GPU Learning
GPU计算模型
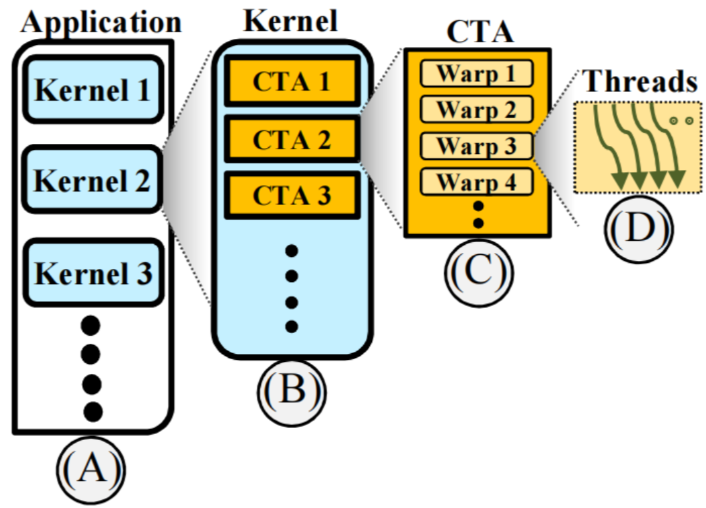
在GPU计算模型中,应用程序(Application)、内核(Kernel)、线程块(Thread Block,即CTA)、线程网格(Thread Grid)和Warp之间存在层级关系。
Application:应用程序是最高层级,它包含了一个或多个内核(Kernels)。每个内核都是一个需要并行执行的任务。
Kernel:内核是由应用程序启动的并行计算任务。每个内核包含一个或多个线程块(CTA)。内核定义了所有线程要执行的代码。、
Thread Grid:也称为网格,是内核启动时所创建的所有CTA的集合。Thread Grid定义了内核执行的整体范围。每个Thread Grid由多个CTA组成,每个CTA再由多个warp组成。
CTA(Cooperative Thread Array):CTA是CUDA中的术语,指线程块(Thread Block)。每个CTA包含多个线程,线程块内的线程可以共享内存并进行同步。每个内核中可以包含多个CTA。
Warp:每个线程块中的线程按warp进行分组。一个warp通常包含32个线程。这些线程作为一个单元同时调度和执行。Warp是实际执行的最小单位
总结来说:Application 包含一个或多个 Kernel,Kernel 启动一个 Thread Grid,包含多个 CTA,每个 CTA 包含多个 warp(每个warp包含32个线程)。
warp 和 threads
同一程序:
每个线程在一个warp中运行相同的指令序列,这意味着它们执行相同的程序代码。这个程序代码由内核(kernel)函数定义。
线程ID:
虽然所有线程执行相同的程序代码,但每个线程有一个唯一的线程ID(thread ID),通过这个ID,线程可以访问不同的数据。这使得线程能够并行处理不同的数据块,从而实现并行计算的目的。
SIMT(Single Instruction, Multiple Threads)模型:
GPU采用SIMT模型,意味着一个warp中的所有线程同时执行相同的指令。如果某些线程需要执行不同的路径(例如,通过条件语句),会导致warp中的部分线程被屏蔽(inactive),而其他线程继续执行,这称为“warp分歧”(warp divergence)。这种情况会影响并行执行的效率,因为屏蔽的线程必须等待其他线程完成。这也就是经典的
lock-step锁步执行。
通过
lock-step锁步执行,所有线程可以共享相同的程序计数器(PC)、源寄存器ID和目标寄存器ID。
GPU寄存器数量与CUDA Thread Block划分
寄存器的静态分配:
GPU中的寄存器数量是影响CUDA thread block数量的重要因素之一。虽然GPU内部是按照warp(每32个线程组成一个warp)来执行的,但寄存器是静态分配给每个线程的,而不是分配给warp的。
这意味着每个线程在执行之前就已经分配好了所需的寄存器数量。如果一个kernel函数需要较多的寄存器,那么能够在同一时间运行的thread block数量就会减少,因为每个SM(Streaming Multiprocessor)上的寄存器数量是有限的。
