Memstrata (OSDI'24)
【Title】Managing Memory Tiers with CXL in Virtualized Environments
【定语描述】the first multi-tenant memory management software stack for hardware-managed tiered memory
Comments
CXL的使用场景主要还是包括内存扩展、内存池化、或者Host-Device共享内存。那不管是内存扩展还是池化,尤其是池化,最大的价值应该是去最大化利用资源。因此多租户共享底层的计算资源的云服务场景看起来就非常适合CXL的使用场景。多租户共享底层的计算资源的云服务场景也主要是虚拟化的场景,因此为虚拟化场景优化异构内存在CXL时代确实是一个非常有意义的工作,这也是传统的一些工作没有考虑的问题。
文章有很多值得借鉴的想法,比如利用L3 Cache Miss Latency去代表Local Memory Miss,从而会后续的页面降级升级提供指导。因为频繁的Local Memory Miss很显然会导致性能下降。又比如利用Page Coloring的机制把存在cacheline竞争的page丢到一个VM里,去避免VMs之间的资源竞争(干扰)。
其他就是比较经典的做法,最后都搞个机器学习模型做预测。
下面这段话与本论文无关,看到一些人的Discussion,就顺便记录理解加工缝合一下
不同的Workload会对资源的需求不同,主要也包括两个大类吧。一个是Compute Bound,另一类是Memory Bound。Memory Bound又大致可以分为Latency Sensitive / Bandwidth Sensitive。CXL-Memory的Latency比Remote NUMA延迟可能会慢 >= 35%(MICRO'23 Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices) 。这样的话CXL-Memory + Local Memory对于Latency Sensitive / Bandwidth Sensitive Workload的表现、以及对比纯Local Memory在Latency Sensitive / Bandwidth Sensitive Workload的表现可能会有一些新的启发。有同领域的学者认为现行的异构内存方案(冷热识别)的路并不是一条完全正确的道路,该学者认为异构内存可能需要更多地去考虑Bandwidth Partition的问题。
这篇文章对Intel的各种技术相当熟悉,不熟悉Intel的一些功能,其实是很难复现的。OSDI另一篇异构内存的Nomad也有Intel参与,看起来Intel对这个非常重视(内卷)。
在论文写作相关方面
design部分的东西不算太多,但也算是比较巧妙,主要是基于Intel Flat Memory Mode的性能分析和虚拟化环境下的实验非常饱和。使得论文在Motivation上非常扎实。文章写作手法也非常有味道,值得学习。
相关概念
Multi-Tenancy
在云服务场景下,多租户是指在同一个物理计算资源(如服务器、存储、网络等)上,运行多个逻辑上隔离的租户实例。这些租户共享底层的计算资源,但它们的数据和操作是相互隔离的。租户(Tenant)可以是一个组织、一组用户、或者一个应用实例。在云环境中,租户通常是一个客户或用户组,他们使用相同的云服务平台,但在逻辑上是分开的。
Page Coloring
中文译名 页着色
当多个虚拟内存页面映射到相同的缓存行时,可能会发生缓存冲突。这意味着不同的内存页面争用同一缓存行,导致缓存性能下降。Page Color是指为每个物理页面分配一个唯一的标识符,以便在缓存映射时考虑缓存行的布局。它用于确保不同的虚拟内存页面不会映射到同一缓存行,从而减少冲突.
