PET [EuroSys'25]
【Title】 PET: Proactive Demotion for Efficient Tiered Memory Management
Comments
感觉这篇文章需要吐槽的有很多,我没有觉得这是一个很好的工作。当然,这篇文章的写作画图水平绝对一流。从我本身的理解触发,我依然不认可这篇文章能够在2025年被系统A会接收。
文章基于malloc()这种内存对象抽象出一个P块,类似于OS的Huge Page;但这实在是有太多值得商榷的点了:
文章claim说内存对象这种一定具有很强的局部性,然后启用了GB级的P块作为升级降级的基本粒度(当然后面有提拆分成临时块)。但是一个liblinear怎么可以代表通用性?
文章核心claim的motivation是节省fast memory的usage,从而避免页面升级时极大概率需要提前降级页面的case。BTW, 这么大的P块做promotion这不是左右脑互博吗?就算是一个阈值,但如果只有少数hot page,那又怎么办呢???
这个P块和临时块的概念,和page & subpage的概念基本上是一样,某种程度上只是都变大了,所以文章没有让我特别眼前一亮的地方。
实验缺乏和最新的tiered memory systems的对比,即使和Thermostat,TPP相比,实验的性能优势也就那样。
甚至图和图注还有benchmark对不上的错误。
......
当然可能是我理解不到位,文章大概花了4个小时左右看的。但我是reviewer,这篇文章我只会给到2分(weak reject)。当然EuroSys已经很random了,做系统的同学也总是要毕业的......
Abstract
分层内存是一种通过将DRAM作为上层(高速内存)与低速但廉价的字节可寻址内存作为下层(低速内存)相结合,以更低成本提升主存容量的创新方案。主动降级作为高效利用分层内存的关键技术之一,即使在高速内存具有充足空闲空间时,也会将冷数据降级至低速内存。现有研究通过主动降级减少应用在高速内存中的驻留集大小,从而降低主存的高成本。此外,当热数据需求激增时,该技术有助于缓解因高速内存短缺导致的严重性能下降。
但我们发现,利用应用内存分配单元内的访问局部性特征,能够以更低系统开销实现更大的高速内存节省。为此提出新型主动降级方案PET,通过扩展降级/提升操作单元实现高效分层内存管理:将传统基于操作系统页面的操作单元(现有方案采用)扩展为PET块(P块)——其设计反映了应用的内存分配单元特性。PET还配套提供精准选择降级目标P块的机制,并在访问模式变化时快速提升已降级P块。
基于Linux内核v6.1.44的PET原型系统在评估负载中实现了39.8%(最高80.4%)的高速内存使用量下降,平均性能损失仅1.7%。当系统内存使用量超出高速内存容量时,相较标准Linux内核减轻了31%的性能下降幅度,其表现优于当前最先进的分层内存管理方案。
Introduction
分层内存系统可以降低TCO,比较cost-efficient。分层内存系统的性能受限于slow memory的访问,所以在软硬件层面有不少工作将具有 局部性/热 数据升级,伴生地选择冷数据降级。这篇文章主要的出发点不是热数据升级,而是聚焦于优化降级。
现有的OS通常采用惰性降级的策略,当fast memory容量低于阈值/水位线才触发冷页迁移。但该策略可能导致高速内存容量不足,迫使系统在分配高频访问数据(热数据)前就必须降级冷页[41,60,63],同时也会限制系统中其他并发应用可用的高速内存资源。
换句话说,就是因为把fast memory一直放的比较满,就会导致(几乎)每一次提升热页都会首先需要触发一次冷页面降级,从而影响系统的并发性能
所以就有了主动降级的工作,通过减少应用在fast memory的驻留集大小(<25%),降低对fast memory的占用,避免上面注释说的问题。基于数据中心应用中冷页占比普遍较高(平均30-40%),主动降级策略可以更激进,有望以更低性能开销实现更大的高速内存使用量削减。
我觉得分层内存系统比较chanllenge的点其实是识别冷数据,我总是觉得识别热数据的方法有很多,但是识别冷数据的方案不太多。
为实现激进式主动降级,建立科学的降级标准与管理单元至关重要,以精准识别不影响性能的冷数据。基于硬件性能监控单元的分析,我们发现基准测试程序通常在其内存分配单元(如malloc()分配的内存对象)内部呈现访问局部性特征。为深入探究内存分配单元特性,我们通过手动修改应用程序,采用该单元进行激进式降级与提升操作。优化后的二进制文件可实现13.2%至84.7%的高速内存使用节省,而性能损失仅轻微增加(0.76%-2.82%),这证明了基于内存分配单元的管理方案具有可行性。
我们提出名为PET(高效分层内存管理的主动降级方案)的新型主动降级机制,该方案利用内存分配单元内的访问局部性特性。通过从操作系统管理虚拟地址空间的数据结构中提取PET块(P块)——其可近似模拟内存分配单元,我们将管理单元从操作系统页扩展至P块。基于P块内部的访问局部性,PET仅通过采样P块中的页来追踪访问模式。该方案采用多级判断机制(包括P块分割与部分预降级探测),对未被访问的P块执行降级操作。这种P块粒度的降级能以极低性能开销显著减少高速内存使用。
此外,PET引入冷文件页降级功能以进一步提升高速内存节省效果。最后,方案提供P块粒度提升机制:通过动态调整的提升阈值,在低速内存访问导致的性能下降超出可容忍程度前,及时重新提升已降级的P块。
PET还区分了匿名页和文件页?