寄存器访问:
在warp执行时,32个线程同时执行,每个线程需要读取源寄存器和写入目标寄存器。假设每个寄存器是4字节(4B),那么每个warp的32个线程同时读取时,会读取128字节(32线程 * 4字节 = 128字节)。
因此,128B 的大小也正好是GPU L1 Cache的cacheline大小。
GPU与CPU缓存一致性
缓存一致性(Cache Coherence)
与CPU不同,CPU的每一级缓存都需要维护MOESI(Modified, Owner, Exclusive, Shared, Invalid)一致性协议,以确保多个处理器间的数据一致性。
对于GPU,线程的私有内存不需要与其他线程共享,因此不需要复杂的缓存一致性机制。这意味着对于local memory(本地内存),可以采用write back(回写)策略,而对于global memory(全局内存),则可以采用write evict(写驱逐)策略。
Local Memory:GPU线程的本地内存不需要共享,因此可以使用write back策略来优化性能。
Global Memory:全局共享内存需要与其他线程共享,可以采用write evict策略来减少一致性开销。
Write Evict是一种缓存管理策略,指的是当缓存数据发生写入操作时,直接将数据从缓存中驱逐出去,而不是写回到主存或者其他缓存级别。这种策略用于减少复杂的缓存一致性管理开销,尤其是在不需要频繁访问相同数据的情况下。
当GPU线程执行写操作时,数据不会保留在缓存中。相反,数据会直接驱逐出缓存。这意味着写操作的数据不会在缓存中存在,而是直接更新到主存。在GPU高并行性计算中,许多数据访问是一次性的,数据在写入后不再被频繁读取。write evict策略避免了不必要的缓存填充和一致性维护,提高了缓存利用效率。
在NVIDIA的CUDA编程指南中,许多示例和优化策略都假设数据是一次性访问的。例如,在卷积操作和矩阵乘法等任务中,数据处理后不再需要重复访问 。高并行性计算任务,如矩阵乘法、大规模图像处理、科学模拟等,通常采用数据并行性模型。在这种模型中,每个处理单元(如GPU线程)处理数据的一个独立子集,数据在处理完后很少被重复访问。
CPU&GPU寄存器优化
CPU寄存器优化:
编译时优化: 编译器在编译程序时,会根据寄存器的“活跃时间”(live time)来优化寄存器的使用。寄存器的“活跃时间”指的是寄存器中存储的值在程序中的有效周期。编译器会尝试在有限的寄存器数量内减少数据依赖问题,提高代码执行效率。
执行时重命名: 在 CPU 内部执行时,CPU 还会进行寄存器重命名。这是为了进一步解决寄存器之间的依赖问题,并优化性能。寄存器重命名允许 CPU 使用更多的物理寄存器,以避免数据冲突和等待。
GPU寄存器优化:
编译时优化: 在 GPU 中,编译器主要在编译阶段进行寄存器优化。编译器会根据每个线程的需求确定寄存器的使用上限,并尽量减少对内存的使用。GPU 程序的编译器负责将寄存器分配给每个线程,以优化性能。
执行时设计复杂性: GPU 的执行单元(如每个 warp 的寄存器重命名单元)设计复杂,如果在执行时增加寄存器重命名单元,会大幅增加设计复杂度。因此,GPU 只能依赖编译时设定的寄存器上限,实际运行中可能会有寄存器使用量的波动。