在 page coloring 机制中,物理内存被分为若干组,每组的页面具有相同的颜色。通过将虚拟页面映射到不同颜色的物理页面上,可以避免缓存冲突。Page Color的分配通常基于页面的物理地址和缓存的布局。例如,缓存的地址范围可能会被划分为几个区域,每个区域对应一个颜色。
当系统分配新的物理页面时,它会考虑页面的颜色,以确保新页面不会与已存在的页面发生冲突。操作系统或内存管理单元会根据页面颜色策略,分配物理内存页面,从而优化缓存的使用。
假设一个计算机系统具有 64 KB 的缓存,并且页面大小为 4 KB。缓存被划分为 16 个缓存组,每个组的大小为 4 KB。在使用 page coloring 时,物理内存页面被分配到不同的缓存组中。通过确保虚拟内存页面映射到不同的缓存组,可以减少缓存冲突。
Dedicated Local Memory
在本文中出现了这个概念。文中对Dedicated Local Memory的阐述是Intel® Flat Memory Mode支持的被暴露成第2个NUMA节点的Local Memory。从硬件上看就是加了一个Local Memory到物理地址空间,而OS将其视为NUMA节点。Local Memory Miss多的应用就可以考虑使用Dedicated Local Memory。
那么问题是为什么不直接使用大一点的Local Memory呢?Local Memory通常用于整个系统的所有进程和应用,操作系统会自行调度和内存管理,所有的Local Memory是通用的。而如果将一部分Local Memory视作NUMA节点,则由于OS对NUMA节点的内存分配策略可以指定应用程序或者进程到特定NUMA节点的内存的特性,确实可以考虑为Local Memory Miss多的应用服务。
这体现在Local Memory Miss多的应用服务显然会频繁触发CXL-Memory的访问,而这里会产生Latency和一些CPU Cycle的开销用于Access CXL-Memory以及swap等操作,进而导致性能下降。将这类应用服务绑定到Dedicated Local Memory理论上来说确实会有不错的效果。
Abstract
现有的系统使用在分层内存不同层级之间以页粒度管理数据放置,但在虚拟化环境下,基于软件的设计开销太大。
基于硬件的页面放置策略对应用无感知,进而对性能有一些影响。
这篇文章就想在Intel Flat Memory这第一款真实的为CXL设计的系统上软硬件结合。它们的实验表明,这个系统的性能和常规的DRAM差不多,对超过82%的workloads性能下降不到5%。
对于性能下降最多能达34%的异常workload,文章定义了两个主要的挑战:
memory contention across tenants 租户间的内存争用
intra-tenant contention due to conflicting access patterns 由于访问模式冲突导致的租户内争用
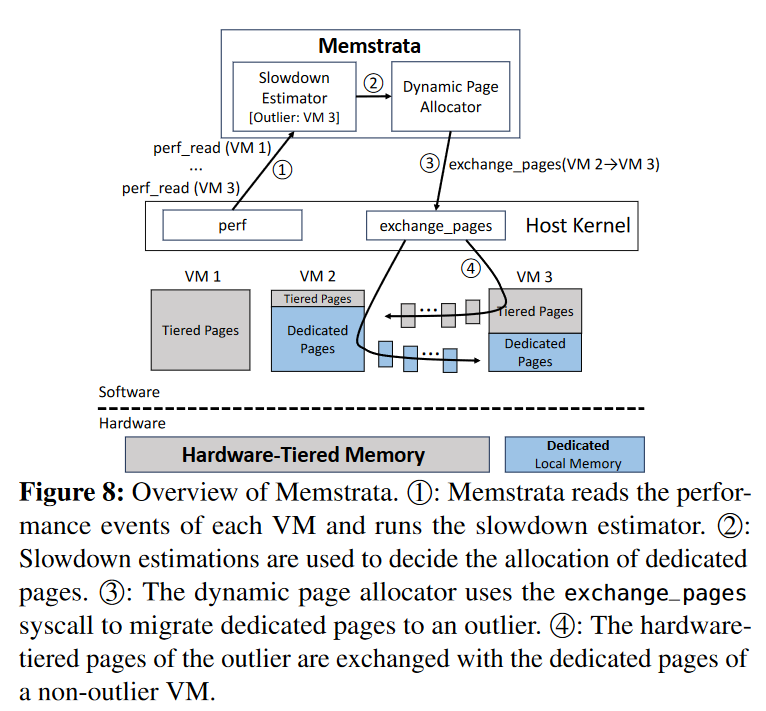
Memstrata是这篇文章提出的轻量级的多租户内存分配器。它利用page coloring页着色机制优化VM内的内存争用。它通过使用online slowdown estimator分配更多的本地 DRAM以改善对硬件分层敏感的虚拟机的性能。
Introduction
分层内存就很简单,一个主要管容量,一个主要是性能好一点,概念上一个称为capacity tier,另一个被称为performance tier。在CXL-Based DRAM/NVM+DRAM的系统中,CXL-Based DRAM/NVM主要是延迟会高一些,因此在这里就是capacity tier,而DRAM是performance tier。
软件层面的数据管理主要关注的就是冷热(访问的频繁程度),为了识别这些冷热数据,就要么是进行一些页表管理的操作、要么是使用一些采样工具。这样有一些显然的缺陷以至于general-purpose的云环境不喜欢使用:
(据本文所说,未考证)VMs不支持指令采样 并且存在隐私问题(为什么不引用论文让我看看是什么隐私问题)
