLETED]
xxxxxxxxxxvoidBaseXBar::calcPacketTiming(PacketPtr pkt, Tick header_delay){ // the crossbar will be called at a time that is not necessarily // coinciding with its own clock, so start by determining how long // until the next clock edge (could be zero) Tick offset = clockEdge() - curTick(); // the header delay depends on the path through the crossbar, and // we therefore rely on the caller to provide the actual // value pkt->headerDelay += offset + header_delay; // note that we add the header delay to the existing value, and // align it to the crossbar clock // do a quick sanity check to ensure the timings are not being // ignored, note that this specific value may cause problems for // slower interconnects panic_if(pkt->headerDelay > sim_clock::as_int::us, "Encountered header delay exceeding 1 us\n"); if (pkt->hasData()) { // the payloadDelay takes into account the relative time to // deliver the payload of the packet, after the header delay, // we take the maximum since the payload delay could already // be longer than what this parcitular crossbar enforces. pkt->payloadDelay = std::max<Tick>(pkt->payloadDelay, divCeil(pkt->getSize(), width) * clockPeriod()); } // the payload delay is not paying for the clock offset as that is // already done using the header delay, and the payload delay is // also used to determine how long the crossbar layer is busy and // thus regulates throughput}
MemCtrl
这段代码是 MemCtrl 类的构造函数实现
xxxxxxxxxxMemCtrl::MemCtrl(const MemCtrlParams &p) : qos::MemCtrl(p), port(name() + ".port", *this), isTimingMode(false), retryRdReq(false), retryWrReq(false), nextReqEvent([this] {processNextReqEvent(dram, respQueue, respondEvent, nextReqEvent, retryWrReq);}, name()), respondEvent([this] {processRespondEvent(dram, respQueue, respondEvent, retryRdReq); }, name()), dram(p.dram), readBufferSize(dram->readBufferSize), writeBufferSize(dram->writeBufferSize), writeHighThreshold(writeBufferSize * p.write_high_thresh_perc / 100.0), writeLowThreshold(writeBufferSize * p.write_low_thresh_perc / 100.0), minWritesPerSwitch(p.min_writes_per_switch), minReadsPerSwitch(p.min_reads_per_switch), memSchedPolicy(p.mem_sched_policy), frontendLatency(p.static_frontend_latency), backendLatency(p.static_backend_latency), commandWindow(p.command_window), prevArrival(0), stats(*this){ DPRINTF(MemCtrl, "Setting up controller\n"); readQueue.resize(p.qos_priorities); writeQueue.resize(p.qos_priorities); dram->setCtrl(this, commandWindow); // perform a basic check of the write thresholds if (p.write_low_thresh_perc >= p.write_high_thresh_perc) fatal("Write buffer low threshold %d must be smaller than the " "high threshold %d\n", p.write_low_thresh_perc, p.write_high_thresh_perc); if (p.disable_sanity_check) { port.disableSanityCheck(); }}
init
确保 MemCtrl 对象的端口(port)已经连接,并在连接后执行相应的操作
sendRangeChange()用于获取所有者负责的非重叠地址范围列表
xxxxxxxxxxvoidMemCtrl::init(){ if (!port.isConnected()) { fatal("MemCtrl %s is unconnected!\n", name()); } else { port.sendRangeChange(); }}
startup
该方法的目的是在内存控制器启动时执行一些初始化操作,主要是针对内存操作模式进行设置和调整。
如果系统处于时序模式,将内存操作的下一个预计时间设置为当前模拟时钟周期加上一个命令偏移量,以确保在计算下一个请求的时间时不会出现负值,并在模拟开始时添加一个微小的延迟
xxxxxxxxxxvoidMemCtrl::startup(){ // 记住内存系统的操作模式 isTimingMode = system()->isTimingMode(); if (isTimingMode) { // 将总线忙时的时间向前移动足够远,这样在计算下一个请求的时间时不会出现负值 // 这将在模拟开始时增加一个微不足道的泡沫 dram->nextBurstAt = curTick() + dram->commandOffset(); }}
recvAtomic
用于接收处理来自其他组件(可能是处理器或其他设备)发送的原子操作数据包。它首先检查数据包的地址是否在内存控制器管理的DRAM地址范围内,然后调用 recvAtomicLogic() 方法继续处理数据包。
xxxxxxxxxxTickMemCtrl::recvAtomic(PacketPtr pkt){ if (!dram->getAddrRange().contains(pkt->getAddr())) { panic("Can't handle address range for packet %s\n", pkt->print()); } return recvAtomicLogic(pkt, dram);}
recvAtomicLogic
用于实际处理接收到的原子操作数据包,它执行实际的内存访问操作,并根据数据包是否包含数据返回相应的访问延迟时间.
xxxxxxxxxxTickMemCtrl::recvAtomicLogic(PacketPtr pkt, MemInterface* mem_intr){ DPRINTF(MemCtrl, "recvAtomic: %s 0x%x\n", pkt->cmdString(), pkt->getAddr()); // 参见之前关于嗅探和缓存一致性的相关内容 panic_if(pkt->cacheResponding(), "Should not see packets where cache " "is responding"); // do the actual memory access and turn the packet into a response // 调用 mem_intr(内存接口对象)的 access(pkt) 方法,执行实际的内存访问操作。 // 这一步将数据包转化为响应,处理具体的读写操作。 mem_intr->access(pkt); // 检查数据包是否包含数据 if (pkt->hasData()) { // 如果数据包包含数据,则返回内存接口的访问延迟时间 // mem_intr->accessLatency() 返回一个模拟访问延迟的值 // 这个值不需要非常精确,只需足够维持模拟进行,模仿关闭页面的情况。此外,这个延迟不能为0。 // this value is not supposed to be accurate, just enough to // keep things going, mimic a closed page // also this latency can't be 0 return mem_intr->accessLatency(); } // 数据包不包含数据,返回0表示没有延迟 return 0;}
关于mem_intr->access(pkt);,下面给出相关的函数
负责处理各种类型的内存访问请求
xxxxxxxxxxvoidAbstractMemory::access(PacketPtr pkt){ // 检查缓存响应 if (pkt->cacheResponding()) { DPRINTF(MemoryAccess, "Cache responding to %#llx: not responding\n", pkt->getAddr()); return; } // 处理 CleanEvict 和 WritebackClean 命令 if (pkt->cmd == MemCmd::CleanEvict || pkt->cmd == MemCmd::WritebackClean) { DPRINTF(MemoryAccess, "CleanEvict on 0x%x: not responding\n", pkt->getAddr()); return; } // 确保数据包的地址范围是内存范围的子集,如果不是,则触发断言失败 assert(pkt->getAddrRange().isSubset(range)); // 获取主机地址 uint8_t *host_addr = toHostAddr(pkt->getAddr()); // 检查数据包的命令类型是否为 SwapReq。处理 Swap 请求 if (pkt->cmd == MemCmd::SwapReq) { // 处理 Swap 请求,如果是原子操作,则执行原子操作 if (pkt->isAtomicOp()) { if (pmemAddr) {// 存在物理内存地址(pmemAddr) pkt->setData(host_addr);// 调用 pkt->setData(host_addr) 将数据设置为内存中的当前值 // 执行原子操作((*(pkt->getAtomicOp()))(host_addr)),直接操作内存地址。 (*(pkt->getAtomicOp()))(host_addr); } } else {。 // 创建一个 std::vector<uint8_t> 来保存要写入的值。 std::vector<uint8_t> overwrite_val(pkt->getSize()); // 定义条件值变量(condition_val64 和 condition_val32) uint64_t condition_val64; uint32_t condition_val32; // 检查是否存在物理内存地址,如果没有,则触发致命错误(panic_if)。 panic_if(!pmemAddr, "Swap only works if there is real memory " \ "(i.e. null=False)"); // 初始化 overwrite_mem 为 true,表示默认情况下覆盖内存。 bool overwrite_mem = true; // keep a copy of our possible write value, and copy what is at the // memory address into the packet // 将数据包的数据写入 overwrite_val。 pkt->writeData(&overwrite_val[0]); // 将数据包的数据设置为内存中的当前值 pkt->setData(host_addr); // 如果请求是条件交换(isCondSwap) if (pkt->req->isCondSwap()) { // 根据数据包的大小(pkt->getSize())确定条件值的类型和大小。 // 获取条件值(condition_val64 或 condition_val32)。 // 比较条件值和内存地址的当前值,如果相等,则 overwrite_mem 保持 true,否则设为 false。 // 如果数据包大小既不是 64 位也不是 32 位,则触发致命错误。 if (pkt->getSize() == sizeof(uint64_t)) { condition_val64 = pkt->req->getExtraData(); overwrite_mem = !std::memcmp(&condition_val64, host_addr, sizeof(uint64_t)); } else if (pkt->getSize() == sizeof(uint32_t)) { condition_val32 = (uint32_t)pkt->req->getExtraData(); overwrite_mem = !std::memcmp(&condition_val32, host_addr, sizeof(uint32_t)); } else panic("Invalid size for conditional read/write\n"); } // 如果 overwrite_mem 为 true,则执行内存覆盖,将 overwrite_val 中的数据写入内存地址。 if (overwrite_mem) std::memcpy(host_addr, &overwrite_val[0], pkt->getSize()); assert(!pkt->req->isInstFetch()); TRACE_PACKET("Read/Write"); if (collectStats) { stats.numOther[pkt->req->requestorId()]++; } } } else if (pkt->isRead()) {// 处理读取请求,如果是读取请求,执行读取操作,并记录统计数据 assert(!pkt->isWrite()); if (pkt->isLLSC()) { assert(!pkt->fromCache()); // if the packet is not coming from a cache then we have // to do the LL/SC tracking here trackLoadLocked(pkt); } if (pmemAddr) { pkt->setData(host_addr); } TRACE_PACKET(pkt->req->isInstFetch() ? "IFetch" : "Read"); if (collectStats) { stats.numReads[pkt->req->requestorId()]++; stats.bytesRead[pkt->req->requestorId()] += pkt->getSize(); if (pkt->req->isInstFetch()) { stats.bytesInstRead[pkt->req->requestorId()] += pkt->getSize(); } } } else if (pkt->isInvalidate() || pkt->isClean()) {// 无效和清除请求,不执行任何操作。 assert(!pkt->isWrite()); // in a fastmem system invalidating and/or cleaning packets // can be seen due to cache maintenance requests // no need to do anything } else if (pkt->isWrite()) {// 处理写入请求,如果是写入请求,并且写入操作被允许,执行写入操作,并记录统计数据。 if (writeOK(pkt)) { if (pmemAddr) { pkt->writeData(host_addr); DPRINTF(MemoryAccess, "%s write due to %s\n", __func__, pkt->print()); } assert(!pkt->req->isInstFetch()); TRACE_PACKET("Write"); if (collectStats) { stats.numWrites[pkt->req->requestorId()]++; stats.bytesWritten[pkt->req->requestorId()] += pkt->getSize(); } } } else {// 如果数据包的类型不在预期范围内,触发致命错误 panic("Unexpected packet %s", pkt->print()); } // 生成响应 if (pkt->needsResponse()) { pkt->makeResponse(); }}
recvAtomicBackdoor
处理一个原子请求,并且尝试获取该请求的后门访问(backdoor access)。后门访问通常用于快速路径访问,绕过正常的缓存和控制机制,以更直接地访问内存内容。
xxxxxxxxxxTickMemCtrl::recvAtomicBackdoor(PacketPtr pkt, MemBackdoorPtr &backdoor){ // 调用 recvAtomic 处理原子请求,返回一个 Tick 类型的值,表示处理请求所需的延迟 Tick latency = recvAtomic(pkt); // 尝试获取一个后门访问对象,并将其存储在 backdoor 引用中。后门访问允许更直接和快速的内存访问。 dram->getBackdoor(backdoor); // 函数返回在 recvAtomic 调用中计算的延迟值 return latency;}后门访问(Backdoor Access)是一种绕过正常的内存访问路径,通过直接访问内存数据来提高访问速度和效率的技术。在计算机系统中,正常的内存访问路径通常会经过多个缓存层次和控制逻辑,而后门访问则直接与内存硬件进行交互,从而减少延迟和开销。