实际影响:
寄存器使用波动: 由于 GPU 中寄存器的使用在编译时已被固定,而不进行执行时动态调整,实际运行时可能出现寄存器使用量的波动。这就导致了 GPU 性能的波动,特别是在不同的线程和不同的 warp 中。
优化研究: 为了提高性能,很多研究集中在如何优化 GPU 寄存器的使用,减少资源浪费并提高效率。
GPU Warp 分歧
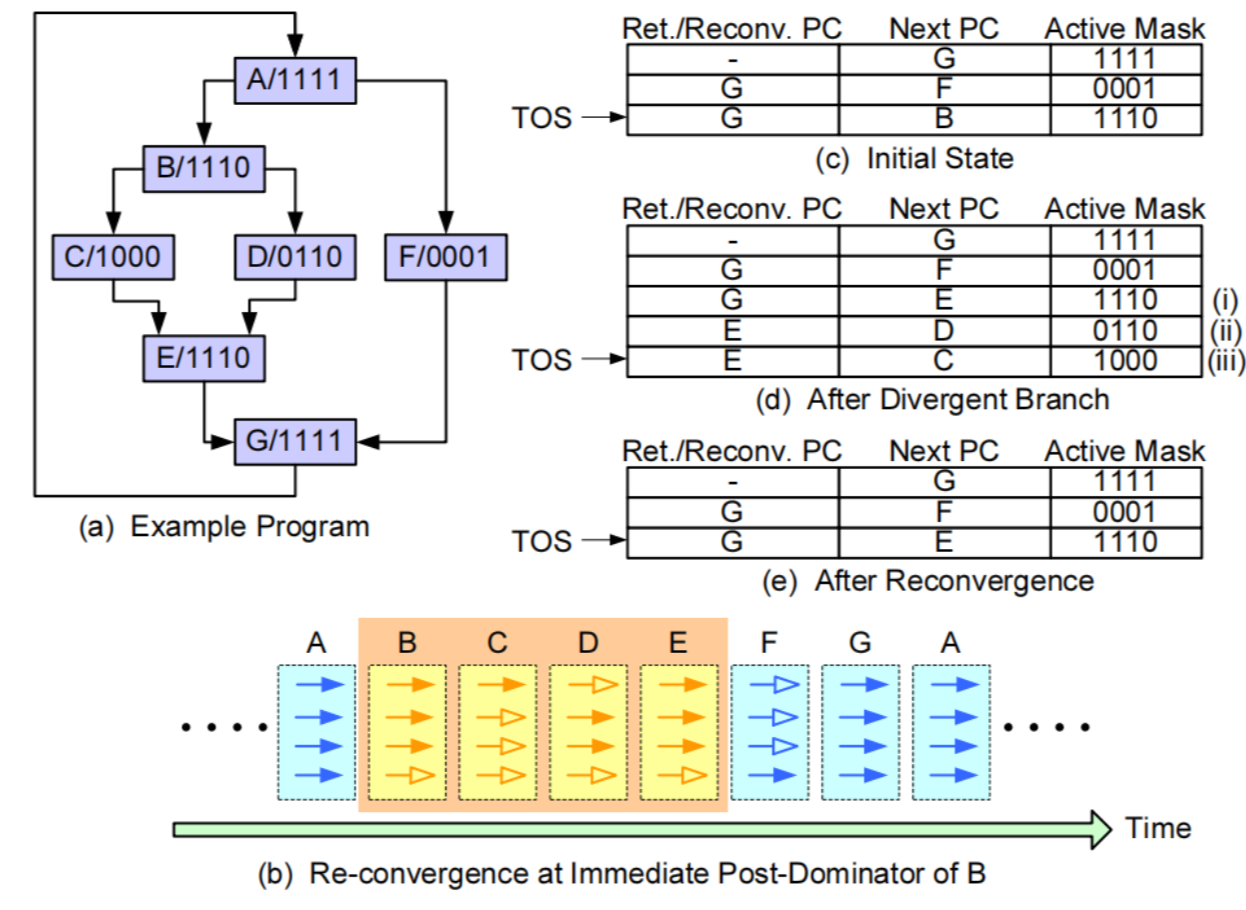
GPU没有CPU的分支预测,使用active mask和predicate register来构建token stack来处理遇到分支时的问题。
CPU 的分支预测:
分支预测: CPU 使用分支预测技术来提高流水线效率。当遇到分支指令(如
if或switch语句)时,CPU 会猜测哪个路径更可能被执行,以提前加载和执行相关指令。这种技术减少了由于分支延迟带来的性能损失。
GPU 的分支处理:
没有分支预测: GPU 通常不使用传统的分支预测技术。由于 GPU 的架构设计和并行计算特性,传统的分支预测方法并不适用于 GPU。
Active Mask 和 Predicate Register: GPU 使用不同的方法来处理分支情况,这包括:
Active Mask: Active Mask 是 GPU 中的一种机制,用于追踪哪些线程在执行特定的指令。它是一个掩码,表示哪些线程是“活跃”的(即正在执行当前指令)。在分支指令执行时,只有掩码中标记为“活跃”的线程会执行相应的代码路径。
Predicate Register: Predicate Register 是一种特殊的寄存器,用于存储布尔条件(如分支条件的结果)。这些寄存器帮助决定哪些线程应该执行分支后的代码路径。
Token Stack: GPU 使用 token stack 的概念来处理分支指令。这种技术可以帮助 GPU 确定在遇到分支时如何处理不同的代码路径。Token stack 是一种栈结构,用于跟踪和管理线程的执行状态。每个线程可以根据分支条件在栈中推送或弹出不同的状态,确保正确的代码路径被执行。
总结:
GPU 通过 active mask 和 predicate register 来处理分支指令,而不是使用传统的分支预测技术。Active mask 用于跟踪哪些线程在执行,predicate register 存储分支条件的结果,token stack 帮助管理线程的执行状态。这些方法使 GPU 在处理大量并行线程时能够有效地应对分支情况,减少由于分支导致的性能损失。
Active Mask 举例
假设有一个 GPU 核心正在执行一个计算任务,涉及到 4 个线程(T1、T2、T3、T4)。在某条指令执行时,只有 T1 和 T3 是活跃的,其它线程(T2 和 T4)被挂起。此时,Active Mask 可能是 1010,表示 T1 和 T3 是活跃的,而 T2 和 T4 不是。
当遇到条件分支指令时(比如 if 语句),只有 Active Mask 中标记为“活跃”的线程会执行这条分支指令的代码路径。这样,T2 和 T4 会被跳过,不会进行分支代码的计算。