本文的核心贡献如下:
• 通过实验观测发现基准测试程序在内存分配单元内普遍呈现访问局部性特性,经手动修改的优化二进制文件在该单元内执行主动降级/提升操作,能以低性能开销实现大幅高速内存使用削减(§3);
• 提出PET主动降级方案,通过捕获近似内存分配单元的P块(§4.1),实现P块粒度的数据降级目标精准识别(§4.2);
• 设计提升机制,通过追踪已降级P块的访问状态,在影响系统性能前及时执行提升操作(§4.3);
• 当聚合工作集适配高速内存容量时,PET能以仅1.7%的性能下降实现39.8%(最高80.4%)的高速内存使用削减;当内存使用量超出高速内存容量时,较默认Linux内核减轻31%的性能下降(§5)。
Background
OS-level Management for Tiered Memory
正如我上面说的,判断冷页的方法相对判断热页来说不太懂。OS的LRU链表是一种,但本质上是基于局部性。剩下的扫PTEs,或者诱发page faults来track页状态,本质上和识别热数据的方式是一样的,不是热的数据那就是冷的数据;还有就是性能计数器PEBS等等。每种方法各有优势,选择最适合自身机制的方案至关重要。具体的机制,前面分层内存的笔记写了很多,不再赘述。
Demotion with a Tight Threshold
为最大限度减少低速内存访问,多数方案采用严格阈值(如linux watermark)——该标准通过限制页分配/提升操作,或强制要求提升必须伴随降级来实现。watermark设置一般不太高,使得降级仅在高速内存空闲容量不足时执行。当总工作集适配高速内存容量时,这些方案因完全使用高速内存而展现最优性能;但当总工作集规模超出高速内存容量时,高速内存的匮乏将导致分配/提升操作必须同步进行降级,进而损害系统性能。
看到这里,难道不能适当拉大阈值,同时达到阈值异步降级冷页?
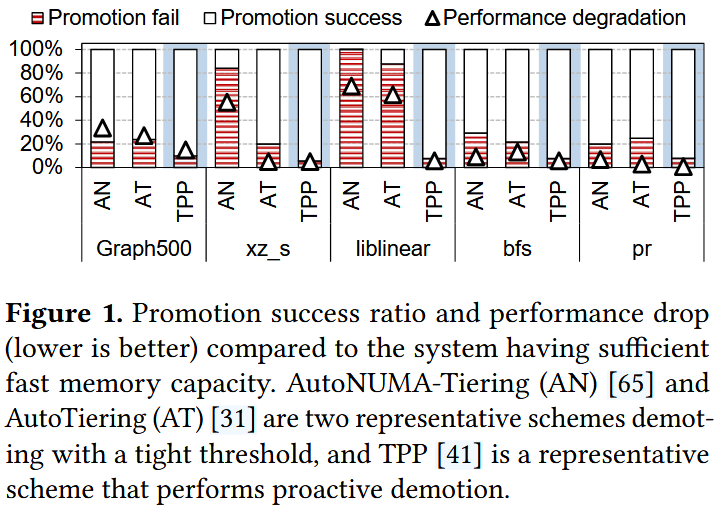
采用Linux水印触发降级的两个代表性方案——AutoNUMA-Tiering(AN)与AutoTiering(AT)——均呈现上述特性。图1展示了当工作集规模达到高速内存容量1.5倍时,因高速内存空闲不足导致的提升失败率及AN/AT的性能下降情况(详细实验配置见§5.1)。与具备充足高速内存的系统相比,AN和AT分别表现出52.9%与37.4%的提升失败率,以及19.9%和11.1%的平均显著性能下降。其中liblinear因提升失败率最高而呈现最大性能衰减,而pr则因提升失败率较低仅出现轻微性能下降。该结果表明:当系统内存使用量超出高速内存容量时,严格阈值触发的降级机制会制约提升操作与高速内存分配。
这个promotion fail感觉得看代码,看一下它是怎么判断的。宏观上就是满了,所以提不上去。
Proactive Demotion
Far Memory与TMO建议通过将冷页(最高20%)回收至交换设备来降低昂贵主存成本,且不受高速内存使用状态影响。