提高访问速度:
通过绕过缓存和控制逻辑,后门访问可以直接读取或写入内存,提高数据访问速度。这对于需要快速访问大数据块的操作特别有用。
调试和测试:
后门访问常用于调试和测试内存系统。在不干扰正常系统运行的情况下,可以直接检查和修改内存内容,帮助开发人员快速定位和解决问题。
特殊操作:
一些特殊操作需要直接访问内存,例如快速的数据传输、DMA(直接内存访问)操作等。后门访问提供了一个有效的途径来执行这些操作。
后门访问通常通过提供一个特殊的接口或方法来实现,该接口允许直接读取或写入内存。具体实现方式可能因系统和硬件架构而异。以下是一些常见的实现方式:
内存映射:
内存映射(Memory Mapping)是一种常见的后门访问方式。在这种方式中,特定的内存区域被映射到用户空间进程或硬件设备,允许直接访问内存数据。
专用接口:
有些系统提供专用的API或接口,允许开发人员通过这些接口直接与内存硬件交互。例如,在一些高性能计算系统中,提供了直接访问内存的API以提高数据传输效率。
硬件支持:
一些硬件设备提供了后门访问的支持。例如,某些内存控制器或存储器设备内置了后门访问功能,可以直接从外部访问内存数据。
readQueueFull
用于检查读队列是否已满。它接收一个参数 neededEntries,表示需要的条目数,并返回一个布尔值,表示读队列是否已满
xxxxxxxxxxboolMemCtrl::readQueueFull(unsigned int neededEntries) const{ // 输出当前读队列的限制、当前队列大小以及需要的条目数 DPRINTF(MemCtrl, "Read queue limit %d, current size %d, entries needed %d\n", readBufferSize, totalReadQueueSize + respQueue.size(), neededEntries); // 计算新的读队列大小 auto rdsize_new = totalReadQueueSize + respQueue.size() + neededEntries; return rdsize_new > readBufferSize;}totalReadQueueSize 表示当前读队列中的条目数。
respQueue.size() 返回响应队列的大小。
neededEntries 表示需要添加的条目数。
rdsize_new 是计算后的总大小,即当前读队列的大小加上响应队列的大小,再加上需要的条目数。
writeQueueFull
用于检查写队列是否已满
xxxxxxxxxxboolMemCtrl::writeQueueFull(unsigned int neededEntries) const{ DPRINTF(MemCtrl, "Write queue limit %d, current size %d, entries needed %d\n", writeBufferSize, totalWriteQueueSize, neededEntries); auto wrsize_new = (totalWriteQueueSize + neededEntries); return wrsize_new > writeBufferSize;}
addToReadQueue
实现了向读队列添加请求的功能,涉及到处理内存访问请求、分配内存数据包以及将请求添加到读队列中的逻辑
xxxxxxxxxxboolMemCtrl::addToReadQueue(PacketPtr pkt, unsigned int pkt_count, MemInterface* mem_intr){ // only add to the read queue here. whenever the request is // eventually done, set the readyTime, and call schedule() assert(!pkt->isWrite()); // 包计数不为0 assert(pkt_count != 0); // if the request size is larger than burst size, the pkt is split into // multiple packets // Note if the pkt starting address is not aligened to burst size, the // address of first packet is kept unaliged. Subsequent packets // are aligned to burst size boundaries. This is to ensure we accurately // check read packets against packets in write queue. // 初始化基地址、当前地址、服务于写队列的包计数、分割包的帮助器以及突发大小。 const Addr base_addr = pkt->getAddr(); Addr addr = base_addr; unsigned pktsServicedByWrQ = 0; BurstHelper* burst_helper = NULL; uint32_t burst_size = mem_intr->bytesPerBurst(); // 遍历所有分割后的数据包,计算每个包的大小,并更新统计信息 for (int cnt = 0; cnt < pkt_count; ++cnt) { unsigned size = std::min((addr | (burst_size - 1)) + 1, base_addr + pkt->getSize()) - addr; stats.readPktSize[ceilLog2(size)]++; stats.readBursts++; stats.requestorReadAccesses[pkt->requestorId()]++; // First check write buffer to see if the data is already at // the controller // foundInWrQ:一个布尔变量,表示当前读请求是否在写队列中找到对应的数据。 // burst_addr:突发对齐的地址,用于检查写队列中的数据包。burstAlign 函数将地址对齐到突发边界。 bool foundInWrQ = false; Addr burst_addr = burstAlign(addr, mem_intr); // if the burst address is not present then there is no need // looking any further // 检查当前请求是否已经在写队列中,如果在则更新相应的统计信息,并标记为已找到 // isInWriteQueue 是一个集合,包含了所有写队列中突发对齐的地址。这里检查当前的 burst_addr 是否在集合中 if (isInWriteQueue.find(burst_addr) != isInWriteQueue.end()) { // 遍历写队列 for (const auto& vec : writeQueue) { // 如果 burst_addr 在集合中,表示写队列中可能有覆盖当前读请求的数据包。继续检查具体的写队列: // 遍历 writeQueue 中的每一个数据包 p,检查当前读请求是否被写队列中的数据包覆盖 for (const auto& p : vec) { // check if the read is subsumed in the write queue // packet we are looking at // 如果 p->addr <= addr 且 (addr + size) <= (p->addr + p->size), // 表示当前读请求的地址范围完全被写队列中的数据包覆盖。 if (p->addr <= addr && ((addr + size) <= (p->addr + p->size))) { // 更新状态和统计信息 foundInWrQ = true; stats.servicedByWrQ++; pktsServicedByWrQ++; DPRINTF(MemCtrl, "Read to addr %#x with size %d serviced by " "write queue\n", addr, size); stats.bytesReadWrQ += burst_size; break; } } } } // If not found in the write q, make a memory packet and // push it onto the read queue // 将请求添加到读队列 // 如果在写队列中未找到对应的请求,将请求分割成多个包,并将这些包添加到读队列中。同时更新相应的统计信息和日志。 if (!foundInWrQ) { // 处理分片请求 // pkt_count > 1:如果请求分成了多个数据包。burst_helper == NULL:如果尚未创建分片辅助类。 // Make the burst helper for split packets if (pkt_count > 1 && burst_helper == NULL) { DPRINTF(MemCtrl, "Read to addr %#x translates to %d " "memory requests\n", pkt->getAddr(), pkt_count); // 创建一个新的 BurstHelper 对象来管理分片请求 burst_helper = new BurstHelper(pkt_count); } // 根据原始数据包 pkt 和地址信息创建一个新的内存数据包 mem_pkt MemPacket* mem_pkt; mem_pkt = mem_intr->decodePacket(pkt, addr, size, true, mem_intr->pseudoChannel); // Increment read entries of the rank (dram) // Increment count to trigger issue of non-deterministic read (nvm) // 设置内存数据包的rank信息 mem_intr->setupRank(mem_pkt->rank, true); // Default readyTime to Max; will be reset once read is issued // 设置内存数据包的就绪时间 mem_pkt->readyTime = MaxTick; // 将分片辅助类与内存数据包关联 mem_pkt->burstHelper = burst_helper; // 确保读队列不会超出限制 assert(!readQueueFull(1)); // 更新读队列长度的统计信息 stats.rdQLenPdf[totalReadQueueSize + respQueue.size()]++; DPRINTF(MemCtrl, "Adding to read queue\n"); // 将内存数据包加入到适当的读队列中。 readQueue[mem_pkt->qosValue()].push_back(mem_pkt); // log packet 记录读请求的日志。 logRequest(MemCtrl::READ, pkt->requestorId(), pkt->qosValue(), mem_pkt->addr, 1); // 增加读队列的大小计数 mem_intr->readQueueSize++; // Update stats更新平均读队列长度的统计信息。 stats.avgRdQLen = totalReadQueueSize + respQueue.size(); } // Starting address of next memory pkt (aligned to burst boundary) // 计算下一个要处理的地址,保证其在突发边界上对齐 addr = (addr | (burst_size - 1)) + 1; } // If all packets are serviced by write queue, we send the repsonse back // 如果所有包都已由写队列处理,直接发送响应。如果有部分包被写队列处理,更新 burst_helper 中的信息并返回 if (pktsServicedByWrQ == pkt_count) { accessAndRespond(pkt, frontendLatency, mem_intr); return true; } // Update how many split packets are serviced by write queue if (burst_helper != NULL) burst_helper->burstsServiced = pktsServicedByWrQ; // not all/any packets serviced by the write queue return false;}检查写队列的部分用于确定当前的读请求是否可以通过写队列来满足。如果写队列中已经有对应的数据,那么读请求可以直接从写队列中读取数据,而不需要访问内存
addToWriteQueue
将写请求添加到写队列
xxxxxxxxxxvoidMemCtrl::addToWriteQueue(PacketPtr pkt, unsigned int pkt_count, MemInterface* mem_intr){ // only add to the write queue here. whenever the request is // eventually done, set the readyTime, and call schedule() assert(pkt->isWrite()); // if the request size is larger than burst size, the pkt is split into // multiple packets // 处理分片请求 const Addr base_addr = pkt->getAddr();// 获取写请求的基础地址 Addr addr = base_addr;// 当前处理的地址,从基础地址开始 uint32_t burst_size = mem_intr->bytesPerBurst(); // 获取内存接口的每个突发传输的大小。 // 根据请求的大小和内存接口的突发大小将写请求分成多个数据包,并记录统计信息 for (int cnt = 0; cnt < pkt_count; ++cnt) { unsigned size = std::min((addr | (burst_size - 1)) + 1, base_addr + pkt->getSize()) - addr; stats.writePktSize[ceilLog2(size)]++; stats.writeBursts++; stats.requestorWriteAccesses[pkt->requestorId()]++; // see if we can merge with an existing item in the write // queue and keep track of whether we have merged or not // 检查写队列中的合并 // 当前处理的地址是否已经存在于写队列中。如果存在,则尝试与现有的写请求合并 bool merged = isInWriteQueue.find(burstAlign(addr, mem_intr)) != isInWriteQueue.end(); // if the item was not merged we need to create a new write // and enqueue it // 处理未合并的写请求,如果未在写队列中找到当前处理的地址(!merged),则 if (!merged) { // 使用 mem_intr 解码并创建一个新的内存数据包 mem_pkt MemPacket* mem_pkt; mem_pkt = mem_intr->decodePacket(pkt, addr, size, false, mem_intr->pseudoChannel); // Default readyTime to Max if nvm interface; //will be reset once read is issued // 如果是非易失性内存接口,将 mem_pkt 的就绪时间设置为 MaxTick mem_pkt->readyTime = MaxTick; // 设置内存数据包的rank mem_intr->setupRank(mem_pkt->rank, false); // 确保写队列的大小未超过设定的限制 assert(totalWriteQueueSize < writeBufferSize); stats.wrQLenPdf[totalWriteQueueSize]++; DPRINTF(MemCtrl, "Adding to write queue\n"); // 将内存数据包 mem_pkt 添加到写队列 writeQueue 中,并将对应的地址插入到 isInWriteQueue // mem_pkt->qosValue() 返回当前内存数据包 mem_pkt 的服务质量值(Quality of Service, QoS), // 这个值决定了数据包应该被放入哪个优先级的队列 writeQueue[mem_pkt->qosValue()].push_back(mem_pkt); isInWriteQueue.insert(burstAlign(addr, mem_intr)); // log packet 记录写请求日志 logRequest(MemCtrl::WRITE, pkt->requestorId(), pkt->qosValue(), mem_pkt->addr, 1); mem_intr->writeQueueSize++; assert(totalWriteQueueSize == isInWriteQueue.size()); // Update stats 更新写队列的统计信息 stats.avgWrQLen = totalWriteQueueSize; } else { DPRINTF(MemCtrl, "Merging write burst with existing queue entry\n"); // keep track of the fact that this burst effectively // disappeared as it was merged with an existing one stats.mergedWrBursts++; } // Starting address of next memory pkt (aligned to burst_size boundary) // 计算并更新下一个处理的地址,以保证其在突发边界上对齐 addr = (addr | (burst_size - 1)) + 1; } // we do not wait for the writes to be send to the actual memory, // but instead take responsibility for the consistency here and // snoop the write queue for any upcoming reads // @todo, if a pkt size is larger than burst size, we might need a // different front end latency // 在处理完所有分片请求后,访问内存并响应请求。 // 这里的 accessAndRespond 函数可能会将写请求发送到实际的内存,并处理相应的响应逻辑。 accessAndRespond(pkt, frontendLatency, mem_intr);}