Predicate Register 举例
假设有一个条件语句 if (x > 5)。在 GPU 的每个线程中,Predicate Register 存储此条件的结果。例如,线程 T1、T2、T3、T4 分别计算出条件的结果为 true、false、true、false。Predicate Register 可能会存储这样的结果 [true, false, true, false]。
在执行条件分支时,GPU 将根据 Predicate Register 中存储的结果来决定哪些线程执行 if 语句中的代码。例如,只有 T1 和 T3 会执行 if 条件下的代码,而 T2 和 T4 不会执行。
这是一种GPGPU Token Stack:
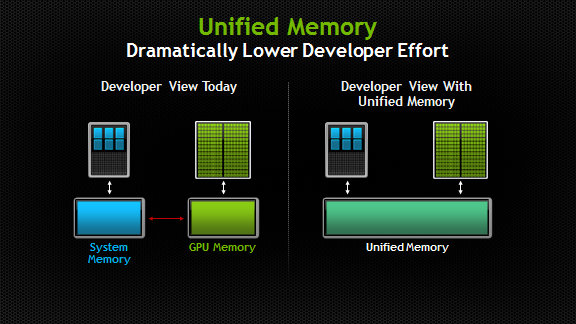
GPU Unified Memory
在没有 Unified Memory 的 GPU 编程中,开发者需要显式地管理内存的分配和数据的传输。内存分配通常涉及到 GPU 设备内存和主机(CPU)内存之间的数据传输。
以下是一个没有Unified Memory的简单示例:
x
// 修饰符,表示这是一个核函数(GPU 执行的函数),从主机端调用__global__ void add(int *a, int *b, int *c, int N) { // 计算当前线程在一维数据中的索引。threadIdx.x 是线程在块内的索引,blockIdx.x 是块的索引,blockDim.x 是每块中的线程数。 int index = threadIdx.x + blockIdx.x * blockDim.x; if (index < N) { // 确保索引不超出数组边界,然后执行加法操作。 c[index] = a[index] + b[index]; }}
int main() { int N = 1000; // 定义数组的元素数量 int size = N * sizeof(int); // 计算数组所需的字节数。每个 int 类型的大小是 sizeof(int) 字节 // 分配主机内存,在主机端分配内存,用于存储输入和输出数据 int *h_a = new int[N]; int *h_b = new int[N]; int *h_c = new int[N];
// 使用循环初始化 h_a 和 h_b 数组,填充数据以供 GPU 使用 for (int i = 0; i < N; ++i) { h_a[i] = i; h_b[i] = i; }
// 在 GPU 上分配内存,大小与主机内存相同。cudaMalloc 用于分配 GPU 内存。 int *d_a, *d_b, *d_c; cudaMalloc(&d_a, size); cudaMalloc(&d_b, size); cudaMalloc(&d_c, size);