细粒度的页表操作会消耗大量CPU时间(性能下降,IPC下降)
相同的页里有的块冷,有的热,还需要考虑新的机制和策略。这样的问题在使用更大页面以减小开销的
hypervisors来说问题更大。
然后就引入硬件管理的CXL层,结合软件管理的多租户隔离。
这里提到一点就是以前有过的异构内存模式 2LM 模式 ,也就是Cache模式,CXL并不支持。也就是DRAM可以做NVM的Cache但是不可以做CXL-Based DRAM/NVM的Cache。
除了Abstract介绍的观测,本文还注意到:虚拟机在同一服务器上被简单地共置时,它们可能会通过“窃取”彼此的本地 DRAM 互相干扰
然后就基于此提出the first multi-tenant memory management software stack for hardware-managed tiered memory 修饰的Memstrata。
Memstrata通过识别具有冲突缓存行的页面,使用页面着色技术将这些页面分配给同一个虚拟机,从而防止虚拟机间的干扰Memstrata利用轻量级的在线慢速估算器online slowdown estimator来评估每个虚拟机因分层内存未命中所产生的开销。它动态地在虚拟机之间分配专用的本地内存页面,以提高对内存延迟最敏感的虚拟机的性能。
Background & Detailed Information
一些简单的流水账
服务器使用的 DDR5 内存在成本和环境影响方面都具有显著影响。随着虚拟机和 CPU 核心数量的增加,云服务提供商面临更高的内存成本,尤其是使用 3D 堆叠内存时,同时内存条的制造和使用对碳排放也有不小的影响。
虽然 CXL 提供了一种扩展内存的方式,但其主要的缺点是延迟较高。这是因为 CXL 内存通过 PCIe(Peripheral Component Interconnect Express) 总线连接到 CPU,而不是直接连接在内存总线(如 DDR5 总线)上。PCIe 通道的延迟比传统内存总线更高,尤其是在高性能计算(HPC)或实时应用场景中,延迟可能对性能有显著影响。
尽管 CXL 内存通过 PCIe 通道连接,但 CXL.mem 专门为减少延迟做了优化。CXL 是在 PCIe 基础上发展的协议,它通过定制和优化 链路层(link layer) 和 事务层(transaction layer) 来降低延迟。链路层(Link Layer):管理设备之间的数据传输,确保数据正确发送、接收并确认。事务层(Transaction Layer):处理不同设备之间的通信请求,管理事务队列、存储数据包并生成相应的事务。这些优化使得 CXL 在同等 PCIe 带宽下,能够更好地支持内存访问需求,从而降低了延迟。虽然这种优化不能完全消除 PCIe 通道带来的延迟,但它能显著改善性能,尤其是在处理延迟敏感的工作负载时。
CPU 可以像访问本地内存一样,本地地访问 CXL 内存,并且这种访问是可缓存的。这意味着数据可以缓存在 CPU 的缓存层中,加速访问速度。可缓存(Cacheable)意味着 CPU 能将 CXL 内存中的数据存储到其缓存层,如 L1、L2 或 L3 缓存中,从而减少后续访问同一数据时的延迟。这种可缓存访问模式对于提升性能非常重要,尤其是在频繁访问相同数据的应用中。这种机制使 CXL 内存与 CPU 的传统内存(如 DDR5)一样,无需特别处理 缺页异常(page faults) 或使用 DMA(Direct Memory Access,直接内存访问) 进行数据传输。因此,CXL 内存的使用对软件开发人员来说相对透明,可以像普通内存一样对其进行读写。
Azure and other large cloud providers virtualize all workloads. VMs are generally small. For example, in a typical compute cluster at Azure, 40% of VMs use no more than two cores and 86% of VMs use no more than eight cores.