TMTS和Thermostat同样聚焦通过主动降级降低内存成本,但专门针对分层内存系统:TMTS旨在用低速内存替代25%的DRAM,同时将性能衰减控制在5%以内。其通过每30秒扫描所有页的访问位识别最不常用(LFU)页进行降级,并维护冷年龄直方图追踪未访问页;Thermostat则采用不同策略——追踪每个大页的访问计数:为降低开销,其对5%的2MB大页采样,并在每个大页内重采样50个4KB页;通过毒化采样页的页表项(PTE)触发虚假页错误,以估算采样间隔内的低速内存访问次数;最终将估算值与基于用户定义性能下降阈值(3%)的预计算值比较,通过迁移操作满足目标低速内存访问量。尽管Thermostat实现了显著的高速内存节省,但因过度使用虚假页错误可能导致严重性能下降。
TPP,MEMTIS与FlexMem通过预留少量高速内存空间用于提升和分配操作,以克服§2.2所述严格阈值降级方案的局限性。
TPP提出采用新的降级触发水印(demotion_watermark,设置为高速内存容量的2%),在达到临界内存阈值前主动降级冷页。如图1所示,TPP仅产生7.7%的提升失败率与4.7%的平均性能下降。
MEMTIS利用基于硬件的采样技术,在启用透明大页的分层内存系统中管理页布局与大小。它追踪各页访问次数的移动平均值,并维护所有页的访问直方图,优先将频繁访问(更热)的页保留在高速内存中。与TPP类似,MEMTIS在高速内存空闲空间低于预设阈值(2%)时触发降级。FlexMem在MEMTIS基础上扩展了虚假页错误访问追踪功能以提升分析精度,并采用自适应方式决定降级页数量,有效减少了提升失败。然而,由于TPP、MEMTIS和FlexMem仅为了维持少量高速内存空闲空间以改善性能而执行主动降级,未能充分发挥潜在的内存节省效益。
现有主动降级研究主要聚焦于降低高速内存容量需求或预防因高速内存不足导致的性能下降。然而,数据中心应用中大量冷页的存在表明,通过以低性能开销降级更多冷页,存在充分发挥主动降级潜力的机遇。为实现更激进且主动的降级,必须采用不受高速内存使用状态影响的访问追踪方法——该方法需能追踪各数据未被访问的持续时间。
Exploring Aggressive and Proactive Demotion
本节旨在探究适合执行主动降级且对性能影响最小的新型管理单元。通过利用性能监控单元(PMU)进行分析,我们发现基准测试程序通常在内存分配单元(如malloc()分配的内存对象)内部呈现访问局部性特征。基于此发现,我们手动修改了多个基准测试程序的源代码,实现内存对象粒度的主动降级与提升操作。优化后的二进制文件在显著降低高速内存使用量的同时保持了较低的性能衰减,证明了基于内存分配单元的热/冷数据分类方案的可行性。
Benchmark Analysis using PMU
PMU: 现代处理器配备有专用硬件单元,用于分析系统性能特征。PMU基于用户定义的采样周期,通过基于采样的方法统计预定义硬件事件(如TLB缺失、缓存缺失和指令周期)的发生频率。