xxxxxxxxxx unsigned size = std::min((addr | (burst_size - 1)) + 1, base_addr + pkt->getSize()) - addr;(addr | (burst_size - 1))进行按位或操作,这将addr向上舍入到最接近的burst_size的倍数,确保下一个地址处于突发边界上将结果加一,确保我们计算的是从当前地址开始的完整突发的大小
base_addr + pkt->getSize():计算写请求的结束地址取上述两个值的最小值,确保我们不超过写请求的实际大小
服务质量(QoS)的重要性:
QoS 是用来区分和管理不同请求在系统中的优先级和重要性的指标。不同的请求可能具有不同的响应时间要求或者处理优先级。
在内存控制器(
MemCtrl)中,不同的请求者(requestor)可能会因为其角色或者应用场景而具有不同的 QoS 值。
分级管理:
通过使用 QoS 值来分级管理写请求,系统可以更精细地控制对内存访问的调度和响应。高优先级的请求可以更快地得到服务,而低优先级的请求则可以在系统负载较轻时处理。
将
writeQueue设计为二维结构,可以根据 QoS 值的不同将请求分配到不同的队列中。这样做的好处是可以在不同的队列中独立管理和调度请求,以满足不同 QoS 级别的需求。
队列管理和调度:
每个
writeQueue[qos]都是一个单独的队列,用于存储特定 QoS 值的写请求。当内存控制器需要处理写请求时,可以根据 QoS 值快速定位到合适的队列,并进行相应的操作。这种设计可以有效地管理系统中不同优先级的写请求,同时避免不同请求之间的干扰和竞争,提高系统整体的资源利用率和性能。
存储系统:
在存储系统中,QoS 常用于管理对存储资源的访问。例如,通过为不同应用程序或者用户组分配不同的带宽或者响应时间,以确保关键应用的数据访问性能。
内存控制器和缓存系统:
内存控制器和缓存系统中常根据 QoS 策略管理和调度内存访问。例如,将请求分为不同的优先级队列,以便在高负载时保证关键数据的及时访问。
PrintQs
实现了打印内存控制器中读队列(readQueue)、响应队列(respQueue)和写队列(writeQueue)的功能。这通常用于调试和跟踪内存控制器中当前正在处理的请求。
xxxxxxxxxxvoidMemCtrl::printQs() const{ DPRINTF(MemCtrl, "===READ QUEUE===\n\n"); for (const auto& queue : readQueue) { for (const auto& packet : queue) { DPRINTF(MemCtrl, "Read %#x\n", packet->addr); } } DPRINTF(MemCtrl, "\n===RESP QUEUE===\n\n"); for (const auto& packet : respQueue) { DPRINTF(MemCtrl, "Response %#x\n", packet->addr); } DPRINTF(MemCtrl, "\n===WRITE QUEUE===\n\n"); for (const auto& queue : writeQueue) { for (const auto& packet : queue) { DPRINTF(MemCtrl, "Write %#x\n", packet->addr); } }// TRACING_ON}
recvTimingReq
实现了内存控制器处理来自外部的定时请求(recvTimingReq)
xxxxxxxxxxboolMemCtrl::recvTimingReq(PacketPtr pkt){ // This is where we enter from the outside world // 日志输出和断言检查 DPRINTF(MemCtrl, "recvTimingReq: request %s addr %#x size %d\n", pkt->cmdString(), pkt->getAddr(), pkt->getSize()); // 参见之前嗅探和缓存一致性的相关部分 Ctrl+F直接搜索即可 panic_if(pkt->cacheResponding(), "Should not see packets where cache " "is responding"); // only rd or wr panic_if(!(pkt->isRead() || pkt->isWrite()), "Should only see read and writes at memory controller\n"); // Calc avg gap between requests // 计算请求之间的平均间隔 if (prevArrival != 0) { // 计算并更新前一个请求到达时间与当前请求到达时间之间的间隔,用于性能统计 stats.totGap += curTick() - prevArrival; } prevArrival = curTick(); // 确保请求的地址在内存控制器管理的地址范围内,否则触发 panic panic_if(!(dram->getAddrRange().contains(pkt->getAddr())), "Can't handle address range for packet %s\n", pkt->print()); // Find out how many memory packets a pkt translates to // If the burst size is equal or larger than the pkt size, then a pkt // translates to only one memory packet. Otherwise, a pkt translates to // multiple memory packets // 确定请求转换为多少个内存包 // 根据内存的 burst size 确定该请求转换为多少个内存包。 // 如果请求大小大于等于 burst size,则一个请求转换为一个内存包;否则,多个请求会跨多个内存包 unsigned size = pkt->getSize(); uint32_t burst_size = dram->bytesPerBurst(); unsigned offset = pkt->getAddr() & (burst_size - 1); unsigned int pkt_count = divCeil(offset + size, burst_size); // run the QoS scheduler and assign a QoS priority value to the packet // 运行 QoS 调度器,为请求分配一个 QoS 优先级值,以决定其进入读或写队列的位置。 qosSchedule( { &readQueue, &writeQueue }, burst_size, pkt); // check local buffers and do not accept if full /* ---------检查本地缓冲区状态------------*/ // 写请求处理,如果写队列未满,则将请求添加到写队列,并记录统计信息。如果写队列已满,则标记需要重试,并返回 false if (pkt->isWrite()) { assert(size != 0); if (writeQueueFull(pkt_count)) { DPRINTF(MemCtrl, "Write queue full, not accepting\n"); // remember that we have to retry this port retryWrReq = true; stats.numWrRetry++; return false; } else { addToWriteQueue(pkt, pkt_count, dram); // If we are not already scheduled to get a request out of the // queue, do so now if (!nextReqEvent.scheduled()) { DPRINTF(MemCtrl, "Request scheduled immediately\n"); schedule(nextReqEvent, curTick()); } stats.writeReqs++; stats.bytesWrittenSys += size; } } else {// 读请求处理,如果读队列已满,则标记需要重试,并返回 false assert(pkt->isRead()); assert(size != 0); if (readQueueFull(pkt_count)) { DPRINTF(MemCtrl, "Read queue full, not accepting\n"); // remember that we have to retry this port retryRdReq = true; stats.numRdRetry++; return false; } else { if (!addToReadQueue(pkt, pkt_count, dram)) { // If we are not already scheduled to get a request out of the // queue, do so now if (!nextReqEvent.scheduled()) { DPRINTF(MemCtrl, "Request scheduled immediately\n"); schedule(nextReqEvent, curTick()); } } stats.readReqs++; stats.bytesReadSys += size; } } return true;}
processRespondEvent
用于处理响应事件的函数,主要功能是处理到达其就绪时间的请求
xxxxxxxxxxvoidMemCtrl::processRespondEvent(MemInterface* mem_intr, MemPacketQueue& queue, EventFunctionWrapper& resp_event, bool& retry_rd_req){ // 记录日志,指示有请求已经达到了其就绪时间 DPRINTF(MemCtrl, "processRespondEvent(): Some req has reached its readyTime\n"); // 取出队列中的请求包 MemPacket* mem_pkt = queue.front(); /*---------------处理响应事件-----------------*/ // media specific checks and functions when read response is complete // DRAM only // 调用介质接口 mem_intr 的 respondEvent 函数处理响应事件,针对特定介质(如DRAM)进行必要的操作 mem_intr->respondEvent(mem_pkt->rank); // 处理分裂数据包 // 如果 mem_pkt 是分裂数据包,则根据 burstHelper 的存在与否进行不同的处理。 // 如果是分裂数据包,将会增加已服务的子数据包计数,并在所有子数据包都已服务时,响应请求 if (mem_pkt->burstHelper) { // it is a split packet mem_pkt->burstHelper->burstsServiced++; if (mem_pkt->burstHelper->burstsServiced == mem_pkt->burstHelper->burstCount) { // we have now serviced all children packets of a system packet // so we can now respond to the requestor // @todo we probably want to have a different front end and back // end latency for split packets accessAndRespond(mem_pkt->pkt, frontendLatency + backendLatency, mem_intr); delete mem_pkt->burstHelper; mem_pkt->burstHelper = NULL; } } else { // it is not a split packet // 调用 accessAndRespond 函数处理并响应请求包 accessAndRespond(mem_pkt->pkt, frontendLatency + backendLatency, mem_intr); } // 将已处理的请求包从队列中移除 queue.pop_front(); // 如果队列不为空,则根据队首请求包的就绪时间 readyTime 调度下一个响应事件 resp_event if (!queue.empty()) { assert(queue.front()->readyTime >= curTick()); assert(!resp_event.scheduled()); schedule(resp_event, queue.front()->readyTime); } else { // if there is nothing left in any queue, signal a drain // 如果所有队列都为空且系统处于排空状态,发出信号表示排空完成; if (drainState() == DrainState::Draining && !totalWriteQueueSize && !totalReadQueueSize && allIntfDrained()) { DPRINTF(Drain, "Controller done draining\n"); signalDrainDone(); } else {// 否则,检查刷新状态并可能启动刷新事件循环 // check the refresh state and kick the refresh event loop // into action again if banks already closed and just waiting // for read to complete // DRAM only mem_intr->checkRefreshState(mem_pkt->rank); } } // 释放已处理请求包 mem_pkt 的内存空间 delete mem_pkt; // We have made a location in the queue available at this point, // so if there is a read that was forced to wait, retry now // 重试等待的读请求,如果之前有等待的读请求被阻塞,现在重试发送该请求 if (retry_rd_req) { retry_rd_req = false; port.sendRetryReq(); }}这段代码的主要目的是在请求包达到就绪时间后,处理其响应和后续的调度逻辑,并根据需要执行额外的刷新或重试操作.
chooseNext
用于在内存控制器中选择下一个要处理的请求包(MemPacket)
MemPacketQueue::iterator 是一个迭代器类型,用于访问 MemPacketQueue 中的元素。
queue 是一个 MemPacketQueue 类型的引用,表示待处理的请求队列。
extra_col_delay 是一个时钟周期延迟,用于额外的冲突延迟。
mem_intr 是一个 MemInterface 类型的指针,表示内存接口。
xxxxxxxxxxMemPacketQueue::iteratorMemCtrl::chooseNext(MemPacketQueue& queue, Tick extra_col_delay, MemInterface* mem_intr){ // This method does the arbitration between requests. // 初始化迭代器 ret,默认为 queue 的末尾位置,表示暂时没有找到合适的请求包 MemPacketQueue::iterator ret = queue.end(); // 检查队列是否为空,如果队列不为空才进行调度处理 if (!queue.empty()) { if (queue.size() == 1) { // 如果队列中只有一个请求包,首先检查其伪通道是否与当前内存接口的伪通道匹配。 // 然后检查请求包是否就绪,如果就绪则将其迭代器赋给 ret,表示选择该请求包 // available rank corresponds to state refresh idle MemPacket* mem_pkt = *(queue.begin()); if (mem_pkt->pseudoChannel != mem_intr->pseudoChannel) { return ret; } if (packetReady(mem_pkt, mem_intr)) { ret = queue.begin(); DPRINTF(MemCtrl, "Single request, going to a free rank\n"); } else { DPRINTF(MemCtrl, "Single request, going to a busy rank\n"); } }/*-----------按照调度策略处理-----------*/ else if (memSchedPolicy == enums::fcfs) { // check if there is a packet going to a free rank // 如果采用先到先服务(FCFS)策略,遍历队列中的每个请求包. // 检查伪通道匹配以及请求包是否就绪,找到第一个就绪的请求包并将其迭代器赋给 ret for (auto i = queue.begin(); i != queue.end(); ++i) { MemPacket* mem_pkt = *i; if (mem_pkt->pseudoChannel != mem_intr->pseudoChannel) { continue; } if (packetReady(mem_pkt, mem_intr)) { ret = i; break; } } } // 如果采用(FR-FCFS)策略,则调用 chooseNextFRFCFS 函数来选择下一个请求包 // 并返回其迭代器和允许的冲突时间 else if (memSchedPolicy == enums::frfcfs) { Tick col_allowed_at; std::tie(ret, col_allowed_at) = chooseNextFRFCFS(queue, extra_col_delay, mem_intr); } else {// 异常处理 panic("No scheduling policy chosen\n"); } } // 返回选定的请求包迭代器 ret,表示选择的下一个要处理的请求包在队列中的位置 return ret;}
chooseNextFRFCFS
用于实现 FR-FCFS(First-Ready, First-Come, First-Serve)调度策略的具体函数,这个函数的主要目的是根据 FR-FCFS 调度策略选择下一个要处理的请求包,并返回其迭代器和允许的列命令时间.