// 将 h_a 和 h_b 数组中的数据从主机复制到 GPU 设备内存 d_a 和 d_b 中。cudaMemcpy 用于数据传输,cudaMemcpyHostToDevice 指定数据传输方向。 cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// Launch kernel int blockSize = 256; // 每个线程块中的线程数量。这里设置为 256 // 计算需要多少个块来处理所有的数组元素。 (N + blockSize - 1) / blockSize 确保所有元素都被处理。 int numBlocks = (N + blockSize - 1) / blockSize; // 调用核函数 add,传递参数 d_a、d_b、d_c 和 N。<<<numBlocks, blockSize>>> 语法指定了块和线程的配置 add<<<numBlocks, blockSize>>>(d_a, d_b, d_c, N);
// 将计算结果从 GPU 内存 d_c 复制回主机内存 h_c。cudaMemcpyDeviceToHost 指定数据传输方向。 cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
// 释放主机内存和设备内存,避免内存泄漏 delete[] h_a; delete[] h_b; delete[] h_c; cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;}这一段是在有Unified Memory的时候
xxxxxxxxxx
__global__ void add(int *a, int *b, int *c, int N) { int index = threadIdx.x + blockIdx.x * blockDim.x; if (index < N) { c[index] = a[index] + b[index]; }}
int main() { int N = 1000; size_t size = N * sizeof(int); // 在 GPU 和 CPU 之间分配统一内存,指向的内存可以被主机和设备同时访问。 int *a, *b, *c; cudaMallocManaged(&a, size); cudaMallocManaged(&b, size); cudaMallocManaged(&c, size);
// 使用一个循环来初始化 a 和 b 数组的内容。在主机和设备内存中都可以直接访问和修改这些数组 for (int i = 0; i < N; ++i) { a[i] = i; b[i] = i; }
// Launch kernel int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; // 调用核函数 add,传递参数 a、b、c 和 N,<<<numBlocks, blockSize>>> 语法指定线程块和每块中的线程数。 add<<<numBlocks, blockSize>>>(a, b, c, N);
// 等待 GPU 完成,确保所有 GPU 任务完成,这样在主机上访问 c 数组时,结果是准确的。 cudaDeviceSynchronize();
// 释放统一内存 cudaFree(a); cudaFree(b); cudaFree(c);