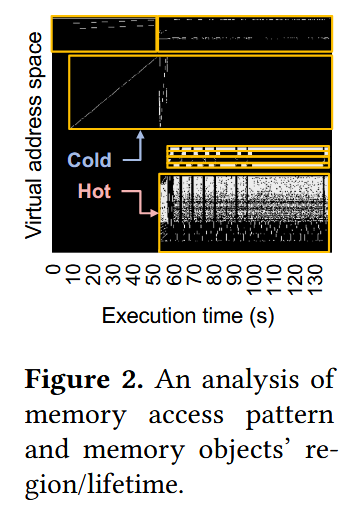
图2展示了liblinear运行期间发生LLC与L2 TLB缺失的虚拟地址空间随时间变化情况。黄色框表示通过malloc()分配的主要内存对象的区域和存续期。观测到的内存访问模式在单个内存对象内部呈现高度空间局部性(即整体呈现热或冷特性)。除liblinear外,其他被分析的基准程序也表现出类似的内存对象粒度访问行为。这些发现表明:区分热/冷数据的单元可从操作系统管理的页面级别扩展至内存分配单元(如内存对象),且内存分配单元可作为主动降级数据规模的判定依据。
内存对象(Memory Object) 是计算机系统中由程序或操作系统动态分配的一块连续虚拟地址空间单元,通常通过内存分配函数(如
malloc()、calloc()或new)创建,用于存储特定数据或数据结构。
Proactive Demotion with Manually Modified Binaries
为验证在操作系统层面使用内存对象作为主动降级单元的可行性,我们通过手动修改基准测试程序源代码生成的优化二进制文件进行了实验。通过分析源代码与执行流程,我们定位了主要内存对象(如图2所示)的分配与访问代码行。基于此分析,我们构建了优化二进制文件:当检测到某个内存对象停止被访问时立即触发降级,并在其即将被重新访问前执行提升操作,这一过程通过调用页迁移系统调用(如 move_pages())实现。
我们将优化二进制文件的工作集配置为适配高速内存容量,并在§5.1描述的分层内存系统中,对比了优化版本与原始版本(所有数据均分配至高速内存且无迁移操作)的性能(执行时间的倒数)及高速内存使用量。
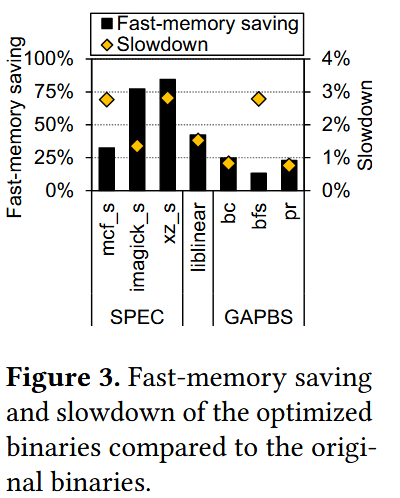
如图3所示,优化后的二进制文件以轻微性能下降(0.76%-2.82%)为代价,实现了大幅高速内存使用削减(13.2%-84.7%)。
这一结果表明:与现有研究采用的操作系统页粒度相比,以内存对象粒度执行主动降级/提升操作,能通过扩展迁移粒度实现更激进的降级策略,从而显著减少高速内存使用。
若能在操作系统层面识别此类内存分配单元并用于主动降级/提升操作,无需修改源代码即可达到与优化二进制文件相当的效果,为实现高效主动降级方案提供可能。尽管内存分配单元已在多项研究中被探索[10,15,19,44,48,55,61,62],但尚未被应用于操作系统级分层内存管理方案。
PET: Aggressive Demotion and Promotion
我们提出名为PET(高效分层内存管理的主动降级方案)的新型操作系统级主动降级方案。为实现激进且主动的降级,PET引入PET块(P-block)作为分层内存管理的新单元,利用操作系统层面内存分配单元内的访问局部性特性。与先前研究中的页粒度降级相比,PET基于P块的机制能更有效地识别需主动降级的目标数据。同时,凭借多步降级机制,PET能以更低的性能开销实现更大幅度的高速内存使用削减。