返回类型是 std::pair<MemPacketQueue::iterator, Tick>,表示选择的下一个请求包迭代器和允许的列命令时间。
queue 是一个 MemPacketQueue 类型的引用,表示待处理的请求队列。
extra_col_delay 是一个额外的列命令延迟。
mem_intr 是一个 MemInterface 类型的指针,表示内存接口。
xxxxxxxxxxstd::pair<MemPacketQueue::iterator, Tick>MemCtrl::chooseNextFRFCFS(MemPacketQueue& queue, Tick extra_col_delay, MemInterface* mem_intr){ // 示初始没有选择的请求包 auto selected_pkt_it = queue.end(); // 表示初始列命令可以允许的最大时间 Tick col_allowed_at = MaxTick; // time we need to issue a column command to be seamless // 计算最小列命令时间 // mem_intr->nextBurstAt 和当前时钟周期 curTick() 加上 extra_col_delay 的最大值。这个时间用来确保列命令的无缝执行 const Tick min_col_at = std::max(mem_intr->nextBurstAt + extra_col_delay, curTick()); // 调用 mem_intr 对象的 chooseNextFRFCFS 方法,根据 FR-FCFS 策略从 queue 中选择下一个请求包, // 并返回选中的请求包迭代器和允许的列命令时间 std::tie(selected_pkt_it, col_allowed_at) = mem_intr->chooseNextFRFCFS(queue, min_col_at); if (selected_pkt_it == queue.end()) { DPRINTF(MemCtrl, "%s no available packets found\n", __func__); } return std::make_pair(selected_pkt_it, col_allowed_at);}FR-FCFS(First-Ready First-Come, First-Serve)策略是内存调度中常见的一种策略,特别适用于多通道内存或多rank内存系统。下面是对FR-FCFS策略的详细解释:
FR-FCFS策略的设计目的是优化多通道内存或多rank内存系统中的请求处理。它结合了两种主要的调度原则:首先是“首就绪”(First-Ready),即优先选择已准备好进行处理的请求;其次是“先来先服务”(First-Come, First-Serve),即同一就绪状态下,优先处理最早到达的请求。
就绪状态优先:
FR-FCFS首先检查哪些请求已经准备好(ready)。这通常意味着请求已经通过前端的处理,可以立即被发送到内存控制器进行处理。
准备好的标准可以根据具体的系统设计而变化,但通常包括等待排队时间已满、依赖的前置操作已完成等条件。
先来先服务调度:
在所有准备好的请求中,FR-FCFS选择最早到达的请求进行处理。这种方式确保了请求的处理顺序是公平且有序的。
适用于多通道或多rank系统:
FR-FCFS特别适用于多通道内存或多rank内存系统,这些系统允许同时处理来自多个通道或rank的内存请求。通过选择就绪且最早到达的请求,可以有效地利用并行处理能力,提高系统的整体性能。
在内存控制器的设计中,col_allowed_at 通常表示的是允许发出列命令的时间。这个时间点是根据当前系统的状态和内存控制器的调度策略计算出来的,具体可能涉及以下几个方面的考量:
额外列延迟(extra_col_delay):这个延迟是考虑到在某些系统中,可能需要在发出列命令之前预留一定的时间,以确保操作的顺畅性和稳定性。
内存接口的下一个突发时间(mem_intr->nextBurstAt):内存控制器可能会跟踪下一个突发传输的时间点,以便在适当的时候发出内存访问请求。
当前时钟周期(curTick()):这是当前的系统时钟周期,用于确保在正确的时间发出内存命令,以与系统的其他部分同步。
综合这些因素,col_allowed_at 可能是一个预测的时间点,表示在这个时间之后,内存控制器可以安全地发出下一个列命令,以执行内存访问操作。
accessAndRespond
内存控制器中用于处理内存访问并响应的关键函数
xxxxxxxxxxvoidMemCtrl::accessAndRespond(PacketPtr pkt, Tick static_latency, MemInterface* mem_intr){ // 里打印出将要响应的内存地址,用于调试和追踪目的。 DPRINTF(MemCtrl, "Responding to Address %#x.. \n", pkt->getAddr()); // 检查当前的数据包是否需要响应。如果不需要响应,后续操作将直接释放这个数据包 bool needsResponse = pkt->needsResponse(); // do the actual memory access which also turns the packet into a // response panic_if(!mem_intr->getAddrRange().contains(pkt->getAddr()), "Can't handle address range for packet %s\n", pkt->print()); // 调用 mem_intr 的 access 函数执行实际的内存访问操作。这可能包括将数据包发送到内存以获取数据或将数据写入内存 mem_intr->access(pkt); // 如果数据包需要响应 // turn packet around to go back to requestor if response expected if (needsResponse) { // 确保数据包已经被标记为响应状态。然后计算响应时间: // access already turned the packet into a response assert(pkt->isResponse()); // response_time consumes the static latency and is charged also // with headerDelay that takes into account the delay provided by // the xbar and also the payloadDelay that takes into account the // number of data beats. Tick response_time = curTick() + static_latency + pkt->headerDelay + pkt->payloadDelay; // Here we reset the timing of the packet before sending it out. // 重置延迟并排队响应 pkt->headerDelay = pkt->payloadDelay = 0; // queue the packet in the response queue to be sent out after // the static latency has passed // 将数据包加入响应队列 port 中,等待 response_time 后发送响应。 port.schedTimingResp(pkt, response_time); } else { // @todo the packet is going to be deleted, and the MemPacket // is still having a pointer to it // 如果数据包不需要响应,或者在响应队列中排队后,将其标记为待删除状态 pendingDelete.reset(pkt); } DPRINTF(MemCtrl, "Done\n"); return;}
pruneBurstTick
用来清理存储在 burstTicks 中的已经过时的时钟周期值的函数
xxxxxxxxxxvoidMemCtrl::pruneBurstTick(){ // 使用 auto 关键字初始化一个迭代器 it,指向 burstTicks 容器的起始位置 auto it = burstTicks.begin(); // 使用 while 循环遍历 burstTicks 容器中的每个元素,条件是迭代器 it 未到达容器末尾。 // 在每次循环中,先将当前迭代器 it 的值赋给 current_it,然后迭代器 it 自增一次。 while (it != burstTicks.end()) { auto current_it = it++; // 对于每个元素,检查当前模拟时钟周期 curTick() 是否大于 burstTicks 中存储的值 *current_it。 // 如果是,表示该时钟周期已经过时。然后,打印一条日志消息说明正在移除过时的时钟周期, // 并使用 erase() 函数从 burstTicks 容器中移除该值 if (curTick() > *current_it) { DPRINTF(MemCtrl, "Removing burstTick for %d\n", *current_it); burstTicks.erase(current_it); } }}
Chameleon 代码部分
项目结构"chameleon_ctrl.cc+chameleon.hh"通过gem5嵌入的pybind11与“Chameleon.py”绑定,通过SConsscript编译将ChameleonCtrl对象引入m5.object,可以在python文件中进行配置。
关于Segment
Each segment is 64 Byte in size. 每个段的大小为 64 字节。【代码中是这样注释的】
论文中指出:
The various segment granularities supported by the hardware in Chameleon can be easily detected by the OS during boot timeCAMEO这个工作的大小是64B 、PoM[25]的大小是2KB
segGrpEntry: 一组segments 组成为【1 HBM segment + 多个(设置成3)DDR Segment】元数据也包含在其中。
实际上就是论文中的Segment Group的其中一组。
参数:
Addr addrEntry的偏移量
例如:[
addr = 318,HBM 8GB,DDR 32GB]HBM address 就应该是
3*8GiB + 318DDR Segment 0 address 就应该是
0*8GiB + 318DDR Segment 1 address 就应该是
1*8GiB + 318DDR Segment 2 address 就应该是
2*8GiB + 318
ddrNumsegGrpEntry: 一组segments 组成为【1 HBM segment + 多个(设置成3)DDR Segment】,默认3
cacheMode是Cache【1】还是Flat(POM)【0】
dirty无需多言
busy当条目正在写回或进行其他操作时,设置其为忙碌状态。 将所有访问的数据包放入reqQueue中,并稍后处理它们。
reqQueue保留来自CPU的请求数据包。 当该条目准备好时,应清空所有队列
tags指示remap条件
例如:tags[3]=1 , HBM【可能Segment编号是3】 address现在存着的是DDR Segment 1的数据。因此访问DDR Segment 1 的数据根据其他一些bits 【比如 xxx??? 】可能会被重定向到HBM Segment。
readTypes指示什么读数据需要被写入
-1 : 不发送
例如: readType[1]=3 读数据包被送到1,读的数据被写入3 【指的应该是Segment 1/3 也就是DDR Segment 1 HBM Segment】
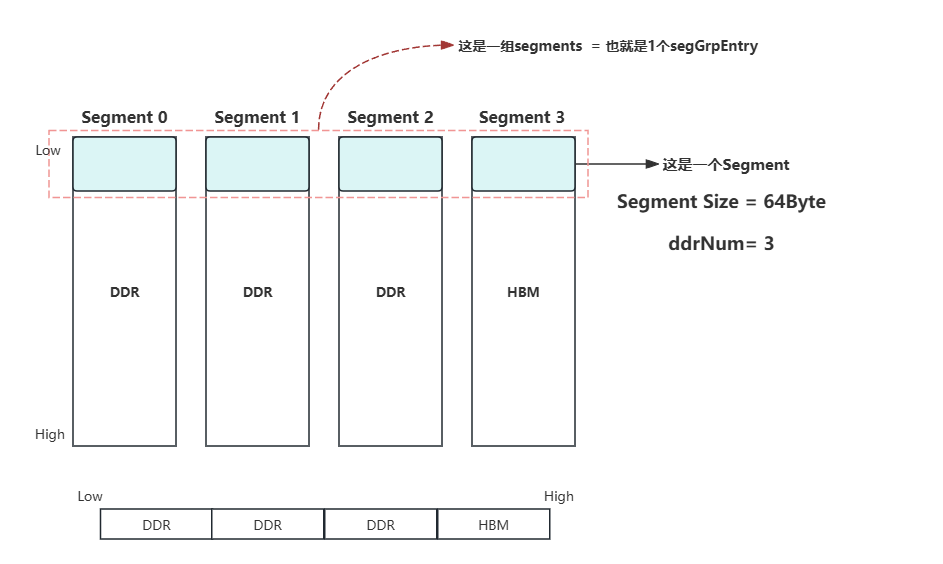
关于MemSidePort
MemSidePort的类,它继承自QueuedRequestPort,表示在内存端的一个端口,用于接收响应
xxxxxxxxxx // Port on the memory-side that receives responses. // Refer to sim_cache.hh for further information. class MemSidePort : public QueuedRequestPort { private:
// 这是一个请求包队列,用于存储接收到的请求数据包 ReqPacketQueue reqQueue; // 这是一个用于存储Snoop响应数据包的队列。Snoop响应通常用于缓存协议中的无效ation、更新和写入通知等操作 SnoopRespPacketQueue snoopRespQueue; // Not quite sure with * or & here // 这是一个指向ChameleonCtrl类对象的指 // 用于指示拥有(owner)这个MemSidePort实例的ChameleonCtrl实例。通常在构造函数中初始化 ChameleonCtrl *owner;
public:
MemSidePort(const std::string& name, ChameleonCtrl *_owner);
protected: // 这是一个虚函数,覆盖了基类QueuedRequestPort中的recvTimingResp函数。用于接收并处理定时响应数据包 bool recvTimingResp(PacketPtr pkt) override;
// void recvReqRetry() override; // 这是一个虚函数,覆盖了基类QueuedRequestPort中的recvRangeChange函数。用于接收和处理范围改变通知 void recvRangeChange() override; };虚函数在面向对象编程中起着非常重要的作用,主要有以下几个方面:
实现多态性(Polymorphism):
虚函数允许在基类中声明接口,并在派生类中重新定义该函数。通过基类指针或引用调用虚函数时,根据实际对象的类型来决定调用哪个版本的函数,实现了多态性。这种特性使得程序能够根据对象的实际类型来动态地选择合适的函数实现,从而提高了代码的灵活性和可维护性。
允许运行时绑定(Runtime Binding):
虚函数通过在运行时确定要调用的函数版本,而不是在编译时确定。这种动态绑定的机制使得程序能够在运行时根据对象的实际类型来决定调用哪个函数,从而支持更灵活的程序行为。
实现接口和抽象类:
虚函数可以在基类中声明为纯虚函数(即没有实现),使得基类成为抽象类,无法直接实例化对象,但可以作为接口使用。派生类必须实现基类中的纯虚函数,从而实现接口的规范和强制约束。
方便的函数重写机制:
虚函数允许派生类重新定义基类的函数,以适应特定的需求或环境。这种机制使得继承关系更加灵活,子类可以根据需要定制自己的行为,同时还能够利用基类的通用实现。
支持动态内存分配和销毁:
虚函数使得通过基类指针或引用访问派生类对象成为可能。这种特性对于动态内存管理(如使用
new和delete运算符)尤为重要,可以根据需要动态地创建和销毁对象,并确保正确调用派生类的函数。
关于CpuSidePort
用于在内存控制器与CPU之间的通信。它管理从CPU接收的数据包请求和响应,并提供处理和重试机制。该类具有以下主要功能:
存储和管理响应数据包的队列。
处理从CPU接收的定时和功能性请求。
支持设置和清除阻塞状态,以控制端口的请求处理能力。
提供地址范围查询和重试请求处理的机制。
xxxxxxxxxxclass CPUSidePort : public QueuedResponsePort{ private: /** A packet queue used to store responses. */ RespPacketQueue respQueue; // 存储响应数据包的队列
ChameleonCtrl *owner; // 指向拥有此端口的 ChameleonCtrl 实例的指针
/** * @brief use event instead of directly sendRetryReq * @todo not added yet */ // EventFunctionWrapper sendRetryEvent; // 用于事件驱动的重试请求(尚未实现)
public: CPUSidePort(const std::string& name, ChameleonCtrl *_owner); // 构造函数
AddrRangeList getAddrRanges() const override; // 获取地址范围的函数,覆盖基类方法
void processSendRetry(); // 处理发送重试请求
/** * Set CPUSidePort as blocked when busy, and reject requests. * Should be called by ChameleonCtrl::setBlocked(). */ void setBlocked(); // 设置端口为阻塞状态,拒绝请求
/** * Set CPUSidePort as unblocked when free, * and accept new requests. * Should be called by ChameleonCtrl::clearBlocked(). * @warning every sendRetryReq should be done here */ void clearBlocked(); // 设置端口为非阻塞状态,接受新请求 bool isBlocked() const { return blocked; } // 检查端口是否阻塞
protected: /** * Note: ChameleonCtrl::blocked is not * ChameleonCtrl::CPUSidePort::blocked. * In some cases, the two may be different. */ bool blocked; // 标记端口是否阻塞 bool mustSendRetry; // 标记是否必须发送重试请求
// Almost the same as recvTimingReq Tick recvAtomic(PacketPtr pkt) override { panic("recvAtomic unimpl."); } // 未实现的原子接收方法