return 0;}统一内存简化了内存管理过程,因为主机和设备可以直接访问相同的内存区域,省去了显式的数据传输步骤
Unified Memory 是在CUDA 6 时期被引入的,但是主机和设备不能同时访问同一内存页。每次只有一个处理单元(CPU 或 GPU)可以访问特定的内存页。统一内存的访问可能需要解决访问冲突。
GPU Page Fault 是在CUDA 8 时期被引入的,同一时期,GPU虚拟寻址范围增大,可以支持更大的虚拟地址空间。CUDA 8 引入了对页错误(page fault)的支持,这使得 GPU 可以按需分配内存。当 GPU 访问尚未分配或被交换到磁盘的内存页时,会触发页错误。系统会在发生页错误时将所需的内存页加载到 GPU 内存中。这种按需分配机制类似于 CPU 的虚拟内存管理,允许 GPU 更有效地使用内存资源。
GPU Page Fault
Demand paging 是一种内存管理机制,用于按需加载内存页。当程序访问一个当前不在内存中的页面时,系统会触发页错误(page fault),然后从存储设备(例如磁盘)加载所需的内存页到主存中。在 GPU 中,demand paging 使得 GPU 可以处理比其物理内存更大的数据集,通过按需加载内存页来处理超出物理内存容量的数据。这种机制也称为内存超订(memory oversubscription)。
GPU 与 CPU 的分页处理区别
CPU 的分页处理:
CPU 支持处理页错误(page fault),能够精确地处理异常,执行上下文切换,并根据需要加载或交换页。
CPU 能够处理精确异常(precise exceptions),即可以确保在处理页错误时,所有指令的执行状态都保持一致,程序可以在发生页错误后正确恢复执行。
GPU 的分页处理:
GPU 不具备处理精确异常的能力。它无法像 CPU 那样在发生页错误时精确地恢复状态。
当 GPU 遇到页错误时,处理机制如下:
暂停所有 Warp 的执行:
GPU 可以选择暂停所有的 warp(一个 warp 是一组同时执行的线程)。这种方式会让所有正在运行的线程停止执行,直到页错误得到解决。这种做法可以确保在页错误处理期间没有线程继续执行,从而避免数据不一致性问题。
暂停当前 Warp 的执行,调度其他可以执行的 Warp:
GPU 还可以选择只暂停当前遇到
page fault的 warp,然后继续调度其他没有遇到page fault的 warp 执行。这种方式允许其他 warp 继续进行计算,减少由于页错误导致的整体性能损失。
显然第一种代价更大,因此GPU按照第二种执行,内部也就需要存放一个page fault queue。而后具体的处理page fault,搬运page的操作,超出了GPU的能力范围,需要CPU执行或者CPU发送命令到GPU执行。
具体的流程如下:【HPCA'16 Towards High Performance Paged Memory for GPUs】
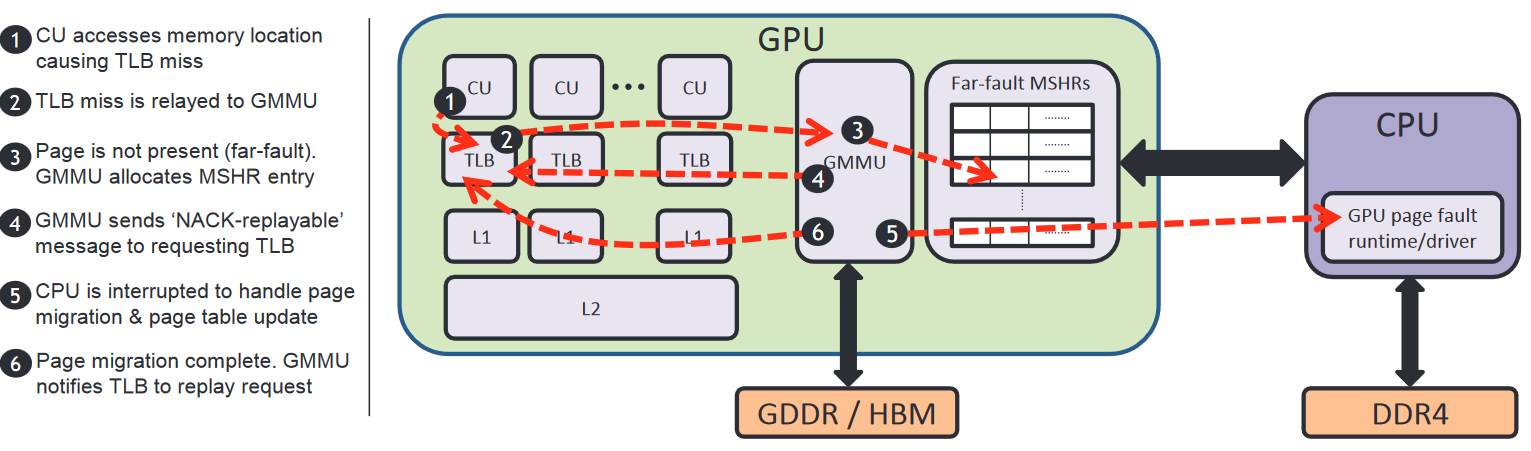
上述图片进攻参考,图序号和下面Step不对应
S1: GPU内部单元向TLB发起虚实地址转换请求
S2: TLB miss,而后在GPU MMU Page Walk,查询页表