传统的异构内存软件机制
像TPP(ASPLOS'23) , HeMem(SOSP'21),Nimble(ASPLOS'19)主要关注的还是热度
识别热度通常需要扫描Page Table Entry的bits这样的页表操作,或者短暂unmap某个PTE引入少量的Page Fault,又或者是利用Intel PEBS/AMD IBS类似的采样机制。
文章就指出了两个主要的问题:
1)较高的Host CPU Cycle
2)粗粒度的数据放置
对于(1)的问题,首先一点就是虚拟化环境追踪细粒度的数据热度挑战很大(元数据就很大,排序也是个nlogn时间复杂度的问题),另一个问题是PEBS这种在虚拟化环境是涉及到隐私和安全问题的。所以云服务厂商主要关注的还是基于页表的一些操作。
文中给了个实验,在 7.5GB DRAM + 2.5G 2nd Mem 共10GB内存大小的空间上,在一个存内KV系统上用TPP(ASPLOS23)的方法跑YCSB。整个内存占用8.3GB,超过了Local DRAM的容量。结果是大概需要一整个核(的资源)来追踪内存访问(热度)和迁移。
但你又不能说不trace或者减慢太多trace的频率,否则hot pages不一定能够及时在local DRAM里面。
这个问题很显然,我想应该是有人对这个做过优化的,文章读得还不够多,后面再补充。本文是提了一嘴利用局部性原理去优化基于page table的热度方法。但是再虚拟化环境中,内存的访问通常不具备局部性。这个可以参考我在杂货铺页面的Case1。
对于(2)的问题,这也是非常直观和显然的问题。基于局部性的假设而进行整个页面的迁移,看起来很有道理。但也非常遗憾,这个假设一听就不靠谱,尤其是再开大页的情况下。
像在Johnny Cache(OSDI'23)就有提到空间局部性比较稀缺的访问可能会遇到性能不佳的问题。
也很直观,一个页面只有一部分的数据比较热。尤其是虚拟化场景开大页。doge)你也不得不开Huge Page,不然Page Table的深度过深和TLB miss高频发生都是不太能接受的事情。
文章中简单地提到了它们的实验,2MB和4KB的两种页面大小配置,2MB会降低25%的吞吐量。这25%依然是FASTER系统(内存访问简单可预测)跑YCSB。只能是个例子,其它workload会降低多少就不好说了。
Intel Flat Memory Mode
说是在内存控制器层面实现数据放置,从而无需host CPU参与,避免上面提到的软件管理的缺陷,使得数据能以cacheline粒度被访问。
Local DRAM : CXL-Memory = 1 : 1,那也就是直接映射(?后面说Physical Mem & Local Mem是按2:1比例直接映射),说是能够减少slowdown。CXL比例大了,slowdown问题会更严重。
