TDRAM (HPCA'25)
【Title】Efficient Caching with A Tag-enhanced DRAM
Comments
第一作者是UCD dArchR研究小组的Maryam Babaie (mBabaie)。dArchR Research Group是目前gem5模拟器社区的主要维护者,团队成员在gem5社区非常活跃。ISCA的Workshop经常出现他们的身影。第一作者Maryam Babaie主要负责gem5的(异构)内存相关的模块。其中,在文章发表之前,其就已经开源了DRAM Cache的gem5 Model实现的代码。题外话,当时给第一作者发过邮件,居然周末就收到了回复邮件,原来是在赶论文(看他们组的产出不算太顶尖,我还一直以为是很宽松的环境)。
整篇工作很solid且insightful,但是唯一的问题是HBM本身工艺就已经够复杂且成本够高了,再基于HBM3加一些缓存、总线,再增加8%+的芯片面积和一定的引脚数真的很具有落地的价值吗?
这篇文章的实验在模拟器层面只能用Full-System模拟器,在体系结构模拟器中基本只剩下gem5可以模拟。Zsim,SystemC无法模拟操作系统行为,QEMU不太能作为体系结构的模拟器。如果未来的文章需要与这篇文章对比,就需要对gem5模拟器有非常深刻的理解,需要具备改(扩展)gem5源代码的能力。
Abstract
Abstract这边写法还蛮不异构内存的,以SRAM-based Cache难扩展起手。通算场景,常见的优化手段就是在不同处理速度的介质中加新的一层,充当cache。
由于基于 SRAM 的缓存正面临扩展瓶颈,制造商正在将基于 DRAM 的缓存集成到系统设计中,以继续增加缓存容量。尽管 DRAM 缓存可以提升内存系统的性能,但现有的 DRAM 缓存设计仍然存在较高的未命中惩罚、不必要的数据移动以及未命中请求与需求请求之间的干扰等问题。在本文中,我们提出了一种专为缓存优化的全新 DRAM 微架构——TDRAM。TDRAM 通过在现有 DRAM(如 HBM3)的基础上增加小型、低延迟的 mats 来存储标记(tag)和元数据,使其与数据 mats 置于同一芯片上。这些 mats 使得标记和数据能够同步访问,并在 DRAM 内部进行标记比较,同时根据比较结果执行条件数据响应(减少不必要的数据传输),类似于 SRAM 缓存的工作机制。此外,TDRAM 通过机会性提前标记探测进一步优化命中和未命中延迟。与此同时,TDRAM 引入了一种刷新缓冲区(flush buffer),用于在写入未命中时存储冲突的脏数据,从而消除写请求时的数据总线切换延迟。我们在全系统仿真环境下使用一组具有大内存占用的 HPC 工作负载对 TDRAM 进行了评估。结果表明,与当前最先进的商用和研究设计相比,TDRAM 平均能提供 2.65 倍更快的标记检查、1.23 倍的性能加速,并降低 21% 的能耗。
在 DRAM 内部进行标记比较 ??
Introduction
开头第一句就是在讲异构内存系统,然后讲的重点是利用HBM当DRAM Cache是为了处理SRAM的扩展限制。感觉就是说不上来哪里怪。
接下来就是讨论了未做优化的DRAM Cache存在的问题。
降低大内存占用应用程序的性能
降低高未命中率应用程序的性能
也是cache结构的固有问题
再接下来就是讲的是现有的DRAM Cache的优化机制存在的缺陷。
Intel Cascade Lake ,tag与data不分离,一旦未命中,额外增加的tag和元数据本质也是读取请求会与其它请求争用。
写请求(无论命中与否),都会读tag,metadata和data,加剧了资源争用。而且在数据总线上引入了昂贵的切换延迟(turnaround bubbles)。
切换延迟(Turnaround Bubbles) 是指在数据总线上,由于总线方向的切换(从读模式切换到写模式,或从写模式切换到读模式)而引入的空闲周期(bubble cycles),这些周期无法用于传输有效数据,从而降低总线利用率并增加访问延迟。
然后文章就没讨论别的文章了,这好像也蛮怪的??
现在就直接进入正题:文章提出了TDRAM,通过增加一组小型、低延迟的 mats(存储单元)来存储标记(tags)和元数据,并与数据 mats 一同集成在同一芯片上。这些标签 mats 通过减少字线(wordline)和位线(bitline)的长度,相较于数据 mats 提供了更快的访问速度。
新增的片上存储单元(on-die storage)足够容纳 所有 DRAM 缓存行的标记和元数据,因此 标签存储容量能够随 DRAM 数据容量的增加而扩展。通过将标签存储在独立的高速 mats 中,TDRAM 使得标签检查能够在芯片内(on-die)快速完成,从而:
降低请求未命中(demand misses)时的访问延迟
缓解 DRAM 读队列(read queue)的资源争用
减少无效的数据传输(进而降低能耗)
TDRAM 在 HBM3 的接口基础上进行了三方面的扩展:
增加了单向命中-未命中(Hit-Miss, HM)总线,用于将标签检查结果和元数据传输到控制器。
引入了两条新指令:ActRd 和 ActWr,它们可以同步访问标签 mats 和数据 mats。这些指令会先检查数据块的标签,仅在需要时才向控制器发送数据,从而减少不必要的数据传输。
增加了一个刷新缓冲区(Flush Buffer),用于存储写未命中(write miss)时产生的冲突脏数据。这一设计能够消除数据总线上昂贵的切换延迟(turnaround delays),并避免立即将整个缓存行数据传输到控制器。
注意:硬件新增电路问题一定需要讨论面积占用,(还可能需要讨论引脚数、功耗、价格)。本文与 HBM3 相比,该新架构的设计 额外占用了 8.24% 的芯片面积,并增加了 192 个引脚(增长 10%)。
TDRAM 通过引入提前标签探测(early tag probing)机制进一步提升性能。该机制利用空闲的指令槽(command slots)和 HM 总线槽(HM bus slots),主动执行标签检查(无需访问数据)。