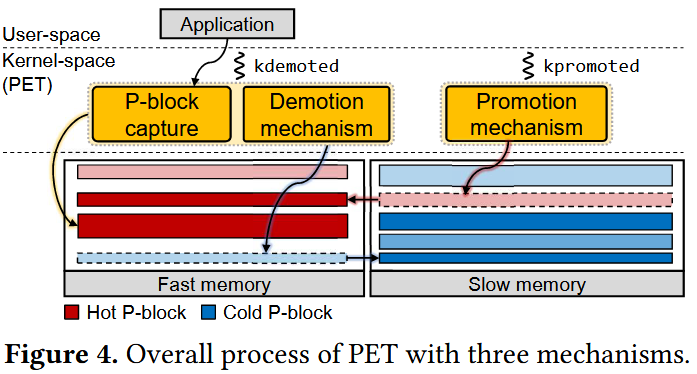
PET包含三大核心机制(见图4):
P块捕获机制:从操作系统管理虚拟地址空间的数据结构中提取新型P块(§4.1);
降级机制:基于P块信息通过多步骤执行主动降级,以低性能开销实现高速内存使用削减(§4.2)
提升机制:追踪已降级P块的访问状态,当低速内存访问次数超过预设阈值时执行提升,缓解低速内存访问导致的性能下降(§4.3)。
此外,我们在基础PET方案上扩展了文件页降级功能(§4.4)。
P-block: Management Unit for PET
由于在操作系统层面直接识别内存分配单元存在困难,我们通过利用操作系统的虚拟地址管理单元来近似模拟这些单元。多数操作系统通过将每个进程的虚拟地址空间划分为若干连续且不重叠的空间进行管理。每个连续虚拟地址空间具有独立属性(如访问权限),并指向进程的特定区域(如堆和栈)。这些空间在应用程序或内存分配器分配内存时创建,因此可用于捕获应用程序的内存分配单元。Linux、FreeBSD和Solaris等操作系统均具备此单元,本文后续将基于Linux的vm_area_struct将其称为VMA。
在全部VMA中,PET重点关注匿名mmap映射区域(anon_mmap)——该区域在应用程序或内存分配器分配大于MMAP_THRESHOLD(默认128KB)的内存时生成。我们证实anon_mmap在大多数应用(包括§3探讨的内存对象)中占据VMA的主导地位(超99%),且包含较大内存分配的anon_mmap更适合利用内存分配单元中的访问局部性。因此,PET捕获与每次内存分配对应的anon_mmap VMA,并将其作为分层内存的数据管理单元。
图5展示了liblinear分配内存对象时的P块生成流程:
响应虚拟内存分配请求(0x83fd49000至0x8e640b870),操作系统基于页对齐地址为请求的内存对象生成新VMA(图5-①)
随后将新生成VMA与相邻VMA合并以减少VMA数量(图5-②);
PET在合并前捕获生成VMA的单元至附加结构,该结构称为P块并作为分层内存的数据管理单元(图5-③)。
经验证,在评估负载中P块与malloc()分配的内存对象重叠率超97%。P块信息由名为kdemoted的内核线程定期更新(详见§4.2)。
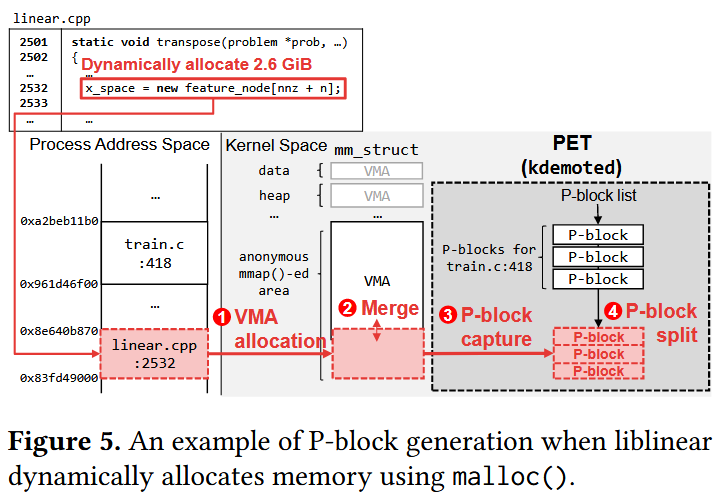
为防止精度损失,PET会对过大的捕获P块(例如GB级别)执行初始分割(图5-④)。大型内存对象(如图5所示)可能同时包含热/冷数据部分。以过大粒度管理此类内存对象会降低热/冷数据分类精度,进而损害性能。因此,PET将新生成的大型P块按特定尺寸分割。我们通过敏感性研究确定了初始P块分割尺寸(详见§5.3),并将最大P块尺寸设定为1GB。