Pond: CXL-based memory pooling systems for cloud platforms (ASPLOS'23)
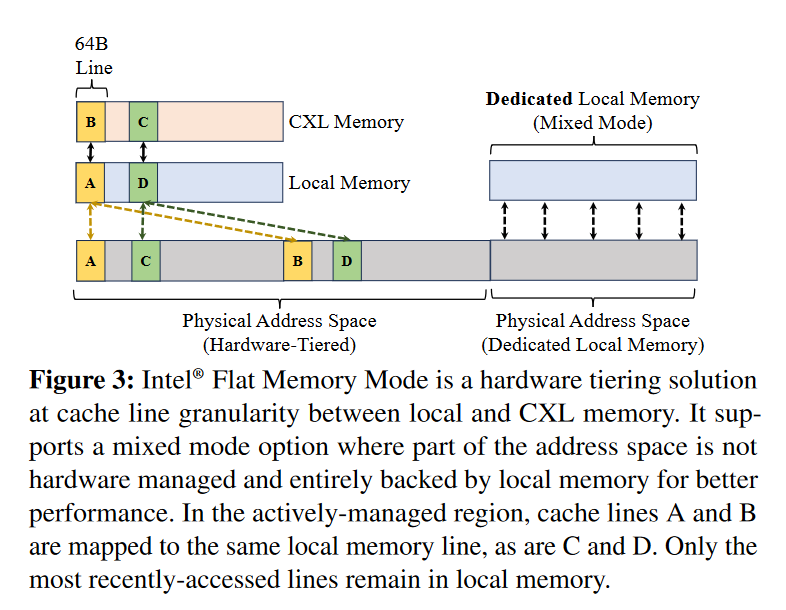
Mixed Mode 可以直接参见相关概念的Dedicated Local Memory
参考知乎【长期自闭】大佬的见解:
Local DRAM相当于CXL-Memory的Direct-Mapped Exclusive Cache,然后两个physical cacheline就会对应到1个local dram,和1个cxl-memory。
也即是图中的AB两个cacheline的放置。
读写流程
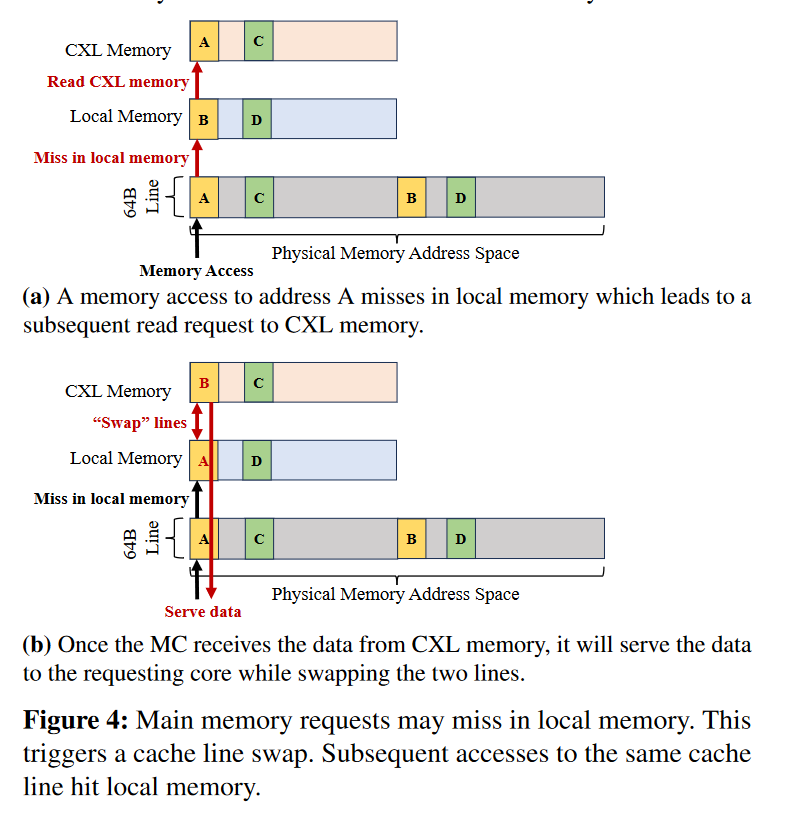
读写在上述这种情况下就很简单,按照Exclusive Cache的理解 + Directed-Mapped的方式,Physical Memory的cacheline 不是在Local Memory 对应的位置就是在和这个位置Direct-Mapped CXL-Memory的对应位置上。因此也只需要1bit来区分cacheline到底位于哪里。
当Local Memory Miss的时候,先去CXL-Memory直接取出数据给内存控制器。然后swap Local-DRAM和CXL Memory,与此同时,内存控制器也会将数据发送给CPU。
一些基本的实验
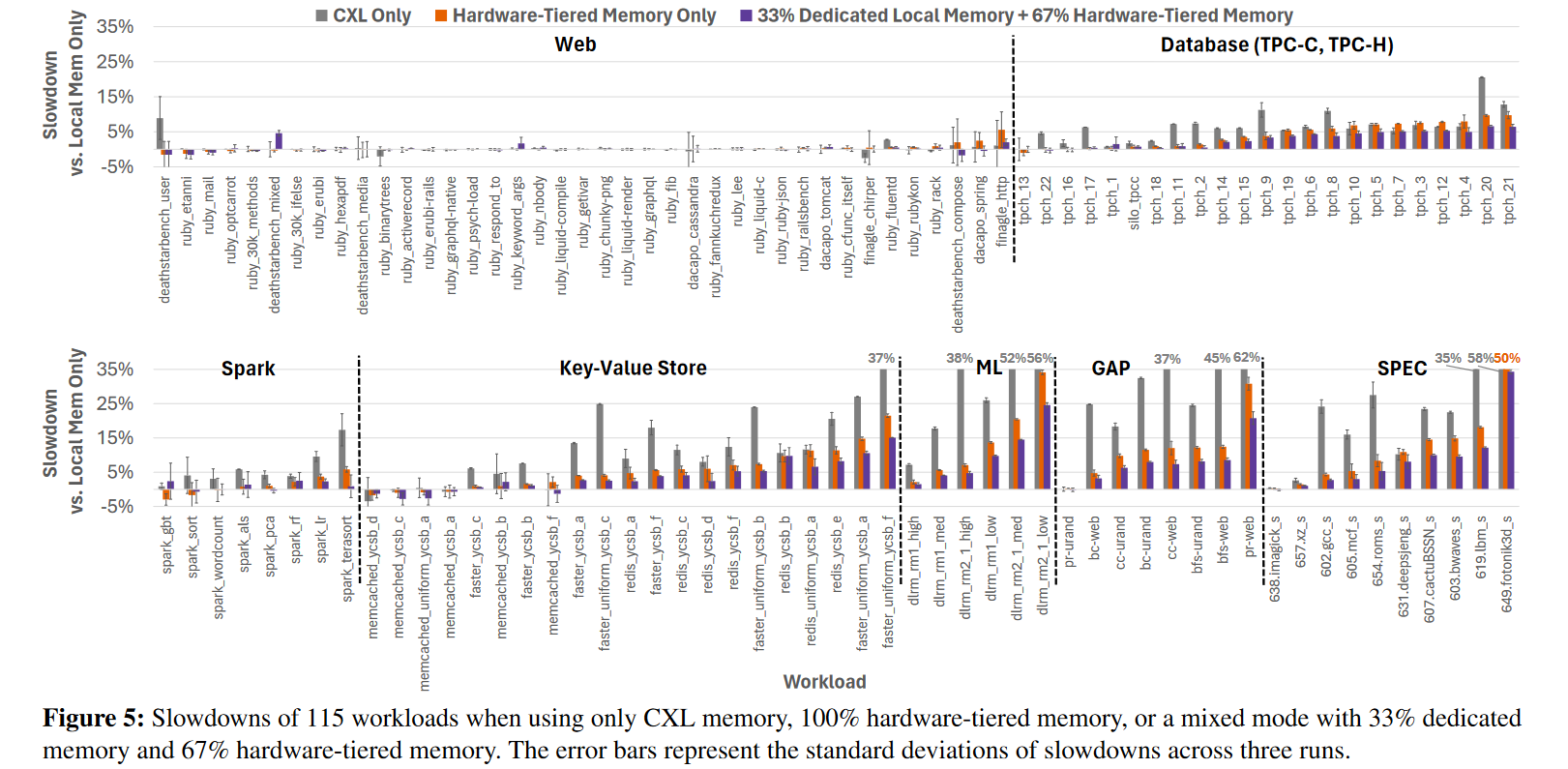
不同类型的workload对Memory的敏感程度不同(e.g. web的slowdown就不要太明显)
1:1 CXL+Local 的配置,相比于只有CXL的能够对大部分性能下降有一定缓解(超过73%的应用性能下降 < 5%),但有的可能会更糟糕
Mixed Mode (视作NUMA的Local Memory(随机分配??)) 则有更大比例(82%)的应用性能下降< 5%,(95% < 10%)
但依然有问题
Mixed Mode 在某些workload下依然会遇到不容忽视的slowdown
从而需要在软件层面对Mixed Mode优化
Interference
如上上图所示:
A、B两个cacheline会竞争同一个local DRAM的位置,只有最近被访问的cacheline会驻留在local DRAM。
因此如果存在竞争的页面(也就是存在cacheline竞争local DRAM)被分配到不同的VM,就会导致VM间的性能干扰。
对此,文中做了一些实验。实验设置是一个正常的VM以及一个Noisy Neighbor VM。
Normal VM 跑的是workload set里的workload。Noisy Neighbor跑的是6线程Intel Memory Latency Checker,本质上就是一个扫内存的循环。MLC是个Memory Intensive的Noisy Neighbor,就有利于更好地评估VM干扰。