标签探测能够提前返回内存请求的命中-未命中(hit-miss)结果及状态信息,使得某些操作(例如 读请求未命中时的主存访问)可以更早开始。此外,该机制还能减少请求在队列中的占用时间,提前移除未命中请求,从而减少阻塞,使其他请求能够更快执行。
TDRAM 与许多旨在提升 DRAM 缓存性能的先前研究是正交的(orthogonal),这些研究包括添加预测器(predictors)、预取器(prefetchers)、标签缓存(tag caches)、修改一致性协议(coherence protocols)、旁路策略(bypass policies)以及其他特定应用的优化机制等 [22], [23], [28], [35], [69]。
TDRAM 的设计允许这些技术进一步结合,以进一步提升缓存性能。总体而言,TDRAM 实现了一个完全可扩展(scalable)的基于 HBM 的缓存架构,其缓存范式(caching paradigm)与处理器的 SRAM 缓存类似,具备更高的一致性和协同优化能力。
在 gem5 模拟器 中对 TDRAM 进行了深入建模,用于全系统的周期级(cycle-level)时序分析。
在科学计算(scientific computing)和图分析(graph analytics)等具有大内存占用(large memory footprint)的应用上进行了评估,结果表明:
TDRAM 的标签检查速度提升了 2.65 倍,
整体性能提升 1.23 倍,
能耗至少降低 21%,
相较于商用和学术研究设计(包括 Intel Cascade Lake、Alloy、BEAR [28] 和 NDC [60]),TDRAM 展现出了显著的优势。
在本文中,我们的主要贡献如下:
我们提出了 TDRAM,一种面向缓存的新型 DRAM,采用内置标签管理(in-DRAM tag management),用于可扩展的 HBM3 缓存架构。
我们扩展了 HBM3 的接口,添加了单向 Hit-Miss 总线,用于将标签检查结果和元数据从 DRAM 传输至控制器,从而将标签传输与数据传输解耦。
我们优化了读写操作,使其能够以同步(lockstep)方式访问独立的标签存储单元(tag bank)和数据存储单元(data bank)。该协议仅在必要时基于标签比对结果选择性地向控制器传输数据,从而减少带宽浪费。
我们添加了冲刷缓冲区(flush buffer),用于存储因写入未命中(write miss)而产生的冲突脏数据,避免昂贵的数据总线切换延迟(turnaround delay),同时消除写请求时立即传输整个缓存行数据至控制器的需求。TDRAM 在数据总线空闲时机主动将这些数据传输至控制器。
我们提出了提前标签探测(opportunistic early tag probing),利用未使用的 Hit-Miss 总线和命令总线(command bus)槽,优化未命中(miss)时的访问延迟。
在评估中,我们证明了现有 DRAM 缓存设计会导致性能下降,而 TDRAM 可提供 1.11× 的性能提升。此外,TDRAM 可减少 12%–21% 的能耗(几何平均值)。
Background & Motivation
许多研究探讨了硬件管理的 DRAM 缓存中标签和元数据(统称为标签)的管理,表 I 比较了其中一些与 TDRAM 的区别。此外,市场上也有 DRAM 缓存产品,例如 Intel 的 Xeon 系列,提供数 GB 的 DRAM 缓存。在存储容量方面,64 GiB 基于块的 DRAM 缓存需要 3 GiB 存储来存储每 64B 块的 3B 标签。这远超目前 AMD(EPYC 9654P 中有 384 MiB 缓存)和 Intel(Xeon Platinum 8468H 中有 105 MiB 缓存)高端 CPU 的缓存大小。虽然 SRAM 缓存已面临扩展瓶颈,将标签存储在 SRAM 中(例如在处理器芯片上)会增加面积开销和成本。此外,将标签放置在处理器芯片上(如 eTag)会大幅限制 DRAM 缓存容量的可扩展性,因为它受限于处理器芯片提供的标签容量。因此,当 SRAM 缓存面临扩展限制时,支持高可扩展性的 DRAM 缓存解决方案可能更为有效。
先前的研究建议将标签存储在与数据所在的同一缓存行中 。例如,在 AlloyCache中,必须访问 72B 数据(加上 8B 被忽略),而不是 64B 块,这会导致 DRAM 行内列布局的错位,并留下未使用的位,导致可扩展性开销。在 Intel 的 Xeon 系列(如 Cascade Lake)中,标签存储在商品 DRAM 设备的 ECC 空闲位中 。然而,ECC 位并不是为此目的设计的。这些设计依赖于 DRAM 读取来访问标签,这可能会造成标签和数据访问的串行化(例如,在写命中时),从而增加带宽浪费。
第一个问题满显然的,第二个确实不仔细研究还真不知道,又学到了(doge
一些先前的研究提出将标签存储在 DRAM 芯片上的独立存储区域。R-Cache 使用阻变 RAM 存储标签 。由于标签访问是关键路径的一部分(即 DRAM 缓存中的数据访问依赖于标签比较结果),因此必须尽量减少标签读取和更新的延迟。阻变 RAM 无法提供所需的速度。此外,标签和元数据经常更新,这可能会导致阻变 RAM 快速磨损。其他研究建议使用基于 DRAM 的标签存储。这些研究优化了标签管理和数据布局,以适应需要多次标签比较并且能够并行激活标签和数据区域的 DRAM 行中的集合关联缓存。
然而,它们必须延迟列操作的开始,直到标签比较逻辑找到对应的列,这实际上将数据访问与标签访问捆绑在一起。此外,它们缺乏有效的方式来处理写命中的脏缓存行,这要求在写操作前读取数据以确保正确性。这些解决方案依赖于投机机制(例如,预测器和基于应用程序特定设计的 DRAM 绕过 [35]),或需要深度修改缓存一致性协议。例如,BEAR 缓存需要修改 DRAM 以支持 80B 访问(如 Alloy 缓存),并要求:(i) DRAM 向 LLC 发送逐出消息,(ii) LLC 向 DRAM 发送 DRAM 缓存存在指示器 [28],[50]。这种方法将片上缓存、内存控制器和 DRAM 的设计捆绑在一起,增加了工业应用的复杂性。
不愧是搞gem5模拟器的,也确实是很底层的体系结构,这工作都有Onur组的味道了。
Opportunities to Improve DRAM Cache Designs