S3: 依然miss后,触发page fault, GMMU向内部单元发送该地址翻译失败响应,挂起该warp
S4: GPU将page fault存到page fault queue中,向CPU发起page fault异常请求。
S5: CPU执行GPU runtime程序从page fault queue中读取page fault的请求,不同于CPU处理CPU page fault的直接处理方式,GPU可能会同时发生多个page fault,于是:
对page fault queue中的地址进行排序sort
Sort之后,方便在CPU的页表中进行查找
不同于CPU处理CPU page fault的另一点是,不仅会处理GPU的page fault对应的页,也会进行prefetch其他的页,预取一些页进入GPU内存,提高page fault的利用效率
S6: 之后根据该page的属性,CPU需要unmap这个page,将该页放到GPU的内存中,同时在GPU的页表中增加这个page,并flush 这个GPU uTLB(Unified Translation Lookaside Buffer)
uTLB(Unified Translation Lookaside Buffer) 是一种缓存,用于加速虚拟地址到物理地址的转换。它存储了最近访问的地址映射。
[ChatGPT] GPU里的TLB一般指的就是 uTLB
S7: 完成上述操作后,GPU才可以重新将page fault的warp重新调度
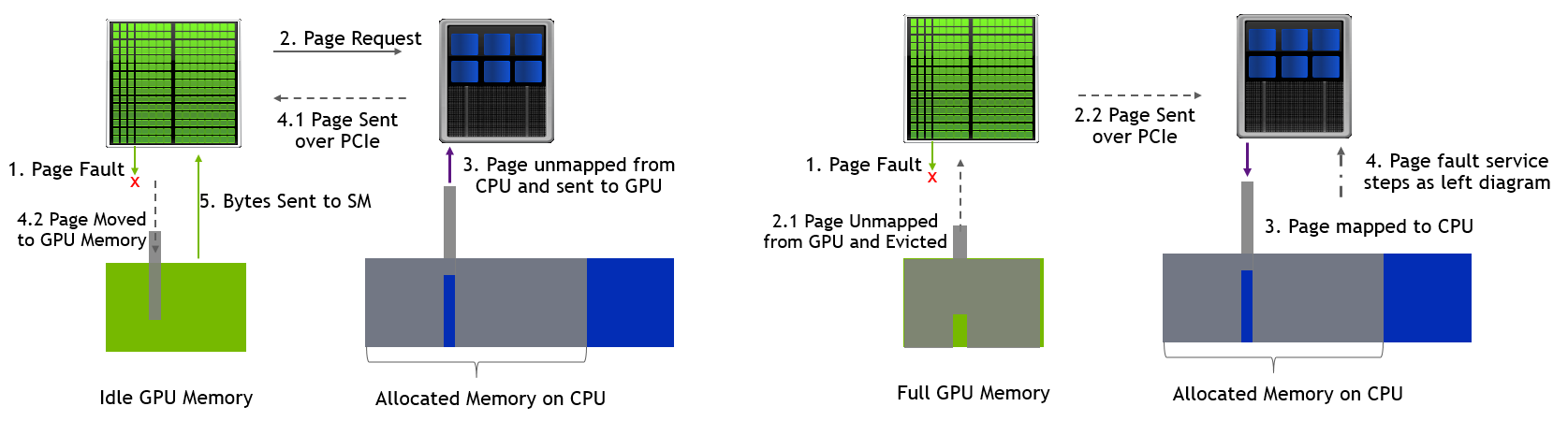 )
)
这个图分别是GPU内存有空闲和满了的状态,由于GPU显存其实不太多,所以大部分Page Fault都是右边这个图。
而右边这个图事实上也会执行左边这个图的大部分执行过程,所以开销挺大的。
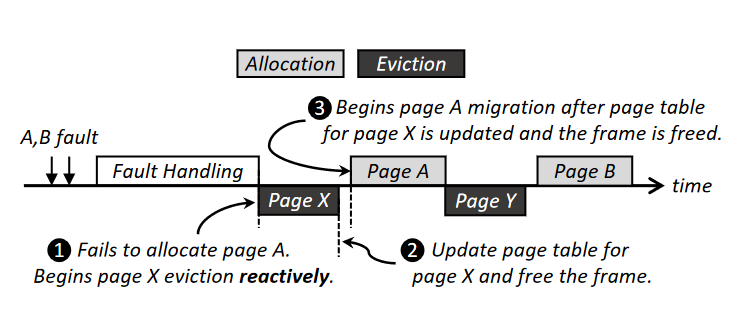
为了保证页表的顺序更新,evict旧页操作和fetch新页的操作还需要顺序执行,如下图所示,需要PageX被eviction之后,pageA才能allocation。
【ASPLOS'20 Batch-Aware Unified Memory Management in GPUs for Irregular Workloads】
【ASPLOS'20 Batch-Aware Unified Memory Management in GPUs for Irregular Workloads】发现GPU处理evict和fetch的操作是顺序的,以保证正确性,因此他们提出可以在中断处理时,先evict一个页,因为GPU内存向CPU内存写,比读要快,因此evict和fetch操作可以并行执行。
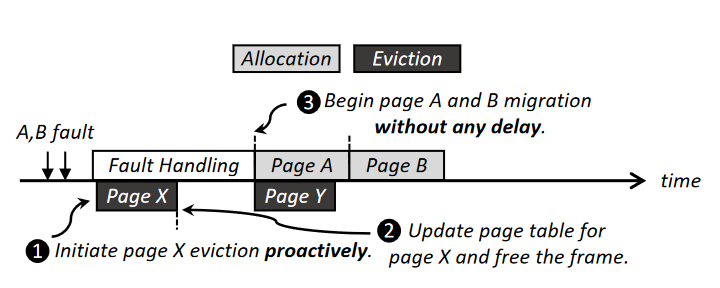
同时该论文还提出了我们还可以增加thread oversubscription,这样当所有的thread都page fault时,可以调度其他的thread block进入,类似于CPU的context switch。
HPCA16年的工作Towards High Performance Paged Memory for GPUs