void recvFunctional(PacketPtr pkt) override; // 功能性接收方法
// Will implement tryTiming here bool tryTiming(PacketPtr pkt) override; // 尝试定时方法
bool recvTimingReq(PacketPtr pkt) override; // 接收定时请求
// void recvRespRetry() override;};
chameleon_ctrl.cc/hh
Chameleon构造类和初始化部分
xxxxxxxxxxChameleonCtrl::ChameleonCtrl(const ChameleonCtrlParams ¶ms) : ClockedObject(params), _MemSideRequestorId(params.system->getRequestorId(this, "memSide")), stats(this), blockSize(params.system->cacheLineSize()), // hbmSize(8*1024*1024*1024LL), ddrRatio(3), hbmSize(1*1024*1024*1024LL), ddrRatio(16), common_lat(500), blocked(0), memPort(params.name + ".mem_side", this), cpuPort(params.name + ".cpu_side", this){ initSegGrps();}ChameleonCtrlParams类无需手动实现,只需要写好.cc和.hh以及.py文件,在执行过程中会自动生成
hbmSize(1*1024*1024*1024LL), ddrRatio(16)指定HBM容量和对应的DRAM比例,需要和后续python文件中匹配。这是.cc和.hh文件中其它出现的相关的参数的默认值。
ChameleonStats构造函数并定义统计信息
xxxxxxxxxxChameleonCtrl::ChameleonStats::ChameleonStats(Stats::Group *parent) : Stats::Group(parent),
ADD_STAT(toPom, UNIT_COUNT, "Number of segments changing from " "cache mode to PoM mode"),
ADD_STAT(pomAccess, UNIT_COUNT, "Number of accesses in PoM mode"), ADD_STAT(cacheAccess, UNIT_COUNT, "Number of accesses in cache mode"),
ADD_STAT(segAccess, UNIT_COUNT, "Number of accesses in either mode" ", also the number of segment lookup times")
{}
initSegGrps
初始化分段组(Segment Groups)
根据给定的块大小和地址范围(这里是从0到1MB)初始化一组段组(Segment Groups)。每个段组包含一个地址和DDR比率,然后将它们添加到 segGrps 中,以便后续使用。
xxxxxxxxxxvoidChameleonCtrl::initSegGrps(){ DPRINTF(ChameleonCtrl, "Initializing Segment Groups\n"); // for (Addr addr = 0LL; addr < hbmSize; addr += blockSize) { // 循环初始化段组,从地址0开始,每次增加 blockSize(块大小)来遍历地址空间 for (Addr addr = 0LL; addr < 1024*1024LL; addr += blockSize) { // 创建了一个 segGrpEntry 对象 tmpEntry,并将其初始化为给定的地址 addr 和 ddrRatio segGrpEntry tmpEntry(addr, ddrRatio); // 将新创建的 tmpEntry 添加到 segGrps 的末尾 segGrps.emplace_back(tmpEntry); }
DPRINTF(ChameleonCtrl, "Segment Groups initialized\n");}这段原理可以看图
也就只能初始化HBM_Size / Segment Size大小个segGrpEntry
而Segment Size = Block Size = 64 Bytes,segGrps需要在Chameleon刚开始初始化,一个for循环搞定。
getPort
xxxxxxxxxxPort &ChameleonCtrl::getPort(const std::string &if_name, PortID idx){ if (if_name == "mem_side") { panic_if(idx != InvalidPortID, "Mem side of ChameleonCtrl not a vector port"); return memPort; } else if (if_name == "cpu_side") { panic_if(idx != InvalidPortID, "CPU side of ChameleonCtrl not a vector port"); return cpuPort; } else { return ClockedObject::getPort(if_name, idx); }}xxxxxxxxxx MemSidePort memPort; CPUSidePort cpuPort;
CPUSidePort构造函数
xxxxxxxxxxChameleonCtrl::CPUSidePort::CPUSidePort(const std::string& name, ChameleonCtrl *_owner) : QueuedResponsePort(name, _owner, respQueue), respQueue(*_owner, *this, true), owner(_owner), blocked(false), mustSendRetry(false){ }CPUSidePort继承QueuedResponsePort
xxxxxxxxxxclass CPUSidePort : public QueuedResponsePortxxxxxxxxxx class CPUSidePort : public QueuedResponsePort { private:
/** 用于存储响应的数据包队列. */ RespPacketQueue respQueue; /** 拥有该端口的 ChameleonCtrl 对象 */ ChameleonCtrl *owner;初始化为端口当前未阻塞,当前不需要发送重试请求
CPUSidePort::setBlcoked
xxxxxxxxxxvoidChameleonCtrl::CPUSidePort::setBlocked(){ assert(!blocked); DPRINTF(ChameleonCtrl, "Port is blocking new requests\n"); blocked = true; // @todo should set mustSendRetry to true if there // already is a scheduled retry. // refer to base.cc::146}
CPUSidePort::clearBlocked
xxxxxxxxxxvoidChameleonCtrl::CPUSidePort::clearBlocked(){ assert(blocked); DPRINTF(ChameleonCtrl, "Port is accepting new requests\n"); blocked = false;
// including sendRetryReq here if (mustSendRetry) { processSendRetry(); }}
CPUSidePort::getAddrRanges
xxxxxxxxxxAddrRangeListChameleonCtrl::CPUSidePort::getAddrRanges() const{ DPRINTF(ChameleonCtrl, "Getting AddrRanges\n"); return owner->getAddrRanges();}
CPUSidePort::processSendRetry
xxxxxxxxxxvoidChameleonCtrl::CPUSidePort::processSendRetry(){ // blocketPacket is not needed here. // ChameleonCtrl can work well with only 1 blocketPacket. DPRINTF(ChameleonCtrl, "Sending retry req.\n"); // 向之前尝试向该响应端口发送。向该响应端口发送 sendTimingReq 但失败的请求端口发送重试。 sendRetryReq(); mustSendRetry = false;}
functionalAccess
传入数据包,得到数据包地址和请求,计算得到:
注:一组segments 组成为【1 HBM segment + 多个(设置成3)DDR Segment】 【 Segment size = 64B (e.g,)】
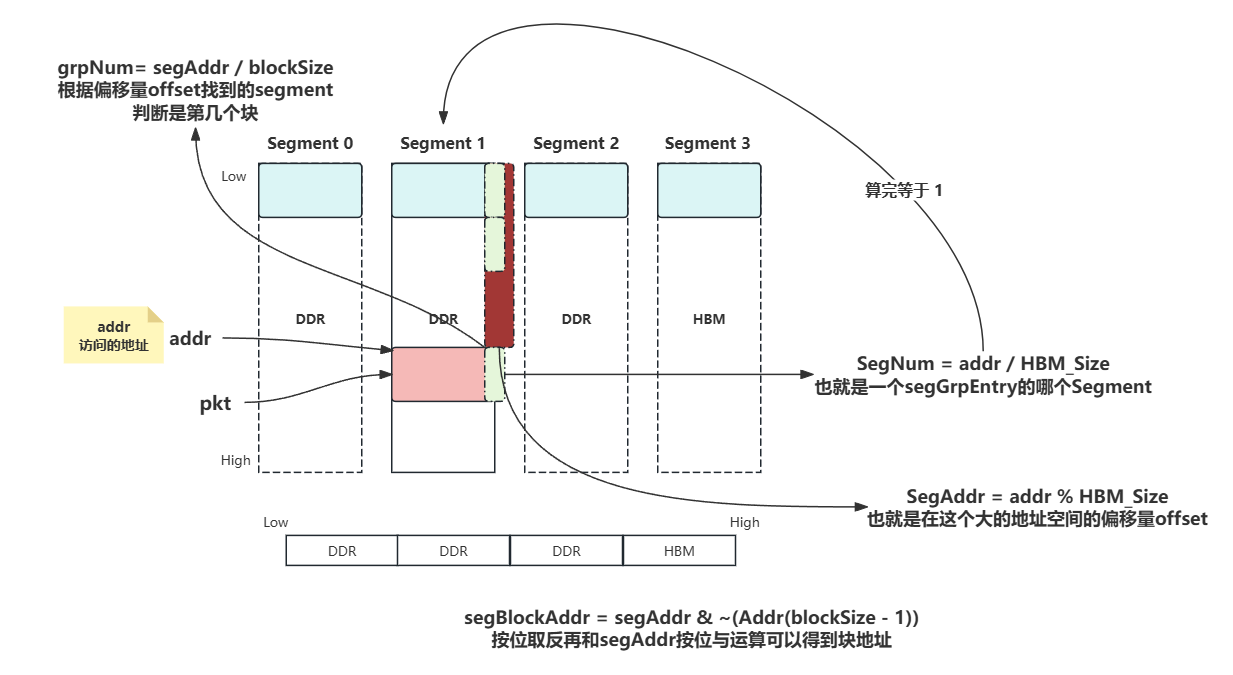
xxxxxxxxxxvoidChameleonCtrl::functionalAccess(PacketPtr pkt){ DPRINTF(ChameleonCtrl, "Got functional access\n"); // 这个数据包只能是读或者写 if (pkt->isRead() || pkt->isWrite()) { // 获得数据包的地址 Addr addr = pkt->getAddr(); // 根据数据包地址,判断段号,并获取段偏移,根据块大小获取组(group)号 int segNum = whichSeg(addr); // getSegAddr(addr) = addr % hbmSize // addr在Seg里的offset Addr segAddr = getSegAddr(addr); // 段组号,就是这个段里面第几个块,值等于 addr % hbmSize / blockSize int grpNum = segAddr / blockSize;
// Addr address only when used // 对块大小减一再按位取反,和segAddr按位与操作,得到segBlock地址,相关操作可以参见之前块地址计算相关 // 本质是将 segAddr 对齐到 blockSize 的整数倍位置 Addr segBlockAddr = segAddr & ~(Addr(blockSize - 1)); // 如果 segBlockAddr 超过了 segGrps 的最后一个地址,将会添加新的entry if (segBlockAddr > segGrps.back().addr) { DPRINTF(ChameleonCtrl, "Adding entry "\ "from %#x to %#x\n",\ segGrps.back().addr, segBlockAddr); for (Addr addr_tmp = segGrps.back().addr; addr_tmp <= segBlockAddr; addr_tmp += blockSize) {// 其实应该 +=segment_size 的,只是Chameleon里都是64B // 在需要时,将根据段组的边界地址添加新的段组条目。 segGrpEntry tmpEntry(addr_tmp, ddrRatio); segGrps.emplace_back(tmpEntry); } } // entryPtr 指向这个segGrp【x】 segGrpEntry* entryPtr = &segGrps[grpNum]; // 如果 entryPtr 在缓存模式并且segNum指的是HBM那个segment,则会根据规则重新设置地址,并向 memPort 发送功能性请求 if (entryPtr->isCache() && // 也就是Segment【3】存着的是segNum对应的数据,也就是被缓存了,因为Segment【3】是HBM entryPtr->tags[ddrRatio] == segNum) { // in cache mode and caching the data accessed
// ddrRatio*hbmSize实际上就是DRAM大小,加上segAddr就是在HBM当中了 // 也就是说它请求(假设)是Seg1的某个片段,然后发现其实它被cache了,那去cache访问会快一些,所以remap一下 Addr addr_new = ddrRatio*hbmSize + segAddr; pkt->setAddr(addr_new);
DPRINTF(ChameleonCtrl, "Setting packet address "\ "from %#x to %#x\n", addr, addr_new); // 得处理一下这个数据 memPort.sendFunctional(pkt); // 猜测:这个pkt不一定仅仅被这个函数调用,所以得被请求的地址修改回来。 pkt->setAddr(addr); return;
} else { // 发送功能请求数据包,在不影响任何数据块的当前状态或移动数据块的情况下,即时更新内存系统中各处的数据。 // 不论是读或写请求,最终都会发送到 memPort 处理 memPort.sendFunctional(pkt); return; } } memPort.sendFunctional(pkt); return;}xxxxxxxxxx /** * The number of segGrpEntrys should be defined when * initialization of ChanmeleonCtrl. */ std::vector<segGrpEntry> segGrps;
recvFunctional
处理从 CPU 端口接收到的功能性(functional)访问请求
xxxxxxxxxxvoidChameleonCtrl::CPUSidePort::recvFunctional(PacketPtr pkt){ DPRINTF(ChameleonCtrl, "Got functional %s\n", pkt->print()); return owner->functionalAccess(pkt);}
tryTiming
用于判断是否可以接受传入的定时请求
xxxxxxxxxxboolChameleonCtrl::CPUSidePort::tryTiming(PacketPtr pkt){ // isExpressSnoop 方法检查该包是否是快速嗅探包(Express Snoop Packet) if (pkt->isExpressSnoop()) { // always let express snoop packets through even if blocked DPRINTF(ChameleonCtrl, "Express snoop packet, let it pass\n"); return true; } else if (isBlocked() || mustSendRetry) { DPRINTF(ChameleonCtrl, "Request blocked\n"); mustSendRetry = true; return false; } mustSendRetry = false; return true;}快速嗅探包是一种特殊的包类型,它需要快速传递,用于缓存一致性协议中的嗅探操作
recvTimingReq
Hybrid2从这里开始的实现复杂一些(当然主要是多了更多的统计输出)
用于接收和处理定时请求(Timing Request)
x
boolChameleonCtrl::CPUSidePort::recvTimingReq(PacketPtr pkt){ DPRINTF(ChameleonCtrl, "Got request %s\n", pkt->print()); // 检查是否可以接受这个定时请求 if (tryTiming(pkt)) { // owner->handleRequest(pkt) 调用handleRequest处理请求,见下文 bool success = owner->handleRequest(pkt); if (!success) { DPRINTF(ChameleonCtrl, "Request failed when handling request\n"); return false; } DPRINTF(ChameleonCtrl, "Request succeeded\n"); return true; } return false;}在hybird2的remap相关代码中增加了一些部分:
【Hybrid2 Addition 1】增加对owner内存足迹的修改,当然这也是因为chameleon的代码没有相关的统计输出
xxxxxxxxxx if(pkt->getAddr()>owner->footprint_) { owner->footprint_=pkt->getAddr(); owner->remapStats.footprint=pkt->getAddr(); DPRINTF(RemapCtrl, "recvTimingReq pkt->getAddr()%#x\n", pkt->getAddr()); }【Hybrid2 Addtion 2】增加对数据包的一些操作,在DPRINTF(ChameleonCtrl, "Request succeeded\n");之前
xxxxxxxxxx if (pkt->isWrite() || pkt->isCleanEviction() || pkt->isEviction() || pkt->isWriteback()) { if(pkt->Is_addr_changed==true) { // pkt->setAddr(pkt->origin_addr_test); pkt->Is_addr_changed=false; } DPRINTF(RemapCtrl, "clear blocked \n"); }
MemSidePort构造函数