标签检查延迟始终是处理内存请求的关键路径,影响命中/未命中的延迟。先前的设计将标签存储在 DRAM 缓存行中 [28],[41],[58] 或 DRAM 的 ECC 位中(例如,Intel 的 Cascade Lake)需要进行 DRAM 读取,以同时获取标签和数据,旨在并行化访问并提高命中延迟。我们的实验揭示了它们的低效性。
使用 gem5 仿真器 [51],我们模拟了 Intel Xeon Max 系列的 1/8 部分 [24],将其四舍五入为 64 核心和 64 GiB 的 HBM(作为 DRAM 缓存)。我们实现了 BEAR、Alloy 和 Intel Cascade Lake DRAM 缓存,采用直接映射的插入缺失缓存,将标签存储在 DRAM 中。我们执行了 28 个 HPC 多线程工作负载,它们的内存占用范围为 0.1–80 GiB,DRAM 缓存大小为 8 GiB。在完整系统仿真中,我们采用了 LoopPoint 技术 [61]。值得注意的是,我们的方法与之前的研究不同,揭示了在先前研究中未观察到的病态路径。有关我们方法的更多细节,请参见 §IV。
DRAM 缓存的增加命中延迟:在使用标准 DRAM 设备且标签存储在设备中的 DRAM 缓存中,LLC 读取缺失的缓存命中延迟等同于 DRAM 读取延迟。对于 LLC 写回(即从 LLC 驱逐脏数据),命中延迟包括
DRAM 读取延迟(用于检索标签)
DRAM 写入(将传入的数据写入缓存)
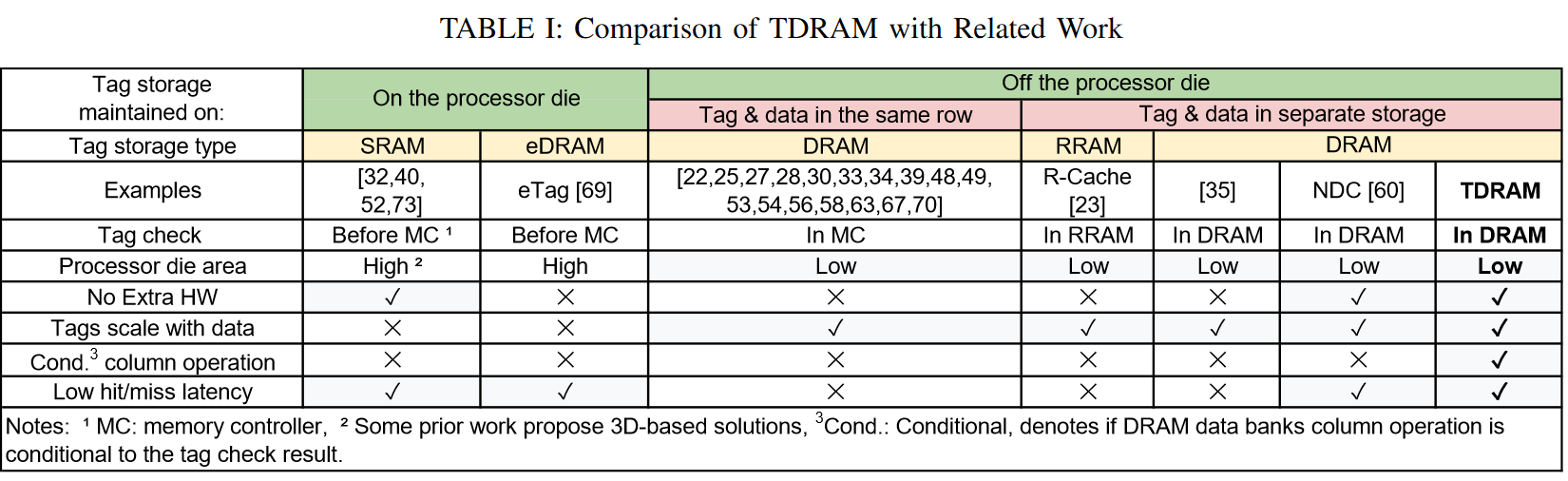
之前尝试将标签和数据访问并行化或解耦的工作面临着 LLC 写回的挑战,包括那些命中 DRAM 缓存的写回 ,因为控制器必须完成 DRAM 读取以进行标签比较,才能开始将传入的数据写入缓存,以避免覆盖任何冲突的脏数据。商品化的 DRAM 需要读取整个缓存行数据以获取标签,而不考虑传入写入数据的大小,这使得 DRAM 读取始终处于写请求的关键路径上,导致访问放大(带宽膨胀)。先前的研究报告称,DRAM 缓存的访问放大最多可达到 5 次访问。图 1 展示了我们实验中 DRAM 缓存的缺失率百分比及其分解。如深蓝色所示,许多工作负载显示出显著的 LLC 写回命中 DRAM 缓存,影响了其命中延迟。BEAR 提出改变 LLC 结构、片上缓存一致性接口和 DRAM 控制器,以交换关于 LLC 写回是否存在于 DRAM 缓存以及 DRAM 缓存驱逐的信息,从而避免对命中 DRAM 缓存的 LLC 写回进行标签检查。然而,这些是在系统多个独立部分进行的深度和复杂的修改,且不容易被行业采纳。
未来的优化工作确实得仔细考虑这个问题,才能有好的工作
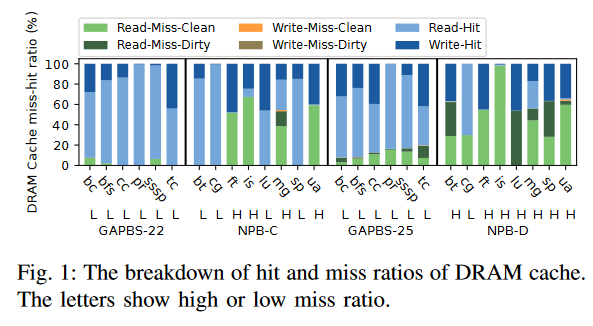
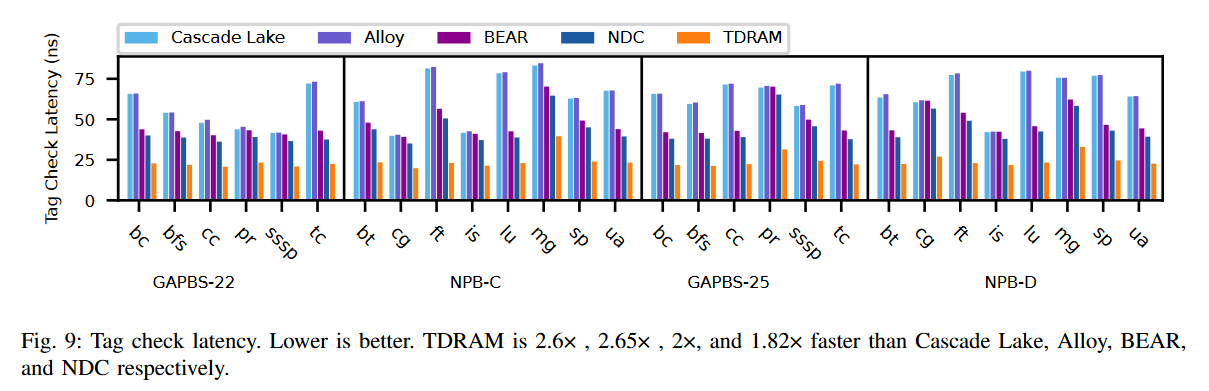
DRAM 缓存的增加未命中延迟:在当前的 DRAM 缓存中,所有的读写请求(即 LLC 的读未命中和写回)都必须经过 DRAM 读取以获取标签。
控制器在同一个读取缓冲区中处理这些 DRAM 读取,包括 LLC 写回。这种安排加剧了缓冲区中的争用,增加了所有请求的排队延迟。
图 2 显示了现有 DRAM 缓存中 DRAM 读取的平均排队延迟,并与仅配备主存(没有 DRAM 缓存)的系统进行比较。如图所示,与没有 DRAM 缓存的系统相比,DRAM 缓存系统中的条形图较高。特别是在 Cascade Lake 和 Alloy 中,因为每个读写请求都必须通过读取 DRAM 缓存中的标签开始(即使有预测器),这增加了读取缓冲区的争用,并且在标签读取时会发生bank冲突。在 BEAR 缓存中,命中 DRAM 缓存的 LLC 写回绕过了标签检查步骤,从而减少了这些请求的排队延迟。然而,读取未命中仍然需要通过标签检查过程。这种延迟直接影响所有在 DRAM 缓存中未命中的读取请求的标签检查延迟,导致从主存中获取缺失行的延迟。对于 LLC 读取未命中来说,这种延迟至关重要,因为 CPU 观察到它们的延迟,这直接影响到整体系统的吞吐量。如图 1 所示,DRAM 缓存中的读取未命中数量(深绿色/浅绿色)非常显著。因此,优化 DRAM 缓存的读取未命中延迟对于读取请求来说非常重要。
带宽膨胀和能量消耗增加:控制器在标签检查过程中获取的数据仅对命中缓存的读取请求或未命中脏缓存行的请求有益。对于读取/写入未命中干净行(在 Cascade Lake、Alloy、BEAR 中)和写命中(在 Cascade Lake 和 Alloy 中)的情况,控制器在标签比较后立即丢弃读取数据,毫无用途。在这种情况下,现有的 DRAM 缓存设计通过以下方式引入数据移动开销:
保持 DRAM 的命令总线和存储体忙碌
占用数据总线进行不必要的数据传输。
这些 DRAM 与控制器之间的额外通信导致带宽膨胀,浪费能源。当未命中率上升时,这种低效性会加剧。图 3 量化了标签检查过程中浪费的数据移动量。在许多应用程序中(例如 ft、is、mg、ua),浪费的数据移动非常显著。需要注意的是,Alloy 和 BEAR 缓存对每个 64B 的内存请求具有 80B(64B 数据,8B 标签和 8B 被忽略)的访问粒度,这增加了无用的数据移动。
此外,当读取的数据是脏行时,它不必要地成为服务请求的关键路径的一部分。一个深思熟虑的设计可以将这些访问移出关键路径,同时确保正确性。图 1 说明了在标签访问中未使用读取数据的内存请求(即写命中、读未命中干净行、写未命中干净行)是常见的。值得注意的是,写请求未命中脏行的情况在 DRAM 缓存中非常罕见,这表明有机会谨慎地在写请求的标签检查中消除数据读取。
Goals
通过优化标签检查机制和写命中,减少命中延迟,并在 DRAM 内部完全执行标签检查;
通过减少标签检查和排队延迟,减少未命中的延迟,特别是读取操作;
通过减少写命中、读未命中干净行和写未命中干净行时浪费的数据移动,节省能量;
支持写未命中脏行(即我们不能简单地覆盖写操作),以确保正确性,而非性能,因为这种情况比较罕见。
Design