实验中依然提到了两个术语,有了之前的描述,这两个术语就不需要过多解释了。
Isolated
把竞争页都放到一个VM
Conflicting
把竞争页放到不同的VM
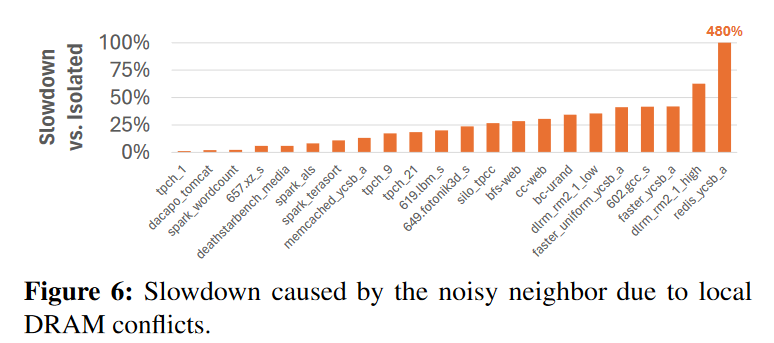
Figure 6 就展示了Conflicting的Slowdown问题,73%的workload slowdown超过10%。从而揭示了如果没有软件干预竞争隔离,同一个Host上运行的VM会对其它存在竞争的VM造成显著的干扰。
但VM之间的干扰不仅仅是竞争Local DRAM,像LLC和功耗也会存在竞争。因此文章继续做了实验来对比LLC竞争和Local DRAM竞争。

对于LLC的竞争,也是分成了两类
一类是共享LLC
另一类是平分LLC,Intel’s Cache Allocation Technology支持这个操作
Figure 7 就展示了LLC+Local DRAM竞争的排列组合的影响
绿色:只有LLC竞争 红色:都竞争 蓝色:只有Local Memory竞争 slowdown则对比都不竞争的情况
可以看出来只有Local Memory竞争的Slowdown 影响远远大于只有LLC竞争,而LLC竞争也放大了Local DRAM竞争。
Design
在之前文章中提过而笔记中未出现的design goals一共是4个
不会修改guest
低host 资源开销
避免local dram竞争
减少slowdown
对于(1)(2)两个goals,就像之前提到的把细粒度数据放置丢到内存控制器
对于(3),则借鉴了CPU Cache管理中的page coloring机制
对于(4),则是基于即使没有dedicated local memory很多负载的slowdown也比较低的key insight,试图将dedicated local memory的page移动到outlier(slowdown > 5%)的VMs上。
Page Coloring
简单来说就一句话,存在竞争的就染成同样的颜色丢到同样的VM,以隔离local dram的竞争。
识别outlier
MPKI Local DRAM Missed per Thousand Instructions 就很直观是一个好的指标。Local DRAM Miss就会带来Latency,就会slow。但是Local DRAM Miss 是System-wide属性的。现有的对一些MPKI的记录是CPU来干的活,为了量化VM的slowdown,需要测量per-VM Miss rate。而VM是pin在一组互斥的CPU cores上的,这就需要跨多个核聚合miss rates再来计算VM-Level Miss Rate。