xxxxxxxxxxChameleonCtrl::MemSidePort::MemSidePort(const std::string& name, ChameleonCtrl* _owner) : QueuedRequestPort(name, _owner, reqQueue, snoopRespQueue), reqQueue(*_owner, *this), snoopRespQueue(*_owner, *this), owner(_owner){ }
recvTimingResp
xxxxxxxxxxboolChameleonCtrl::MemSidePort::recvTimingResp(PacketPtr pkt){ DPRINTF(ChameleonCtrl, "Receiving timing response\n"); return owner->handleResponse(pkt);}
recvRangeChange
xxxxxxxxxxvoidChameleonCtrl::MemSidePort::recvRangeChange(){ DPRINTF(ChameleonCtrl, "Receiving range change\n"); owner->sendRangeChange();}
access
处理数据包时调用该函数(Hybrid2 对此进行了一定注释:handleRequest函数时用,用于双向/单向交换时发出readpkt)。
【Hybrid2在这里实现是与Chameleon大不相同的】
如果访问到HBM地址,将一个cache模式的HBM段转换为PoM
所有挂在reqQueue上的数据包绝对不能被预处理。 因此,访问函数将在handleDeferredPacket中被调用。
如果数据包没有被延迟处理,则返回true。无论地址是否发生变化。
注:一组segments 组成为【1 HBM segment + 多个(设置成3)DDR Segment】 【 Segment size = 64B (e.g,)】
x
boolChameleonCtrl::access(PacketPtr pkt){ assert(pkt->isRequest()); // 获得请求的地址 Addr addr = pkt->getAddr();
int segNum = whichSeg(addr); Addr segAddr = getSegAddr(addr); int grpNum = segAddr / blockSize; // Addr offset = segAddr % blockSize;
// Addr address only when used Addr segBlockAddr = segAddr & ~(Addr(blockSize - 1)); // 请求的块SegBlock地址超过segGrps最后一条Entry对应的偏移量的话 if (segBlockAddr > segGrps.back().addr) { // 新增segGrpEntry DPRINTF(ChameleonCtrl, "Adding entry "\ "from %#x to %#x\n",\ segGrps.back().addr, segBlockAddr); // 从segGrps最后一个Entry,一直新增到segBlockAddr for (Addr addr_tmp = segGrps.back().addr; addr_tmp <= segBlockAddr; addr_tmp += blockSize) {
segGrpEntry tmpEntry(addr_tmp, ddrRatio); segGrps.emplace_back(tmpEntry); } } // 这个时候segGrps里已经有segBlockAddr相关的segGrpEntry.也就是segGroup-X segGrpEntry* entryPtr = &segGrps[grpNum];
// If busy, simply hang it to the queue // 如果当前entryPtr指向的对象忙,就丢到reqQueue if (entryPtr->isBusy()) { // Remember to handle it when handling response entryPtr->reqQueue.push_back(pkt);
DPRINTF(ChameleonCtrl, "Entry of address %#x is busy, "\ "hang up the packet\n", addr);
return false; } // 如果对应的segGrp是Part of Memory模式,不需要remap if (!entryPtr->isCache()) { // the entry is in PoM mode, just access the true address // no remap, since HBM is in the larger address.
/** * @todo swap hot data to HBM segment? * */ DPRINTF(ChameleonCtrl, "Address %#x is in PoM mode\n", addr);
stats.pomAccess++; stats.segAccess++;
return true; }
// 如果对应的segGrp是cache模式, DPRINTF(ChameleonCtrl, "Address %#x is in cache mode\n", addr); // e.g. ddrRation=3的话 总共4份HBM_SIZE大小的地址空间 分别编号0,1,2,3 // 因此segNum = ddrRatio的时候,也就是访问了HBM的地址空间 if (segNum == ddrRatio) { // hbm segment is accessed! stats.toPom++; // 如果脏了的话,就需要把数据刷回 if (entryPtr->isDirty()) { // if dirty, write back sendReadPacket(entryPtr, addr, ddrRatio,\ entryPtr->tags[ddrRatio], curTick()); entryPtr->reqQueue.push_back(pkt);
DPRINTF(ChameleonCtrl, "Dirty, write back and turn this segment"\ "into PoM mode\n");
entryPtr->setCacheMode(false); entryPtr->tags[ddrRatio] = ddrRatio; entryPtr->setBusy(true);
return false; } else { // if not dirty, just turn to PoM mode DPRINTF(ChameleonCtrl, "Not dirty, turn this segment"\ "into PoM mode\n");
entryPtr->setCacheMode(false); entryPtr->tags[ddrRatio] = ddrRatio;
stats.pomAccess++; stats.segAccess++;
return true; } } else if (entryPtr->tags[ddrRatio] == segNum) { // HBM is now caching the accessed data if (pkt->isWrite()) { // need to write back later entryPtr->setDirty(true); }
DPRINTF(ChameleonCtrl, "Address %#x is in cache mode "\ "and caching the data in need\n", addr);
// Remap to the HBM address Addr addr_new = ddrRatio*hbmSize + segAddr; pkt->setAddr(addr_new);
// use the sender state to store the original address if (pkt->needsResponse()) { pkt->pushSenderState( \ new ChameleonCtrlSenderState(addr)); }
stats.cacheAccess++; stats.segAccess++;
return true;
} else {
DPRINTF(ChameleonCtrl, "Address %#x is in cache mode "\ "and caching other data\n", addr);
// HBM is now caching other data. Finish it and // cache the accessed data. if (!entryPtr->isDirty()) { // send read packets to get the data and cache it. // the data read should be written to hbm sendReadPacket(entryPtr, addr, segNum, ddrRatio, curTick());
entryPtr->tags[ddrRatio] = segNum;
entryPtr->setBusy(true);
DPRINTF(ChameleonCtrl, "Not dirty, just cache it\n");
// add this packet to the dfpkt queue entryPtr->reqQueue.push_back(pkt);
return false;
} else { // entry is dirty, write back and cache the new data. // do both at the same time.
/** * read dirty data from hbm * @warning read to hbm must be ahead of other read * packets */ sendReadPacket(entryPtr, segAddr + hbmSize*ddrRatio,\ ddrRatio, entryPtr->tags[ddrRatio],\ curTick());
// read data and cache it later sendReadPacket(entryPtr, addr, segNum, ddrRatio,\ curTick() + 100);
entryPtr->tags[ddrRatio] = segNum; entryPtr->setBusy(true);
DPRINTF(ChameleonCtrl, "Dirty, write back and cache it\n");
// add this packet to the dfpkt queue entryPtr->reqQueue.push_back(pkt);
return false; } }}
sendReadPacket
x
voidChameleonCtrl::sendReadPacket(segGrpEntry* entryPtr, Addr srcAddr, int srcNum, int destNum, Tick sendTime){ PacketPtr read_pkt = createReadPacket(srcAddr); // Schedule the sending of a timing request memPort.schedTimingReq(read_pkt, curTick() + 10); // 说明读取的数据应写入什么地方 // -1: not sending at all // readTypes[1] = 3 读的packet送到第1(数组下标0开始)个Segment,读的数据写到第3个Seg ? entryPtr->readTypes[srcNum] = destNum;}
handleRequest
xxxxxxxxxxboolChameleonCtrl::handleRequest(PacketPtr pkt){ assert(pkt->isRequest()); DPRINTF(ChameleonCtrl, "Got request for addr %#x\n", pkt->getAddr());
bool success = access(pkt);
// Simply defined latency. Should be more precious later. // Tick latency = pkt->headerDelay; // memPort.schedTimingReq(pkt, curTick() + latency); if (success && !isBlocked()) { memPort.schedTimingReq(pkt, curTick()); } return true;}
writeBack
主要作用是处理接收到的响应数据包,并根据数据包中的地址和状态信息,将数据写回到指定的目标地址中
xxxxxxxxxx /** * Invoked when handling timing response. Receive the read * packet sent by ChameleonCtrl, get the data, and write * back according to entryPtr->readTypes. Should check * the metadata, and deal with the deferred packets if * all writebacks are completed. * * @param pkt The read response packet from memory. * @return true when the migration is finished. (Fetch both data, * send waitingPacket and clearBlocked.) */
x
boolChameleonCtrl::writeBack(PacketPtr pkt){ // 根据pkt 得到read地址 Addr addr = pkt->getAddr(); // 然后计算得到这个数据包位于哪个segment,在这个segment里的偏移量segAddr,在这个segment里是第几个块 int segNum = whichSeg(addr); Addr segAddr = getSegAddr(addr); int grpNum = segAddr / blockSize; // 指向这个SegEntry segGrpEntry* entryPtr = &segGrps[grpNum];
// entry must be busy assert(entryPtr->isBusy()); // 数据要被写回到哪里,根据segNum找到SegEntry的readType对应的目标Segment编号 乘上HBMSize 加偏移量得到目标地址 Addr destAddr = entryPtr->readTypes[segNum]*hbmSize\ + segAddr;
/** * @warning may cause panic! * If everything is in this order: * 1. read hbm's data because it is dirty * 2. read data from addr1 * 3. write addr1's data to hbm * 4. write hbm's data to addr2 * * I think no need to worry about this: * even if hbm is busy, write to hbm will * be strictly later than read from hbm. */ // 创建一个数据包,交给memPort来调度 uint8_t *data = new uint8_t[blockSize]; // writeDataToBlock:将数据从数据包复制到提供的块指针中,该块指针按给定的块大小对齐 pkt->writeDataToBlock(data, blockSize); PacketPtr write_pkt = createWbPacket(destAddr, data); memPort.schedTimingReq(write_pkt, curTick());
// 当前entry对应的segnum对应的readType没有回写任务,标记回-1 // No writeback task, set it back to -1 entryPtr->readTypes[segNum] = -1;
bool isClear = true; // 看看其它SegMent对应的readType for (int tmpDestNum : entryPtr->readTypes) { if (tmpDestNum != -1) isClear = false; } // 如果对应的readType都是-1,意味着这个SegEntry不忙 if (isClear) { entryPtr->setBusy(false); entryPtr->setDirty(false); // handleDeferredPacket:当一个TlbEntry变为就绪时调用此函数。所有延迟队列中的数据包应该被清除 handleDeferredPacket(entryPtr, curTick());
return true; } return false;}
handleResponse
用于处理接收到的响应数据包。如果数据包是向CPU发送的响应,它会恢复数据包的状态和地址,并将响应发送回CPU
xxxxxxxxxxboolChameleonCtrl::handleResponse(PacketPtr pkt){ // 确保接收到的数据包pkt确实是一个响应包(response) assert(pkt->isResponse()); DPRINTF(ChameleonCtrl, "Got response for addr %#x\n", pkt->getAddr()); // 如果条件成立,表示数据包的目标是CPU,因此程序需要将数据包返回给CPU if (pkt->requestorId() != MemSideRequestorId()) { // The packet is towards CPU. Just send it back.