在本节中,我们将描述 TDRAM 的详细信息,这是一种专为缓存设计的新型 DRAM。TDRAM 的设计与其他定制 DRAM(如 RLDRAM [9])相似。由于 SRAM 缩放的放缓,业内已经开始将 DRAM 集成到缓存中 [17],[24],[64],并宣布未来将推出专门用于缓存的 DRAM 设备 [15]。TDRAM 是这一领域中的一种新型微架构。
HBM3 as the Basis of TDRAM
我们选择 HBM3 作为 TDRAM 的基础,因为最新的产品(例如,英特尔的 Sapphire Rapids)已经使用 HBM 作为 DDR5 后备存储的缓存,而 HBM3 是该技术的最新版本。然而,我们为 TDRAM 提出的方案完全适用于其他技术,因为我们将数据存储与标签分离,并保持其底层技术的完整性。在撰写本文时,我们将 TDRAM 设想为当前 DRAM 设计的一个可选扩展,并尽量保持协议与 DDR 相似。从零开始重新设计 DRAM 可以实现全面优化,但也带来了一些挑战:
现有的内存标准具有广泛的生态系统支持,包括供应链、软件栈和架构兼容性。从头开始需要重新创建这个生态系统,增加了复杂性和成本。
增量式的方法可以控制风险并进行有针对性的增强,是一种成本较低、风险较小的创新路径。
HBM3 DRAM 通过将多个 DRAM 芯片堆叠成一个单一封装,支持最多 64 GiB 的容量,采用 12 至 16 层堆叠 。当运行于 8 Gbps 时,峰值带宽为 1TB/s,支持 16 个独立通道,每个通道使用 64 位数据 (DQ),以及 10 位行命令 (R) 和 8 位列命令 (C) 总线。每个 DQ 通道被分割成两个 32 位伪通道 (PC),它们共享相同的行和列命令总线,每个 PC 提供 32B 的访问粒度 [7], [12]–[14]。连接 DRAM 和主机之间高引脚数接口的线缆(1024 个 DQ、288 个命令/地址 (CA) 总线以及超过 650 个额外通道和全局功能引脚)采用 TSMC 的 InFO 或硅基实现(例如硅互连器),以支持此技术所需的高引脚和布线密度。
关于协议,命令解码器通过 CA 总线接收来自内存控制器的命令和地址。当从 DRAM 读取数据时,激活命令提供行地址,将一个bank中的所有位移到感应放大器(或感应放大器)。单独的读取命令提供列地址,从感应放大器中选择一部分位,并通过 DQ 总线返回。写命令的工作原理类似,提供要写入的数据。
TDRAM’s Interface
TDRAM 利用 HBM3 接口,并引入了如图 4A 所示的三个变化:
将 R 总线和 C 总线合并为单一的 CA 总线(即类似于 DDR DRAM);*
将每个 32 个伪通道(PC)转换为一个独立的通道,具有自己的 8 位 CA 总线和 32 位 DQ 总线;*
在每个通道中添加了一个 4 位单向的命中-未命中(HM)总线。将伪通道(PC)转换为独立通道简化了内存控制器设计,因为每个伪通道已经有自己的内存控制器 [11],并且可以去除 HBM3 中共享的 R 总线和 C 总线的命令/地址仲裁。CA 总线与 DQ 总线运行在相同的速度下。数据传输通过 ECC 和冗余进行保护,正如 HBM3 中所做的那样。
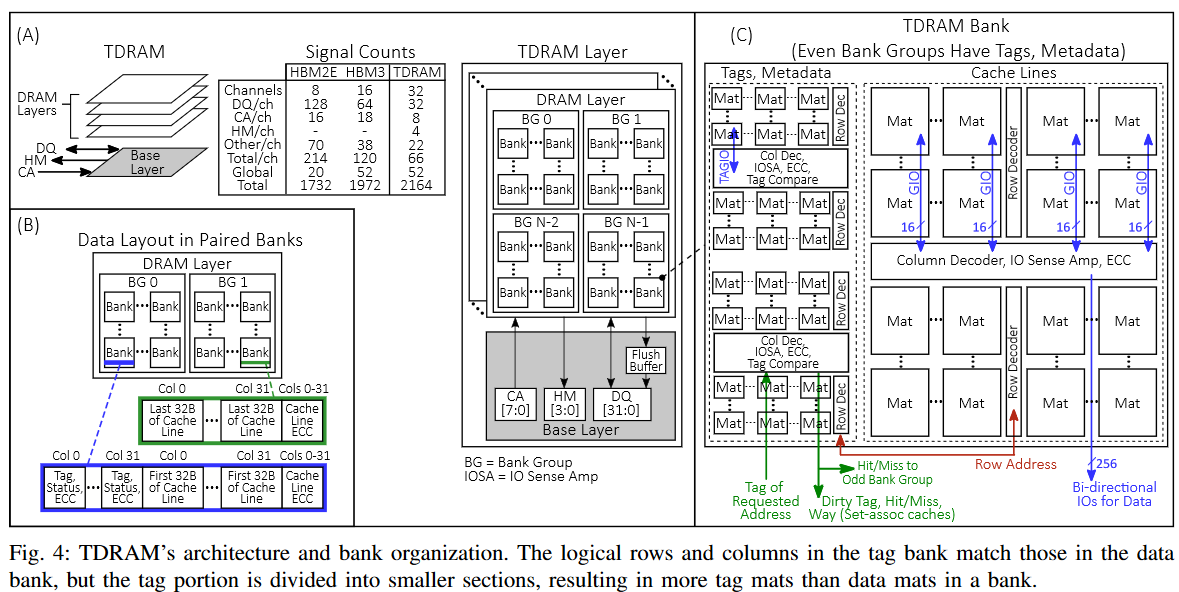
TDRAM 使用 HM 总线将标签比较结果(命中/未命中)、状态信息(有效、脏数据等)和脏数据的标签(用于主内存回写)传输给主机。HM 总线以全速数据率运行。数据包的长度远大于单次事务的 HM 总线占用时间。因此,标签和元数据可以通过 HM 总线以多个节拍(例如,对于 3B 元数据为 6 个节拍)传输,而不会出现带宽问题。每个通道有 22 个额外信号(时钟、突发、ECC 等)。DRAM 有 52 个额外的全局信号(重置、IEEE1500 等),总共有 2164 个信号,比 HBM3 增加了 9.7%。图 4A 中的信号数量表比较了 TDRAM 的信号开销与 HBM3 的信号开销。HBM3 封装在地址和数据信号区域有 320 个未使用的凸点位 [7],足够容纳 TDRAM 中的额外 192 个信号(2b CA + 4b HM = 每个 32 位通道 6 个信号),允许其使用类似的封装。
TDRAM’s Internal Architecture
数据存储和访问粒度
TDRAM 使用 HBM3 的标准bank微架构进行数据存储。Intel 和 AMD 的 CPU 操作 64B 的缓存行,但 HBM 设计为提供 32B 的粒度,TDRAM 将不同bank group中的bank配对,并交错访问它们,以较低的延迟实现 64B 的粒度。图 4B 显示了这些配对bank的布局。控制器将配对的bank视为一个逻辑银行,并相应地调度访问。为了简化配对银行的管理,控制器发出单个命令(例如,激活、读取等),并且基底芯片上的逻辑会复制该命令,按时间交错地发往bank对。跨bank组配对银行简化了控制器的管理,因为该设计消除了对同一bank group的连续访问。
片上标签存储
TDRAM 将标签、元数据及其 ECC 存储在与数据矩阵相同芯片上的独立矩阵中。TDRAM 使用一组小型低延迟矩阵来提供快速的标签访问。这些低延迟矩阵允许并行的标签和数据查找,命中/未命中在数据矩阵中的数据可用之前就已确定。标签矩阵位于每个bank的边缘(图 4C)。标签矩阵的延迟较低,因为:
标签存储的大小远小于数据存储的大小(每 64B 缓存行 3B 标签)
我们使用的标签矩阵比数据矩阵多,进一步减少了标签访问的大小和延迟。
尽管标签bank中的逻辑行列数与对应的数据bank相同,但标签部分被分成更小的部分,以优化延迟。因此,标签bank中比数据bank有更多的矩阵(图 4C),从而导致更低的延迟。由于它们的尺寸较小,这些矩阵的字线和比特线长度比数据矩阵更短,从而优化了延迟,正如先前的研究所示 [65]。
我们的设计将标签矩阵在每个方向上缩放 1/2,减少了字线延迟时间和bit line充电共享完成时间。我们基于先前的研究 [65] 选择这一比例作为起点。这个选择依赖于技术,并不是我们设计的核心。我们增加了更多的集中解码器和 I/O 接口,以进一步优化延迟。标签矩阵将与数据矩阵具有相同的刷新率,并与数据矩阵并行刷新。这不会增加性能开销;然而,它会增加能耗,我们在 §V-C 中对此进行了考虑。另一个选择是将标签阵列实现为 TDRAM 堆栈中的单独芯片。