文章说是因为cacheline升降级的实现在内存控制器上,所以track per-core misses比较困难。从而跨多个核聚合miss rates再来计算VM-Level Miss Rate也比较困难.
最后就选了L3 Miss Latency of demands loads来近似,这和上面说的一样,L3 Miss Latency of demands loads上去了就很有可能是Local DRAM Miss了。文章指出说这个近似有非常强的线性相关性,r平方0.87。
Intel® Flat Memory Mode 在带宽没跑满的时候展现出比较稳定的hit/miss latency。
但仅仅使用MPKI也不足以完全识别outlier,不同的workload也会展现出不同的latency-sensitive。于是本文就采用了机器学习的方法,采用了online random forest binary classifier。
这个机器学习方法的好处在于对于low-level metrics,是不需要GPU协同学习的。这篇文章采用的features包含四个
L3 miss latency of demand loads
L2 miss latency of demand loads
data TLB load miss latency
L2 MPKI of demand loads
相比于纯MPKI,准确率上升了25%-37%
Dynamic Page Allocator
参考知乎【长期自闭】大佬,这段就没仔细看了
每隔10s获取一次metrics,然后根据模型找到outliers,并按照local memory miss count进行排序,之后根据这个顺序将outlier的hardware-tierd memory pages和非outlier的dedicated memory pages进行调换
调换的流程是先拷贝到一个临时的page,然后再拷贝过去
为了避免性能抖动,每个VM允许调换的页在10%之内
作者没有讲针对一个VM要怎么选被调换的页
一个VM刚启动的时候随意分配(随机分配dedicated memory和hardware-tied memory),然后加入到Memstrata后会进行一次强制的migration,将它的dedicated page比例调整到和系统一样
比如系统有33%的dedicated memory和67%的hardware-tiered,那么需要将它的dedicated memory也调整到33%(通过和别的VM进行swap pages)
每个VM内部就是随机分配(我理解这应该就是根据guest OS的内存分配逻辑来分配)
VM内部采用随机分配反而比基于热度的方案更好,主要原因是hotness-based 方案产生的开销往往大于其产生的收益