//使用SenderState将pkt地址改回. // 尝试将数据包pkt中的senderState转换为ChameleonCtrlSenderState类型。 // 如果转换成功(receivedState不为空),表示数据包在发送时曾经被修改过其状态 ChameleonCtrlSenderState* receivedState = dynamic_cast<ChameleonCtrlSenderState*>(pkt->senderState); // 如果senderState转换成功,说明数据包的状态已经被修改过 if (receivedState != NULL) {
// Change address back only when it has a state. // 将数据包的senderState恢复为先前保存的状态(predecessor) pkt->senderState = receivedState->predecessor; // 获取先前保存的数据包原始地址 Addr orig_addr = receivedState->origAddr; // 将数据包的地址设置回原始地址 pkt->setAddr(orig_addr);
DPRINTF(ChameleonCtrl, "Setting packet back to its original"\ "address %#x\n", orig_addr);
/** * @warning Should restore the senderState if the * packet is not successfully sent. * @todo Still wonder how to return bool by schedTimingResp. */ // 删除先前保存的状态对象,释放内存 delete receivedState; } // 获取数据包的延迟时间。 Tick latency = pkt->headerDelay; // 调度数据包pkt在CPU端口上的响应发送,发送时间为当前时钟周期(curTick())加上延迟时间(latency) cpuPort.schedTimingResp(pkt, curTick() + latency);
return true;
} else {// 如果数据包的请求者ID等于MemSideRequestorId(),表示响应是发送给ChameleonCtrl的 DPRINTF(ChameleonCtrl, "Receiving response for ChameleonCtrl %s\n", pkt->print()); // bool finished = writeBack(pkt); writeBack(pkt); }
return true;}
handleDeferredPacket
处理段组条目(segGrpEntry)中的延迟请求队列(reqQueue)。它逐个处理队列中的数据包,尝试访问并发送每个数据包,如果访问失败则返回当前发送时钟周期,以便稍后重新尝试发送。
xxxxxxxxxxTick ChameleonCtrl::handleDeferredPacket(segGrpEntry* entryPtr, Tick startTick){ Tick sendTick = startTick; // 初始化发送时钟周期为起始时钟周期
while (!entryPtr->reqQueue.empty()) { PacketPtr dfpkt = entryPtr->reqQueue.front(); // 获取队列中的第一个数据包 entryPtr->reqQueue.pop_front(); // 弹出队列中的第一个数据包 sendTick += dfpkt->headerDelay; // 根据数据包的头延迟更新发送时钟周期
bool success = access(dfpkt); // 调用access函数,执行数据包的访问操作
if (success) { memPort.schedTimingReq(dfpkt, sendTick); // 在内存端口上安排数据包的定时请求发送 DPRINTF(ChameleonCtrl, "Sending deferred packet %s\n", dfpkt->print()); // 打印日志,指示正在发送延迟数据包 } else { // 如果访问失败,表示设备或资源忙碌 DPRINTF(ChameleonCtrl, "Busy again!\n"); return sendTick; // 返回当前发送时钟周期,表示未能成功发送数据包 } }
DPRINTF(ChameleonCtrl, "Deferred request queue all clear\n"); return sendTick; // 返回最终发送时钟周期,表示延迟请求队列已全部处理完毕}
createWbPacket
创建一个写回数据数据包,并将指定的数据指针 data_ptr 设置到该数据包中
x
PacketPtrChameleonCtrl::createWbPacket(Addr mem_addr, uint8_t *data_ptr){ // Create a new write back request // Using the common RequestorId for writeback RequestPtr req = std::make_shared<Request>( mem_addr, blockSize, 0, Request::wbRequestorId);
PacketPtr new_pkt = new Packet(req, MemCmd::WritebackDirty, blockSize); // new_pkt->allocate();
// Not quite sure which function to use to set data // new_pkt->setData(data_ptr); new_pkt->dataDynamic(data_ptr);
return new_pkt;}RequestPtr req = std::make_shared<Request>(mem_addr, blockSize, 0, Request::wbRequestorId);
创建一个新的写回请求 (
Request) 对象。mem_addr:目标内存地址。blockSize:数据块的大小。0:请求标志,这里没有特别的标志。Request::wbRequestorId:写回请求的请求者ID,通常用于标识该请求是由写回操作发起的。
PacketPtr new_pkt = new Packet(req, MemCmd::WritebackDirty, blockSize);
创建一个新的数据包 (
Packet) 对象。req:之前创建的请求对象。MemCmd::WritebackDirty:数据包命令类型,表示这是一个写回脏数据的操作。blockSize:数据块的大小。
new_pkt->dataDynamic(data_ptr);
将数据指针
data_ptr设置为数据包的新数据。dataDynamic函数将动态分配和管理数据指针data_ptr的内存。
dataDynamic
将数据指针设置为一个应该用 delete [] 释放的值。动态数据是该数据包特有的,当数据包从源头传递到目的地时,转发的数据包将分配它们自己的数据。当一个数据包到达最终目的地时,它将填充该特定数据包的动态数据,并在返回源头的途中,在每一个创建新数据包的步骤中(例如在缓存中)都会调用 memcpy。最终,当响应到达源头时,需要进行最后一次 memcpy 来从数据包中提取数据,然后再释放数据包.
createReadPacket
创建一个读取数据包,并分配必要的内存
xxxxxxxxxxPacketPtrChameleonCtrl::createReadPacket(Addr mem_addr){ // Create a new read request // Use the ChameleonCtrl's unique requestor id // 创建一个新的读取请求 (Request) 对象 RequestPtr req = std::make_shared<Request>( mem_addr, blockSize, 0, MemSideRequestorId()); // 创建一个新的数据包 (Packet) 对象 PacketPtr new_pkt = new Packet(req, MemCmd::ReadReq, blockSize); // 分配数据包内部数据结构的内存。确保数据包有足够的空间来存储读取的数据 new_pkt->allocate();
return new_pkt;}
HBM_project映射实现的差异
access
首先是出现的不同的实现的结构体:
simpleTlbEntry: 用于表示简单的地址重映射条目,包含两个不同内存地址之间的映射信息及相关状态,相应的两个地址严格来自两种不同的内存Addr mem1Addr来自内存介质1的地址Addr mem2Addr来自内存介质2的地址oneWay表示是否是单向迁移mem1Ready表示内存介质1是否已经准备好mem2Ready表示内存介质2是否已经准备好ready指示两内存地址中的数据是否已准备好使用,当迁移完成时,该值应设为truemem1Data:存储内存1中的数据。mem2Data:存储内存2中的数据。is_dram_to_hbm指示当前的迁移方向是否是从 DRAM 到 HBMneedWait用于表示是否需要等待。特别是在从地址A迁移到地址B(a->b)时,如果迁移尚未完成,则不能进行从B到A(b->a)的读取操作,否则读取到的数据将是旧数据,可能会导致错误redQueue保存来自 CPU 的请求包。 当这个条目准备好时,应清空所有队列。xxxxxxxxxxvoid wtMem1Data(uint8_t* data) {mem1Data = data;mem1Ready = true;}这个函数将
data写入mem1Data,并将mem1Ready标志设为true,表示内存1的数据已准备好xxxxxxxxxxvoid wtMem2Data(uint8_t* data) {mem2Data = data;mem2Ready = true;}这个函数将
data写入mem2Data,并将mem2Ready标志设为true,表示内存2的数据已准备好xxxxxxxxxxvoid setAllReady() {//适用于one way以及double wayready = true;mem1Data = nullptr; mem2Data = nullptr;mem1Ready = false; mem2Ready = false;// mem1Wb = false; mem2Wb = false;// valid = true;}这个函数将所有相关标志和数据指针重置:
将
ready设为true,表示数据已准备好。将
mem1Data和mem2Data设为nullptr。将
mem1Ready和mem2Ready设为false。注释掉的部分(
mem1Wb,mem2Wb,valid)可能用于将来扩展或曾经用过的功能,现在暂时不用
x
bool isOneWay() {return oneWay;}bool isMem1Ready() {return mem1Ready;}bool isMem2Ready() {return mem2Ready;}bool isReady() {return ready;}
x
boolRemapCtrl::access(PacketPtr pkt)//handleRequest函数时用,用于双向/单向交换时发出readpkt{ assert(pkt->isRequest()); DPRINTF(RemapCtrl, "access pkt->getAddr()%#x\n", pkt->getAddr()); /** * @warning A simple if condition here. May cause problem. */ Addr addr_orig = pkt->getAddr(); // Addr block_addr_orig = pkt->getBlockAddr(blockSize); // Addr block_addr_orig=addrcontroller.Get_block_addr(pkt->getAddr());//根据自己定义的block大小进行block对齐 Addr block_addr_orig=( (pkt->getAddr()>>cache_block_bits)<<cache_block_bits );//根据64B进行block对齐
// 判断是不是来自Mem1这个内存介质 bool _isMem1 = isMem1(addr_orig); // 根据对齐后的地址去mem1或者mem2两种内存介质分别去找到对应simpleTlbEntry的项(simpleTlb[set_id]中的最后一项) // 要搜索简单 TLB(Translation Lookaside Buffer)并查找原始地址是否在表 simpleTlbEntry* entryPtr = findByAddr_access(block_addr_orig, _isMem1);
if (entryPtr == nullptr) { return true; }
else if(entryPtr->isReady()) { return true; } else // 如果找到的 TLB 条目未准备好,将请求包添加到条目的请求队列中,并返回 false { // assert(!entryPtr->isReady()); entryPtr->reqQueue.push_back(pkt); return false; } }介绍一下这边出现的内存根据指定大小对齐的操作:
Addr block_addr_orig = ( (pkt->getAddr() >> cache_block_bits) << cache_block_bits );pkt->getAddr()这部分获取了一个地址,假设该地址是A。pkt->getAddr() >> cache_block_bitscache_block_bits通常是与缓存块大小相关的一个值。如果缓存块大小是64字节,那么cache_block_bits应该是6,因为2^6 = 64。右移cache_block_bits位相当于除以2^cache_block_bits。所以,这部分代码执行的操作是将地址A右移6位,即A / 64,得到一个整数部分B。(pkt->getAddr() >> cache_block_bits) << cache_block_bits将结果
B再左移6位,即B * 64,恢复到一个以64字节为单位对齐的地址
e.g.