然而,将标签存储在与缓存行数据相同芯片上的优势在于,标签存储随着数据存储的扩展而扩展。本文其余部分我们假设标签与数据存储在同一芯片上。
标签/元数据访问与标签比较
我们在 HBM3 命令集中添加了两个新的 DRAM 命令:激活读(ActRd)和激活写(ActWr)。当向某个bank发出 ActRd 或 ActWr 命令时,标签矩阵会与数据矩阵并行激活。为了避免将标签和元数据发送回控制器,TDRAM 在标签矩阵的 IOSA 区域实现了片上标签比较器,用于确定访问的命中/未命中状态。然后,HM 结果会被路由到芯片的外围,通过 HM 引脚输出。HM 结果还会发送到数据矩阵的列解码器,在那里用于控制列解码逻辑(如 SALP [43])。如果标签比较结果为命中或未命中脏缓存行(对于读请求),数据会通过 DQ 总线传输。如果标签比较结果为未命中干净缓存行,则列解码不会发生,DQ 总线上不会传输数据,从而节省能源。
为了提高可靠性,TDRAM 为标签和数据提供了独立的 ECC。标签的 ECC 会通过片上 DRAM 电路进行分析和修正(如基线 HBM3 [7])。标签和元数据的位数较少(3B),因此可以使用与数据不同的算法。例如,它可以使用基于符号的 Reed-Solomon 编码。对于 1PB 地址空间,直接映射的 TDRAM 具有 14 位标签 + 有效位 + 脏位 = 16 位,剩余 8 位 ECC 覆盖这 16 位。TDRAM 使用与 DRAM 写操作期间相同的标签写入机制。与现有的 HBM 一样,基片上有一个状态机,用于初始化 ECC、元数据等。TDRAM 扩展了基片上内置自测试(BIST)模块的逻辑,以便在启动时也将标签初始化为零。图 5、6 和 7 显示了 TDRAM 中读写操作的时序事务,并在 §III-D 中进行了讨论。
标签矩阵时序值
TDRAM 架构通过使用小型低延迟矩阵(如 §III-C2 中所讨论的)来最小化标签访问延迟。
鉴于 DRAM 时序的专有性(特别是对于像 HBM 这样的小批量设备),我们选择依赖于与我们设计紧密匹配的公开数据。为了进行评估,我们使用基于 RLDRAM 的标签矩阵时序参数。RLDRAM 规格值(例如,tRL=15ns 和 tRC=8ns)与我们的值(例如,tRCD TAG+tHM=15ns 和 tRC TAG=12ns)相匹配,或者更为乐观。此外,这些值和内部 TDRAM 时序还与之前的工作分析(如使用更小的矩阵的研究)进行了关联,以设置延迟的严格上限。事实上,我们预计在现代技术中,时序参数将会更快。然而,我们使用保守的数值进行分析;因此,我们的时序参数基于 RLDRAM 的公开数据表,而 RLDRAM 的矩阵大小也比常规 DRAM 小。表 III 显示了这些时序值的列表。具体来说,我们解释了 tRL core 和 tHM int 的值。tHM int = tCCD L+tHM detect(这是一个快速的等值比较)。如今,DRAM 已经完成地址比较,以快速确定每个 DRAM 接收到的行或列地址是否为修复行或列。
根据与 DRAM 设计师的讨论,我们将 tHM detect 设置为 0.5ns(一个 2GHz 时钟周期),用于快速的等值比较。tHM int 的使用取决于 tRCD,因为在 tRCD 达成之前,无法进行读取操作。在我们的设计中,tRCD = 12ns,这比 tRCD TAG+tHM int=10ns 要长,有效地隐藏了标签访问和命中/未命中检测的延迟。tHM int 也与之前的工作 [65] 进行了关联,该工作将 ACT 到数据的延迟分解为:47% 感应,26% 地址解码,20% MUX(传输+速率转换),7% I/O。列解码与感应(tRCD)并行完成,使用我们的 ActRd/ActWr 命令。
最后,I/O 延迟与内部时序无关。MUX 延迟的一部分,即将数据从 IOSA 移出的延迟,与内部时序相关,并在我们的设计中通过使用更小的矩阵进行了优化。基于 RLDRAM3,从读取命令到 DQ 总线上数据开始的完整延迟为 15ns,约为常规 DRAM 延迟的一半;因此,支持我们的 tHM int=2.5ns。另一方面,为确保脏数据不会在 SA 中被覆盖,tRL CORE(如图 6 所示,用于写操作)需要小于或等于 intRD-toWR 数据延迟+tBURST/2=9ns。我们使用 tRL CORE=tCCD L=2ns 进行评估。对于 tHM int 和 tRL CORE 参数,其他延迟(例如图 6 中的 tWL 和 tWR)主导了延迟,如图所示。
标签存储区域开销
一个 64 GiB 的直接映射缓存(direct-mapped cache)可以支持 1 PB 的地址空间,使用 14 位 的标签。我们假设每个 64B 的缓存行需要 3B 的标签和元数据。标签仅存储在偶数编号的存储体组(bank group)中,标签比较的结果通过内部总线传递到另一个(奇数编号的存储体组)。我们估算了标签存储、片上比较和控制逻辑对芯片面积的影响,并与基准的 HBM3 内存进行比较,具体如下。
HBM3 每 32B 数据存储额外的 6B 信息(2B 元数据和 4B 校验位),这些信息分布在 19 个存储单元(mat)中,如 Park 等人 [57] 所示。HBM3 的芯片照片显示,存储体(包括存储单元、位线感应放大器(BLSAs)和子字线驱动器(Sub-WL drivers))约占芯片面积的 66%。剩余的 34% 芯片面积包括共享资源,如硅通孔(TSVs)、输入输出感应放大器(IOSAs)、每个存储体组的纠错码(ECC)和列解码器。
我们为每个数据存储单元使用 4 个较小的标签存储单元,通过减少位线和字线的长度来降低行周期时间。Son 等人 [65] 表明,将长宽比改变 4 倍的开销为 19%;然而,基于与 DRAM 设计者的讨论,我们在每个维度上缩放 1/2 时,采用了更悲观的估计值 24.3%。此外,我们只需要在偶数存储体中放置标签存储单元,这进一步降低了开销。因此,偶数存储体需要额外 24.3% 的面积用于标签,而数据存储体占芯片面积的 66%。因此,对芯片面积的总体影响为 24.3% × 0.5(仅偶数存储体) × 0.66(存储体面积) = 8.02%。我们还增加了额外的面积用于布线(例如,将命中/未命中信号从偶数存储体路由到奇数存储体),最终对芯片面积的影响为 8.24%。