1 GiB?? 这个读写流量放大不会很严重吗????
每个P块需要128字节的元数据(如访问计数与状态记录),但由于P块数量极少,PET的空间开销可忽略不计。在所用基准测试中,Graph500在工作集规模对应的P块数量最多——30GB工作集仅分配最多217个P块,空间开销仅占0.0001%。
Demotion Mechanism
基于P块机制,PET无需考虑高速内存总使用量即可执行降级操作,从而以微小性能影响为代价降低高速内存容量需求。专用于降级机制的内核线程kdemoted会定期更新捕获的P块信息,并以P块粒度(而非页粒度)追踪内存访问,仅需少量组件即可识别降级目标。然而,这种基于采样的方法可能频繁遗漏未采样页上的访问事件,导致冷P块识别不准确。因此,PET针对未被访问的P块执行细粒度多阶段决策流程,以精准识别降级目标。
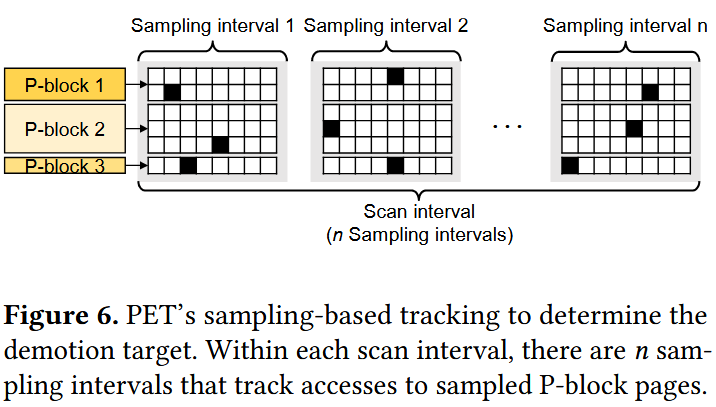
为识别降级目标,kdemoted采用基于采样的方法(见图6):利用P块内的访问局部性特性,仅追踪每个P块中的单个页,以此判断P块是否被访问。kdemoted通过两种不同周期(采样间隔/扫描间隔)定期唤醒:
采样间隔(例如数百毫秒):随机采样每个P块中的一个页,清空采样页的PTE访问位(若该页被访问则访问位会被置位);
扫描间隔(例如采样间隔的数十倍):收集追踪信息并识别降级目标P块。
采样间隔结束后,PET通过检查访问位在上一采样间隔内是否被置位,验证P块的访问状态。这种基于采样的方法通过PTE访问位最小化访问追踪的页表遍历开销。kdemoted将扫描间隔内未检测到访问的P块判定为冷数据。
PET根据冷热程度将每个P块划分为四种状态:NORMAL(正常)、PHASE1(阶段1)、PHASE2(阶段2)和DEMOTED(已降级)。PET初始将P块分配在高速内存中并设置为NORMAL状态(图7)。在每个扫描间隔,系统会根据P块的冷热程度更新其状态:
若处于NORMAL状态的P块被访问追踪机制判定为冷数据,kdemoted会将其切换至PHASE1状态,并启动更细粒度的访问追踪。

由于P块通常大于操作系统页尺寸,部分P块可能同时包含热数据块和冷数据块。若仅通过追踪P块内采样页来确定降级目标,可能导致误判。为解决此问题,当P块转入PHASE1状态时,PET会将其分割为若干临时块(图7-(a)与图8-①)。访问追踪机制从每个临时块中采样页,并以临时块粒度判定冷热状态。通过对临时块的精细化追踪,PET能更精确地监控内存访问模式,从而实现更准确的降级目标识别。
对于处于PHASE1状态的P块,PET会比较扫描间隔内未被访问的临时块(冷块)与已被访问临时块(已访问块)的总尺寸。若冷块总尺寸大于已访问块,PET会将P块切换至PHASE2状态(降级前的最终阶段)。对于PHASE2状态的P块,PET会随机选择并降级部分临时块(称为探测页),以进一步提升访问追踪精度:
将探测页的保护标志设置为PROT_NONE,使其首次访问触发虚假页错误;
处理虚假页错误时,PET会递增故障页所属临时块的访问计数器。
Q1: 这里的block指的是什么??多大??? 是否比2MB Page大 ??
Q2: 我理解这个P块本质上不就是一个类似Huge Page的东西吗? 这个block就类似于subpage。冷的识别从P块开始,冷的话在细分来看。图里是把它切成一行来看。(这个阶段就是进入PHASE 1)。
ok,有做敏感性实验
Q3: “若冷块总尺寸大于已访问块,PET会将P块切换至PHASE2状态(降级前的最终阶段)”依据是什么? 难道冷临时块的数量少就不对其降级吗???