假设
pkt->getAddr()返回的地址A = 12345,并且cache_block_bits = 6。12345 >> 6 = 192: 右移6位相当于除以64(丢弃小数部分),结果是192192 << 6 = 12288: 左移6位相当于乘以64,结果是12288。12288是12345向下对齐到最近的64字节块的起始地址。换句话说,12288是12345所在的那个64字节块的起始地址
functionalaccess
代码和access几乎一模一样,区别在参数列表接收了一个simpleTlbEntry** 即指向指针的指针类型的参数传入
在 C++ 中,双指针用于以下几个场景:
函数修改指针的值:当你需要一个函数能够修改它所接收的指针的值(即指向不同的对象),而不仅仅是修改指针所指向的对象时,你可以使用双指针。
动态二维数组:双指针也常用于实现动态的二维数组。
simpleTlbEntry** 主要用于第一个场景,即传递一个指向指针的指针,以便在函数内修改指针的值并在函数外部反映这个修改。
x
bool RemapCtrl::functionalaccess(PacketPtr pkt, simpleTlbEntry** entryPtr){ // entryPtr = nullptr; assert(pkt->isRead() || pkt->isWrite()); DPRINTF(RemapCtrl, "functionalaccess pkt->getAddr()%#x\n", pkt->getAddr());
Addr addr_orig = pkt->getAddr(); DPRINTF(RemapCtrl, "functionalaccess huayifan aaa\n"); // Addr block_addr_orig = pkt->getBlockAddr(blockSize); // Addr block_addr_orig=addrcontroller.Get_block_addr(pkt->getAddr());//根据自己定义的block大小进行block对齐 Addr block_addr_orig=( (pkt->getAddr()>>cache_block_bits)<<cache_block_bits );//根据64B进行block对齐
DPRINTF(RemapCtrl, "functionalaccess huayifan bbb\n"); bool _isMem1 = isMem1(addr_orig);
DPRINTF(RemapCtrl, "functionalaccess huayifan ccc\n"); *entryPtr = findByAddr_access(block_addr_orig, _isMem1);
DPRINTF(RemapCtrl, "functionalaccess huayifan ddd\n");
if (*entryPtr == nullptr) { DPRINTF(RemapCtrl, "functionalaccess huayifan eee\n"); return true; }
else if((*entryPtr)->isReady()) { DPRINTF(RemapCtrl, "functionalaccess huayifan fff\n"); return true; } else { // assert(!entryPtr->isReady()); // entryPtr->reqQueue.push_back(pkt); DPRINTF(RemapCtrl, "functionalaccess huayifan ggg\n"); return false; }
}
AddSimpleEntry
mem1 和 mem2:表示两个内存地址,用于创建新的 simpleTlbEntry 条目。
is_oneway:表示是否单向迁移。
is_mem1Ready 和 is_mem2Ready:表示 mem1Data 和 mem2Data 是否准备好。
is_ready:表示整个迁移过程是否完成。
mem1Data 和 mem2Data:表示两个内存地址中的数据。
is_dram_to_hbm:表示数据迁移的方向。
block_size_ 和 blockSize:用于控制分块大小的参数。
xxxxxxxxxx//每次memcpy的时候调用,向simpleTlb中添加一项。注意mem1Data和mem2Data对应的是哪一个src和destvoid RemapCtrl::AddSimpleEntry(Addr mem1, Addr mem2, bool is_oneway, bool is_mem1Ready, bool is_mem2Ready, bool is_ready, uint8_t * mem1Data, uint8_t * mem2Data, bool is_dram_to_hbm)//添加一项到正在迁移表中。用在memcpy的位置{ // simpleTlbEntry temp_simpleTlbEntry(mem1, mem2, is_oneway, is_mem1Ready, is_mem2Ready, is_ready, mem1Data, mem2Data, is_dram_to_hbm); uint64_t set_id=addrcontroller.Get_set_id(mem1); assert(addrcontroller.Get_set_id(mem1) == addrcontroller.Get_set_id(mem2)); // 使用 for 循环,将每个大块分成小块(64B)并处理。检查是否需要等待,避免同时进行多个迁移操作。 for(uint64_t i=0; i<(block_size_/blockSize); i++) {//分割成64B, block_size_是blockSize的整数倍
bool need_wait=false; for(auto iter=simpleTlb[set_id].begin(); iter!=simpleTlb[set_id].end(); iter++) { if(mem1+i*blockSize==iter->mem1Addr || mem2+i*blockSize==iter->mem2Addr) { need_wait=true; break; } }
simpleTlbEntry temp_simpleTlbEntry(mem1+i*blockSize, mem2+i*blockSize, is_oneway, is_mem1Ready, is_mem2Ready, is_ready, mem1Data, mem2Data, is_dram_to_hbm, need_wait); simpleTlb[set_id].push_back(temp_simpleTlbEntry); if (temp_simpleTlbEntry.isOneWay()) { if (is_dram_to_hbm) { // Only need to read data from mem1 DPRINTF(RemapCtrl, "One-way migrating data from address %#x to %#x\n", temp_simpleTlbEntry.mem1Addr, temp_simpleTlbEntry.mem2Addr);
if(temp_simpleTlbEntry.need_wait==false) { PacketPtr read_pkt = createReadPacket(\ temp_simpleTlbEntry.mem1Addr); memPort.schedTimingReq(read_pkt, curTick());
}
} else if (!is_dram_to_hbm) { // Only need to read data from mem2 DPRINTF(RemapCtrl, "One-way migrating data from address %#x to %#x\n", temp_simpleTlbEntry.mem2Addr, temp_simpleTlbEntry.mem1Addr);
if(temp_simpleTlbEntry.need_wait==false) { PacketPtr read_pkt = createReadPacket(\ temp_simpleTlbEntry.mem2Addr); memPort.schedTimingReq(read_pkt, curTick());
}
} else { panic("error, AddSimpleEntry\n"); } } else { // Send 2 read packets. DPRINTF(RemapCtrl, "double swap, Migrating data from address \ %#x to %#x\n", temp_simpleTlbEntry.mem1Addr, temp_simpleTlbEntry.mem2Addr);
if(temp_simpleTlbEntry.need_wait==false) { PacketPtr read_pkt1 = createReadPacket(temp_simpleTlbEntry.mem1Addr); memPort.schedTimingReq(read_pkt1, curTick());
PacketPtr read_pkt2 = createReadPacket(temp_simpleTlbEntry.mem2Addr); memPort.schedTimingReq(read_pkt2, curTick()+tickgap_between_two_pkt); } } } }
gem5实现Design的思路
最主体的部分是一个负责分发数据这种的内存控制器(例如
remap_ctrl.cc/hh,chameleon_ctrl.cc/hh)
还有一个是负责真正Design部分的逻辑的部分,包括一些状态位怎么样变、数据应该怎么样迁移等(
block_and_page_granularity_HBM_prior.cc/hh)。内存控制器通过头文件的引入
#include block_and_page_granularity_HBM_prior.hh,引入包含处理逻辑的控制器类(e.g. 在Hybrid2中class AddrController)作为design处理逻辑和控制器分发数据的媒介。
通过媒介中计算(或其他方式)得到的类似
set_idpage_idpage_offsetpage_adddr等数据,交给内存控制器进行处理。内存控制器也将通过媒介进行一些逻辑处理。
相关的代码实现之后,无需手动实现内存控制器构造时的参数类(e.g.
RemapCtrlParams相应的文件RemapCtrlParams.hh),这个文件将在编译后自动生成。
在编译之前,还需要在内存控制器实现代码的相同目录下,实现一个相应的Python类,以最后用于实例化对象并加入到
m5.object。最简单的python类实现,如下案例所示:(注意引入m5相关的包)
from m5.params import *from m5.proxy import *from m5.objects.ClockedObject import ClockedObject
class RemapCtrl(ClockedObject): type = 'RemapCtrl' cxx_header = "HBM_project/remap_ctrl.hh"
# Use only one port for CPU side cpu_side = ResponsePort("CPU side port, receives requests") mem_side = RequestPort("Memory side port, sends requests")
# a pointer to the main system # in order to get the cache block size, memory address # maybe useless? system = Param.System(Parent.any, "The system this RemapCtrl is part of")在编写完这段代码之后,需要在
SConscript(如果没有的话需要新建一个)里增加相关的python文件,以使它能够正确编译。
xxxxxxxxxxImport('*')SimObject('RemapCtrl.py')Source('block_and_page_granularity_HBM_prior.cc')Source('remap_ctrl.cc')DebugFlag('RemapCtrl', "For hbm hybrid")后续进行系统配置时只需要在导入包的部分,增加代码行
from m5.objects import *即可在后续进行使用在Hybrid2中进行的
RemapCtrl配置,即可完成对象仿真。x
if options.hbm_controller:system.hbm_ctrl = RemapCtrl()system.ctrlbus = VirtualXBar()system.ctrlbus.mem_side_ports = system.hbm_ctrl.cpu_sidesystem.hbm_ctrl.mem_side = system.membus.cpu_side_ports
上面代码中出现的
options.hbm_controller为命令行相关的操作如果需要在命令行新增类似
--hbm-controller相关的命令,只需要在configs/common/Options.py中,在def addSEOptions(parser):中新增相关命令即可。例如我在命令行试图加入
--parsec命令:# parsecparser.add_option('--parsec',type="string",default="",help="Specify the parsec benchmark to run.")只需要增加这样一段代码即可
Run_parsec.sh脚本说明
parsec解压出的benchmark有13种,每种对应5种模式,分别是simdev simlarge simmedium simsmall test。
x
GEM5_DIR=/home/dell/jhlu/gem5_hybrid2BENCH_DIR=/home/dell/jhlu/parsec/benchmark
ARGC=$#if [[ "$ARGC" < 1 ]]; then echo "set parsec size [dev->0 L->1 M->2 S->3 T->4]" echo "USAGE: run_parsec.sh [size you set up]" exitfi
# 获取当前脚本所在的目录路径current_dir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
size=$1echo "$size"
cd "$BENCH_DIR"
# 初始化一个空数组来存储benchmark名,命名为elementsfile_array=()
# 检查 size 是否已经定义if [ -z "$size" ]; then echo "Error: size is not set" exit 1fi
if [[ "$size" == 0 ]]; then echo "Choose simdev !" while IFS= read -r -d '' file; do file_array+=("$(basename "$file")") done < <(find "$BENCH_DIR" -type f -name "*simdev.rcS" -print0)
elif [[ "$size" == 1 ]]; then echo "Choose simlarge !" while IFS= read -r -d '' file; do file_array+=("$(basename "$file")") done < <(find "$BENCH_DIR" -type f -name "*simlarge.rcS" -print0)
elif [[ "$size" == 2 ]]; then echo "Choose simmedium !" while IFS= read -r -d '' file; do file_array+=("$(basename "$file")") done < <(find "$BENCH_DIR" -type f -name "*simmedium.rcS" -print0)
elif [[ "$size" == 3 ]]; then echo "Choose simsmall !" while IFS= read -r -d '' file; do file_array+=("$(basename "$file")") done < <(find "$BENCH_DIR" -type f -name "*simsmall.rcS" -print0)
elif [[ "$size" == 4 ]]; then echo "Choose simtest !" while IFS= read -r -d '' file; do file_array+=("$(basename "$file")") done < <(find "$BENCH_DIR" -type f -name "*test.rcS" -print0)
else echo "size must be in [dev->0 L->1 M->2 S->3 T->4]"fi
# # parsec -> x86? ALPHA ? Using ARM may suffer from unknow problems# $GEM5_DIR/build/X86/gem5.opt -d $GEM5_DIR/parsec_trace/
# 判断file_array是否为空if [ ${#file_array[@]} -eq 0 ]; then echo "benchmark_array is empty"else echo "benchmark_array is not empty"fi
cd "$current_dir"
# 设置信号处理函数,捕获 Ctrl+C 信号trap 'echo "Ctrl+C pressed. Exiting script."; exit 1' INT
# 实测在full system模式下可以正常运行和输出结果for benchmark in "${file_array[@]}"; do echo "Processing $benchmark" || exit 1 echo "sh ${BENCH_DIR}/${benchmark}" bcmark=$(echo "$benchmark" | cut -d'_' -f1) M5_PATH=./full_system_images/system \ $GEM5_DIR/build/X86/gem5.opt -d $GEM5_DIR/parsec_trace/$bcmark --debug-flags=MemoryAccess \ $GEM5_DIR/configs/example/se.py --num-cpus=1 --cpu-type=TimingSimpleCPU \ --cpu-clock=2200MHz --caches --l2cache \ --script=$BENCH_DIR/$benchmark -I 10000 --disk-image=x86root-parsec.img --kernel=x86_64-vmlinux-2.6.28.4-smp || exit 1done
# 实测在se模式下 上述代码不可以使用 # --script 参数可以用于在全系统模式(FS mode)下执行 .rcS 脚本文# 而 --cmd 参数用于在系统仿真模式(SE mode)下执行应用程序# SE 模式下,gem5 不直接支持 .rcS 脚本文件,因为这些脚本通常依赖于操作系统环境。# 需要提取这些命令并在 --cmd 参数中使用:(实测也不太行)# 不可用for benchmark in "${file_array[@]}"; do echo "Processing $benchmark" || exit 1 bcmark=$(echo "$benchmark" | cut -d'_' -f1) scriptPath="${BENCH_DIR}/${benchmark}" M5_PATH=./full_system_images/system \ $GEM5_DIR/build/X86/gem5.opt -d $GEM5_DIR/parsec_trace/$bcmark --debug-flags=MemoryAccess \ $GEM5_DIR/configs/example/se.py --num-cpus=1 --cpu-type=TimingSimpleCPU \ --cpu-clock=2200MHz --caches --l2cache \ --parsec=$scriptPath -I 10000 || exit 1done