Protocol
TDRAM 的协议类似于传统 DRAM 的协议,但进行了修改,以最小化标签延迟和带宽膨胀。TDRAM 合并了 ActRd 和 ActWr 命令,这些命令同时在标签和数据bank激活一行并读取/写入一列,并具有自动预充电的关闭页策略。这些命令包括确定缓存命中/未命所需的行和列地址、bank group、bank和标签地址。TDRAM 内部的状态机负责处理激活操作和列操作到银行和 SA 的时序和顺序。读/写数据从这些命令中在 DQ 总线上以固定的偏移量出现,类似于现代 DRAM。
拥有一个单一命令来访问标签和数据bank可以减少命令放大并节省能量 [4],[8],[9]。此外,它简化了内存控制器,因为标签和数据bank具有相同的行列数。单一地址被解码用于标签和数据,允许它们的bank通过一个命令同步激活。TDRAM 的控制器可以采用任何调度策略,如先到先服务(FR-FCFS)。表 II 显示了缓存每次访问时执行的操作。
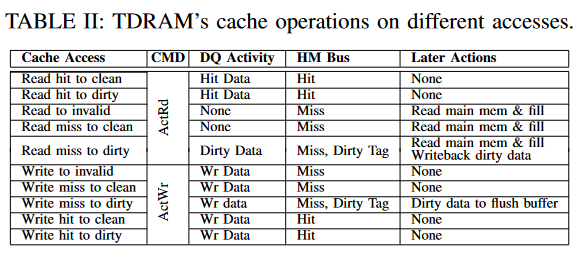
读取操作:低延迟标签矩阵允许在缓存行数据可用之前确定命中/未命中情况。图 5 显示了 TDRAM 读取操作中涉及的命令的时序交易。对于读取操作,HM 响应将优先于 DQ 总线传输,从而根据命中/未命中结果提供条件响应:
在读取命中时,缓存行数据将返回到控制器。
在读取未命中且为干净数据时,不会发出读取命令,也不会返回缓存行数据到控制器。未使用的 DQ 插槽可以用来将数据从刷新缓冲区(§III-D2)传输到控制器。
在读取未命中且为脏数据时,脏数据将与命中时返回数据的 DQ 总线时序一起返回到控制器。脏标签将在
HM 总线上返回,并带有脏未命中的指示。当控制器收到读取请求的未命中指示时,它可以启动后备存储读取,以便在脏数据(如果有的话)到达控制器之前获取所需的数据(用于缓存行填充和 LLC 响应)。提前标签探测进一步优化了这一过程(§III-E)。
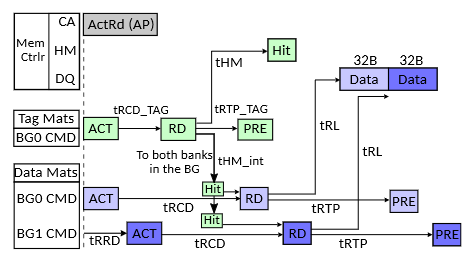
这就看不懂了,还是得补一点内存时序参数和电路的知识的,不然这种东西绝对写不出来
写操作:写操作必须避免在写未命中时用新数据覆盖脏缓存行——这种情况虽然罕见,但需要正确处理。所有现有的 DRAM 缓存都必须要么将缓存行数据读取(将其发送回控制器)和传入的写数据序列化[58],要么依赖于复杂的缓存一致性协议修改[28],[50]和特定应用的 DRAM 绕过技术[35]。TDRAM 通过添加一个刷新缓冲区来避免这些低效做法,从而为写操作提供一种通用方法。刷新缓冲区在所有银行之间共享,类似于控制器中的写缓冲区存储将要写入 DRAM 的数据。刷新缓冲区(以及支持缓存的附加逻辑)被放置在现有的基础层上,基础层已经包含了支持 HBM 协议等的逻辑。基础层没有面积限制,因此可以支持所需的缓冲区和逻辑。
TDRAM 发出一个 ActWr 命令,启动内部标签和数据访问。一旦标签比较结果到达数据bank,在命中和未命中干净的情况下,只会发出一个内部写命令。如果标签检查显示为未命中脏数据,则会发出一个内部读命令,接着是一个内部写命令。图 6 显示了这些命令的顺序。TDRAM 将脏数据放入刷新缓冲区,然后将新数据写入 DRAM。刷新缓冲区需要足够大,以确保控制器不需要在一系列缓存写操作期间仅仅为了清空一个满的刷新缓冲区而产生中断,这样做会需要在 DQ 总线上插入一次从写操作到读操作再到写操作的全程转向。由于写未命中脏数据预计是一个相对罕见的事件,因此刷新缓冲区的大小可以适度配置(例如 16 个条目,§V-E),从而几乎消除了强制清空刷新缓冲区的需求。内部会有一个小的读写turnaround,用于将脏数据从 DRAM bank移动到刷新缓冲区,但可以避免在 DQ 总线上进行更大的转向来将数据发送到控制器。来自控制器的缓存写序列不会因为写未命中脏数据而在 DQ 总线上经历任何延迟。 RDRAM 使用类似的方法,通过实现写缓冲区和写/退休机制来最小化由于 DRAM 核心中资源冲突而引起的turnaround。接下来,我们将解释 TDRAM 如何机会性地卸载刷新缓冲区。
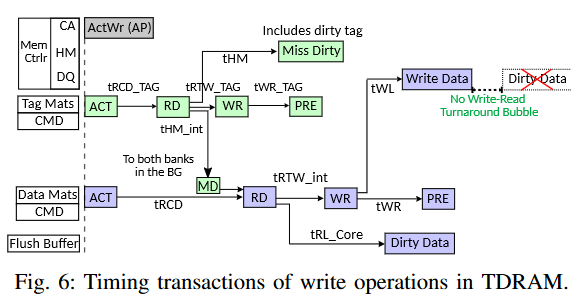
卸载刷新缓冲区
TDRAM 会根据以下情况投机地或按需将刷新缓冲区中的脏数据传输到控制器:
当 DQ 总线空闲时,例如在刷新操作期间
在读未命中干净访问中,DQ 处于读状态且不用于数据传输
如果刷新缓冲区已满,控制器会发送显式的从刷新缓冲区读取命令,将多个条目作为一组传输,以摊销任何总线转向延迟。
控制器拥有刷新缓冲区中地址的全局知识。如果 DRAM 缓存收到对刷新缓冲区中任何地址的读请求,控制器将从缓冲区获取数据。如果对刷新缓冲区中的地址有写请求,传入的写请求将进入 DRAM 缓存,并且控制器会将旧数据从刷新缓冲区移除。我们的分析(§V-E)表明,如果假设缓冲区有 16 个条目,在读未命中干净和刷新周期期间传输,可以防止刷新缓冲区溢出。
早期标签探测优化
早期标签探测试图在标签相关资源空闲而数据相关资源忙碌的时期,加速对需求的标签检查。因此,它在不访问数据银行的情况下访问标签银行,并通过HM总线将结果返回给控制器。TDRAM的HM和命令总线有未使用的带宽,因为:
标签银行比数据银行更快;因此,标签银行的忙碌时间比数据银行短;
HM总线上传输的数据包大小(3B)远小于DQ总线(64B),而两个总线的工作频率相同。我们利用这个未使用的带宽进行早期标签探测,在此过程中,控制器可以查询缓存行的状态,并更早地获得命中/未命中的判定,从而使得后续操作(例如,从主存读取以应对读取请求未命中)能够更早开始。如图7所示,在一组流水线化的读取事务中,当数据总线被连续的数据传输完全占用时,CA总线和HM总线则不会被占满。标签探测利用空闲的CA总线周期发出探测命令,进行标签访问和比较。
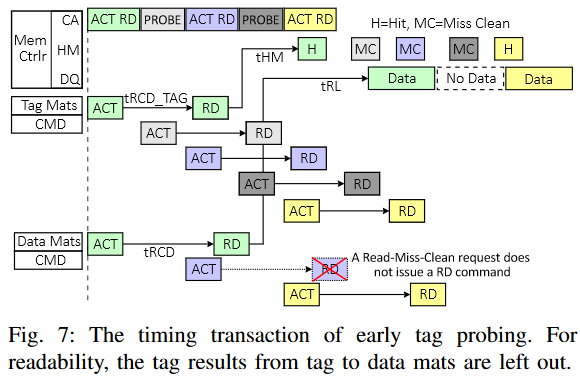
探测机制