我们谨慎设定探测页(canary pages)的比例,以精准评估P块的冷热状态:比例过小会降低降级/提升精度,而过高的比例可能导致不必要的降级开销。最终将探测页比例设置为临时块的10%,以平衡精度与开销。
对于处于PHASE2状态的P块,若其内部冷块总尺寸大于已访问块,PET则将其视为降级目标。针对内部访问模式不一致的P块,PET会根据临时块的冷热状态进行分割:在此过程中,将属性相同(均为已访问或冷)的相邻临时块合并为一个P块(图7-(c)与图8-②)。最终,PET将已访问的P块切换回NORMAL状态并提升其中的探测页;而对合并后的冷块P块执行降级操作并转换为DEMOTED状态,以此主动预防高速内存容量不足。
Q4: 这样的方式不会使得内存布局很乱吗??
PET的降级机制共包含五个用户可配置参数(采样/扫描间隔、最大P块尺寸、临时块尺寸、探测页比例)。这些参数的默认值均基于敏感性研究(§5.3)中普遍表现最优的配置设定。

Promotion Mechanism
PET同时执行提升操作,以快速检测并响应应用内存访问模式的变化,从而减少损害性能的低速内存访问。由于P块内存在访问局部性,访问一个页常会触发同一P块内其他页的访问。因此,PET以P块粒度识别提升目标。
??????
“由于P块内存在访问局部性,访问一个页常会触发同一P块内其他页的访问”,虽然motivation说malloc什么的内存对象具有这个性质。但换个方式理解,假设是系统开Huge Page,里面被访问的4KB Page会很多吗?? Page里也不是所有cacheline都会被访问,motivation是为了节省fast memory的空间,但这个promotion不是背道而驰吗??? 纯粹的为了把P块这个故事讲好,补齐的一部分。
尽管现有研究提出了有效的提升机制,但其基于页的方法直接适配于P块管理并不合适:例如,仅因少量页访问(如1-2次页错误[41]或8次加载[52])就提升整个P块会高估其热性,导致不必要的提升与降级循环;若按P块尺寸缩放提升阈值虽可提高精度,但会引发过多页错误与提升延迟。
这纯是自己机制引入的问题
因此,我们提出专为P块粒度设计的提升机制:
精准探测:仅在探测页(canary pages)上触发虚假页错误,以低成本及时捕捉访问模式变化;
异步提升:将提升决策与实际执行分离——页错误处理程序仅递增故障页所属P块的访问计数,若满足提升条件则向kpromoted内核线程发起提升请求,避免在错误处理关键路径中提升整个P块带来的性能惩罚。
为实现精准的提升目标选择,首次对已降级P块的虚假页错误不会立即触发提升。PET允许持续访问低速内存中的已降级P块,直至达到目标低速内存访问速率阈值,以此确保仅被少量访问后再度变冷的P块不会被过早提升。通过避免大型P块的过早提升,我们同时防止了高速与低速内存带宽的低效使用,以及高速内存容量的无效耗散。
PET的提升机制设定系统级目标低速内存访问速率Rpromo,其表示每秒允许的虚假页错误数量,并基于Thermostat[2]的以下公式计算:该公式根据误降级惩罚(即单次虚假页错误引发的额外延迟)计算满足用户可容忍性能下降的Rpromo值。
我们将可容忍性能下降设定为Thermostat采用的3%。对于误降级惩罚,我们保守采用单次提示错误的最坏情况额外延迟(而非Thermostat使用的低速内存访问延迟1μs):通过微基准测试在提升前以缓存行粒度顺序访问降级单元,测得每页平均额外延迟为8.3μs(含低速内存访问与提升操作的开销)。基于此误降级惩罚及10%的探测页比例,计算得Rpromo为360次/秒。将Rpromo乘以采样间隔,即可得到每个采样间隔的目标低速内存访问次数th_total。