标签探测只访问标签,通过HM总线传输结果,而不访问缓存行数据。图7区分了MAIN槽命令,它通过HM和DQ总线同时访问标签和数据,和PROBE槽命令,它仅访问标签和HM总线。虽然TDRAM在没有探测的情况下通过快速标签银行访问加速标签检查,但探测机制旨在通过最小化等待调度标签访问的请求的队列占用时间来减少标签检查延迟。早期标签探测降低了读取缓冲区中的争用,减少了需要的条目数,并减少了平均排队延迟。例如,如果探测结果显示读取需求是未命中的清洁(miss-clean),当标签检查结果通过HM总线到达控制器时,该请求可以从读取队列中移除。此外,它还减少了未命中延迟。例如,如果读取需求的标签探测结果是未命中,主存访问将比系统等待MAIN槽进行标签检查时更早开始,从而有效地将缓存行数据访问从关键路径中移除。未来的MAIN槽可以用于填充缓存行。
选择策略
一旦控制器找到一个PROBE槽,在所有可以在该时间发出的标签检查请求中(即没有银行冲突),它会选择最年轻的请求,以最小化控制器中的平均排队延迟。尽管写入数据包也可以使用探测,TDRAM重点将这些槽用于读取请求,以减少由于早期标签探测引发的潜在bank冲突。我们的分析表明,由探测引起的bank冲突并不常见(占总请求的不到1%)。
Evaluation Methodology
许多先前的DRAM缓存研究依赖于基于跟踪的或功能优先的模拟器,这些模拟器可能无法真实地模拟依赖于I/O或线程时序的应用行为,这些应用可能根据不同的路径执行[29]。相比之下,我们使用的是执行中的Full-System模拟器gem5。值得注意的是,之前的DRAM缓存研究通常忽略了完整系统的仿真,未能捕捉到操作系统的影响。Bin等人证明了操作系统内核瓶颈可能会降低DRAM缓存中的内存访问延迟[31]。我们扩展了gem5的内存系统,并实现了TDRAM设备和DRAM缓存控制器[18],[19]。该设备使用表III中列出的时序参数。§III-C4详细解释了TDRAM中标签的时序值设置。
我们将替代的DRAM缓存设计集成到gem5中,以评估TDRAM缓存的性能:
Cascade Lake:我们的评估基准,Intel的Cascade Lake中的先进商用DRAM缓存。这是一个块粒度的直接映射插入失效缓存,将标签和元数据存储在DRAM中。
Alloy:旨在减少命中延迟[58]。我们选择Alloy,因为它具有与TDRAM最相似的设计原则。Alloy的80B突发大小通过增加时序参数(例如,tBURST等)进行建模。
BEAR:旨在减少带宽膨胀[28]。
NDC:Native DRAM Cache是最近提出的一个方案,旨在提供可扩展的DRAM缓存,同时减少因缓存带来的数据移动[60]。与TDRAM不同,它没有早期标签探测机制。
TDRAM:我们提出的工作。
Ideal:一个理想的缓存,可以在零延迟下知道命中/失效和元数据状态。这为标签在SRAM设计设定了上限。
为了公平比较不同的设计,我们使用相同的时序参数来建模DRAM缓存设备,除非某个参数不适用于DRAM缓存(例如,表III中的tRCD TAG仅用于TDRAM)。我们建模了类似于Intel Xeon Max系列的目标系统的1/8,最终配置为64核和64 GiB的HBM(作为DRAM缓存),如图8所示。表III显示了建模系统的详细参数。
benchmarks 选的是NPB 和 GAPBS。
Results and discussion
Impact of Optimizing Tag Check Mechanism
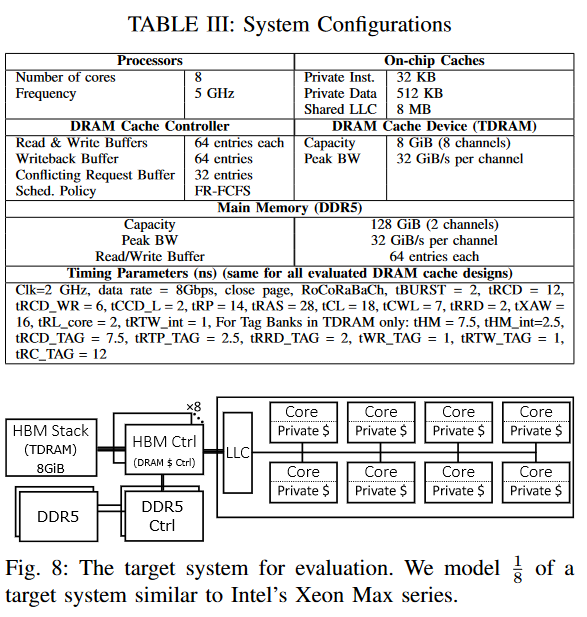
图9比较了TDRAM与Intel的Cascade Lake、Alloy、BEAR和NDC缓存的平均标签检查延迟。标签检查延迟是指从控制器发出标签读取请求到结果准备好并返回给控制器的时间。报告的数字是在仿真过程中通过控制器测量的,包括队列占用时间、DRAM缓存标签访问时间、标签比较延迟、总线延迟等。在Cascade Lake、Alloy和BEAR设计中,标签访问时间包括从缓存行数据中读取,而在NDC和TDRAM中,则是访问DRAM缓存中的单独标签银行。所有设计都使用相同的时序参数(表III)来访问缓存行数据。NDC使用在文献[60]中讨论的标签时序参数,TDRAM使用在§III-C4中讨论的经过验证的标签存储时序。TDRAM通过并行化标签和数据访问,并采用条件数据响应,比所有设计在所有应用中都能更快地指示命中/未命中。TDRAM还结合了早期标签探测,通过机会性地进行标签检查进一步加速了这一过程。通过几何平均,TDRAM的标签检查比Cascade Lake、Alloy、BEAR和NDC分别快2.61倍、2.65倍、2倍和1.82倍。我们还分析了没有早期标签探测的TDRAM标签检查延迟,其结果与NDC相似,因此在图中省略。
Overall Performance
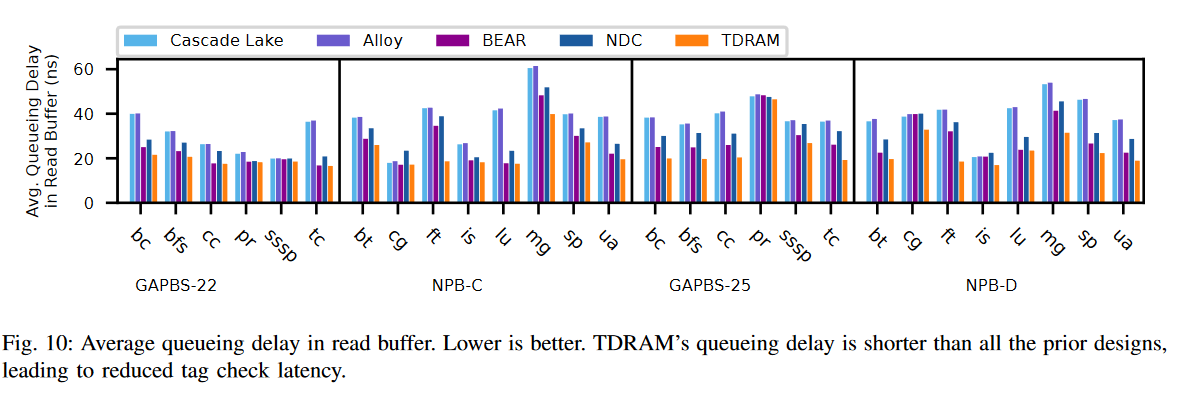
图11比较了TDRAM与其他设计的加速比。在所有工作负载中,TDRAM均优于Cascade Lake、Alloy、BEAR和NDC,提供了1.20×、1.23×、1.13×和1.08×的几何平均加速比。我们还评估了没有早期标签探测的TDRAM,其性能与NDC相似,因此在图中未单独显示。如§V-A所述,TDRAM有效地减少了标签检查延迟和队列延迟。这一改进对DRAM缓存的命中和未命中延迟以及LLC的未命中惩罚产生了积极影响。因此,系统的整体性能比现有设计有所提升,如图11所示。理想缓存以零延迟提供标签检查结果,消除了在标签检查过程中遭遇队列延迟和DRAM访问延迟的需求,作为一个完美的SRAM内标签缓存。它为缓存设置了性能上限,图11显示TDRAM接近这一理想,比所有先前的设计都更好。
图12比较了所有设计与仅有主存(没有DRAM缓存)的系统的加速比。如图所示,对于未命中率较低的应用,DRAM缓存可以提高系统吞吐量。随着未命中率的增加,由于DRAM缓存涉及主存访问的未命中惩罚,这种改进会减少。通过数据分析,Intel的Cascade Lake、Alloy和BEAR缓存分别导致了8%、10%和2%的几何平均减速。NDC提供了1.03×的几何平均加速比。TDRAM将几何平均加速比提高到1.11×,主要得益于其较低的命中延迟和未命中惩罚,相较于所有其他设计。
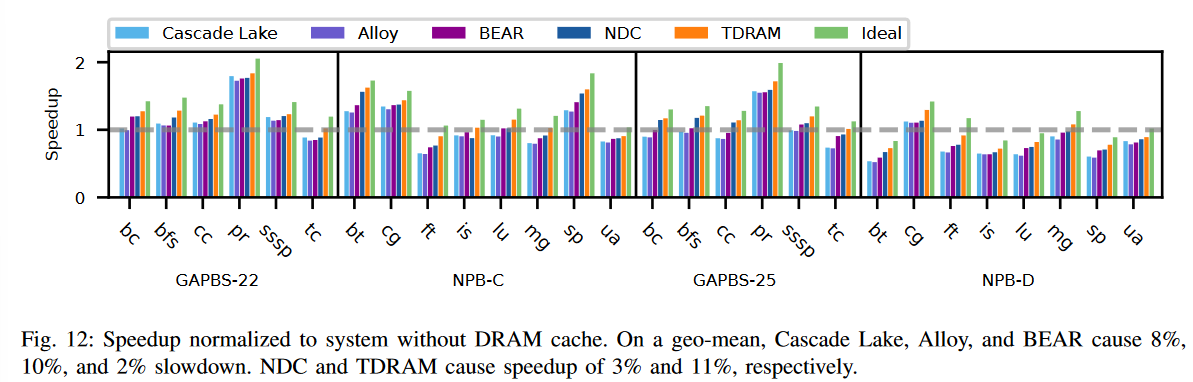
这两个图看起来好像speed up也没有太多??
TDRAM’s Energy Improvement
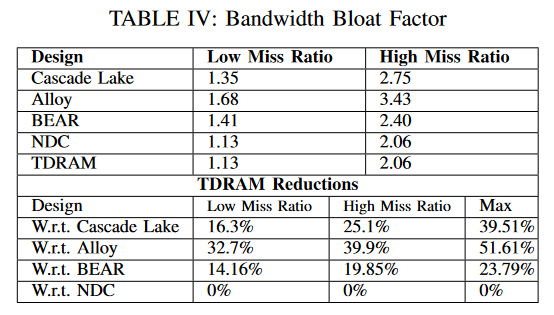
先前的研究将带宽膨胀因子定义为:传输的总字节数除以传输的有用字节数[28]。表IV显示了低未命中率和高未命中率工作负载的几何平均带宽膨胀因子。表中还显示了TDRAM实现的最大带宽膨胀减少。与Alloy、Cascade Lake和BEAR相比,TDRAM分别减少了39.9%、25.1%和19.85%的带宽膨胀。NDC的带宽膨胀与TDRAM相似,因为它们对于一个请求传输的数据量相同。
为了分析能耗,我们开发了一个HBM3功率模型,基于[55]中的HBM2功率数据,并根据HBM3的速度和时序(表III)进行了缩放。处理器接口功率是根据我们验证的HBM3 PHY设计计算的。与标准的HBM3 DRAM相比,TDRAM的功率有所增加,以考虑到片上标签存储和相关操作,同时由于额外的信号、HM总线和相关逻辑,DRAM缓存和处理器接口的功率也有所增加。
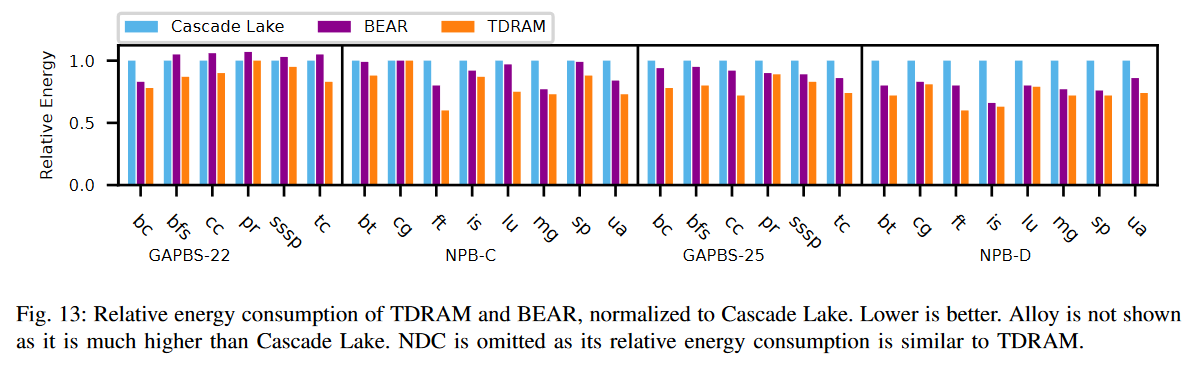
图13显示了TDRAM和BEAR缓存的相对能耗(功率×运行时间),并将其归一化到Cascade Lake作为基准。我们没有显示Alloy的能耗,因为它远高于Cascade Lake。此外,NDC和TDRAM的能耗是相似的,因为两个系统传输的数据量相同,如表IV所示。
我们预计,由于NDC具有更大的标签MATs和在数据传输不必要的情况下(例如,读-未命中清除)进行额外的数据列操作,它的部分能耗会略有增加,而TDRAM消除了这些操作。这些额外的操作对总能耗的贡献可以忽略不计,主要由传输的数据量驱动,而这在两个设计中是相同的。因此,NDC和TDRAM的整体相对能耗保持不变。
几何平均值上,TDRAM与Cascade Lake和BEAR相比的能效分别节省了21%和12%。这种节省主要得益于TDRAM协议中减少带宽膨胀。具有更多写命中的应用或读/写未命中清除(例如,ft和is)显示出与Cascade Lake相比,TDRAM节省了更多能量。具有更多未命中清除的应用(例如,ft,ua)显示出与BEAR相比,TDRAM节省了更多能量。
BEAR和Alloy一样,对于每个64B请求,访问粒度为80B,这即使在命中时也会消耗更多能量。随着带宽膨胀的增加,由于传输的数据量更多,消耗的能量也更多。TDRAM在其协议中消除了不必要的数据传输,在服务与其他设计相同数量的内存请求时节省了能量。
TDRAM的功率变化:为了并行访问标签和数据存储器,TDRAM同时激活所有涉及的存储器。而另一方面,TDRAM在DRAM中进行标签比较,仅在需要时选择性地将数据发送到控制器,从而显著减少带宽膨胀(见表IV)。以往的研究表明,HBM2将62.6%的功率用于在DRAM核心和控制器之间传输数据[10]。这使得像Alloy和BEAR这样的设计由于每64B内存需求传输80B数据而变得更加低效。相比之下,TDRAM通过仅在必要时将64B数据流传输到控制器,基于内DRAM标签比较,从而节省了系统整体的功率。TDRAM中的额外激活会略微增加功率,但与数据传输相比,这个增加是很小的。与Cascade Lake和BEAR相比,TDRAM的整体功率节省分别为7%和5%。
在DRAM本身,由于更多位并行访问,功率消耗会比普通DRAM更高。然而,HBM封装中的备用电 vias可以用于更多的电力传输,功率的增加不应导致显著的热问题。如前所述,这种内部DRAM功率消耗的增加远小于通过数据总线选择性数据流所节省的功率。
Performance Impact of Predictors and Prefetchers
我们设计了TDRAM,具有与预取器和预测器正交的特性,即任何现有或未来的预取器/预测器都可以与TDRAM一起使用,以进一步提高性能。我们评估了使用MAP-I预测器[58]对DRAM缓存性能的影响。结果显示,预测器对整体性能的影响较小,与没有预测器的缓存相比,整体加速比为1.03-1.04×。然而,预测器不能保证预测的未命中不是命中,这会导致效率低下,因为只有在读取标签后才能知道行的状态(脏或干净)。对于写操作,预测器必须始终读取数据,以避免覆盖潜在的脏行。TDRAM在其ActWr协议中通过将脏数据(如果有的话)读入刷新缓冲区,再写入传入数据来确保这一点。对于读操作,预测器可以在未命中的情况下加速主内存访问,但必须在缓存填充之前读取缓存数据,以避免覆盖脏行。TDRAM通过早期标签探测加速主内存访问,这是一种确定性的方式,而不是通过猜测来实现。
与此相比,TDRAM中的早期标签探测只在HM和命令总线的空闲槽位期间访问标签存储,最小化了时序影响并避免了带宽膨胀。我们的初步分析还显示预取器带来了增量的性能提升。原因在于预取器会干扰需求访问并消耗过多的带宽。由于DRAM缓存相较于片上缓存具有更大的容量和更高的延迟,因此它们特别容易受到资源利用的影响,包括带宽和缓冲区。根据预取的粒度(页、块等),它会增加对关键需求响应时间的尾部延迟,从而增加命中延迟。此外,如果预取器在每个应用程序中的准确率较低,它们还可能导致不必要的数据传输,增加带宽膨胀和能量消耗。所有这些因素都促成了预取器带来的增量性能提升。未来的工作可以探索专门针对DRAM缓存的预测器和预取器。
Flush Buffer Size Sensitivity Analysis
我们评估了不同刷新缓冲区大小(分别为8、16、32和64个条目)对性能的敏感性。结果表明,刷新缓冲区始终避免了被填满,从而防止了TDRAM的停顿,除了在NPB-D的lu工作负载中,当缓冲区大小为8时。此时,TDRAM仅停顿了13次,导致的性能开销可以忽略不计。大多数应用程序依赖于读取未命中清理访问来卸载刷新缓冲区。值得注意的是,lu和bc高度利用了刷新周期来卸载数据。这些数据确认了TDRAM在最小化数据传输开销方面的机会行为的有效性。刷新缓冲区的平均占用率为5个条目,最大为12个条目。将缓冲区大小设置为16可以防止TDRAM停顿。因此,刷新缓冲区的开销是最小的。
Set-Associative TDRAM
TDRAM 同样适用于直接映射和集合关联缓存。在图4中,如果一对bank group(例如,0和1,2和3等)构成一个集合的两路,如果每个路都有自己的比较器,则可以并行执行标签比较。匹配路的信号被发送到内部控制逻辑,以选择数据阵列中的正确列。没有内置DRAM标签比较器的实现则将集合中的所有标签发送到控制器,控制器随后向DRAM发送请求以获取正确的列,导致额外的延迟和能量消耗[48]。集合关联性有助于减少高未命中冲突的应用程序。然而,我们的分析显示,测试的HPC工作负载在DRAM缓存中几乎没有未命中冲突。因此,与直接映射缓存相比,它们从集合关联性中并没有获得显著的性能提升。我们的结果显示,直接映射缓存和2、4、8、16路集合关联缓存的加速效果相似(与仅有主内存的系统相比)。
所以其实如果是set-associative的情况下,还是需要加电路?而且HBM内存相比DRAM小很多,Direct-mapped方式也将内存大小限制死在HBM的相同容量?