PET还按各降级P块尺寸比例分配
每个采样间隔结束时,PET重置低速内存访问计数器;若降级P块总尺寸变化则重新计算th_block。这种动态调整使提升机制能适应多变工作负载,保持稳健运行。
File Page Demotion
Linux通过将可迁移页分类为匿名页与文件页进行管理。匿名页占据进程虚拟地址空间的大部分,可通过P块有效管理;而文件页作为来自存储器的缓存数据独立于进程存在,需单独管理。原生内核与现有研究要么优先将文件支持页作为降级目标[31,41],要么仅关注匿名页[16,46]。
鉴于进程通过open()访问文件并通过close()断开关联,PET将未链接至任何进程的文件(即所有打开过它的进程均调用close()的文件)视为降级目标。为识别此类文件,PET在每个inode中设置计数器(open_count),统计当前使用该文件的进程数。将open_count为零的inode加入由kdemoted线程管理的冷文件链表,并在每个扫描间隔降级冷文件链表中的文件。此文件页降级操作由kdemoted在后台执行,对应用性能影响极小。
Comparison with Modern OS Features
近期在Linux中实现的多代LRU(MGLRU)[42]对传统LRU进行了改进:基于冷热程度将页分类至多个代(通常为四代),通过定期按代排序并降级最老的页实现主动降级。MGLRU的页粒度访问追踪提供高精度,但需周期性检查所有页的访问位,带来显著系统开销。
数据访问监控(DAMON)[51]是Linux内核子系统,采用基于区域的采样追踪内存访问模式:它将地址空间划分为damon_region,并根据访问模式动态调整其大小,高效识别热/冷内存区域。近期基于DAMON的分层内存管理[30]被加入内核主线,利用其物理地址空间监控特性:两个内核线程分别扫描高速内存降级冷区域、扫描低速内存提升热区域。该方法显著降低监控开销,开启了基于区域的分层内存管理潜力,但仍面临以下挑战:
物理地址空间局部性缺失
其监控的物理地址空间相比虚拟地址空间呈现更弱的访问局部性,导致区域级内存管理难以捕获逻辑局部性。图10显示liblinear[17]与Redis[53]的访问模式:
liblinear在虚拟地址空间呈现明显局部性,而物理地址空间显示分散访问模式;
Redis请求遵循Zipf分布,虚拟地址空间呈现清晰时空局部性(高频访问对象聚集),但物理地址空间因映射碎片化无法体现该特性。
统一策略的运行时开销
对所有damon_region应用统一管理策略而未考虑其热性差异。如[67]所述,持续扫描与频繁区域调整会引入运行时开销,尤其对访问模式快速变化的应用影响显著。
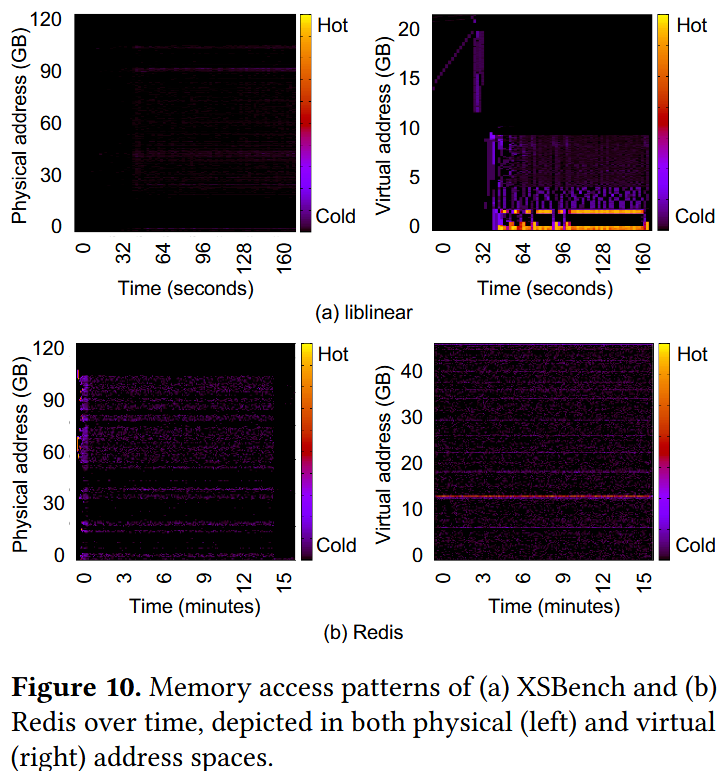
图注都标错了!(a)liblinear写成 (a)XSBench.
PET克服了基于DAMON的方法[30]固有的物理内存空间追踪局限性,同时通过基于区域的采样技术实现了高精度与低开销的统一。其通过监控每个进程的虚拟地址空间,可轻松识别合适的监控区域边界。为充分利用内存分配单元内的访问局部性,PET实现了P块捕获机制——在mmap()路径中生成新VMA时即时创建P块。
此外,PET根据P块的热度差异采用差异化追踪策略:
对热P块采用低开销、较低精度的追踪;
对冷P块则实施更精确的追踪以防止误降级。
该策略有效平衡了追踪开销与精度,在保持必要准确性的同时优化系统性能。
PET与[30]方案均通过内核线程实现,但线程职责分配存在本质差异:
[30]方案为每个内存层级分配独立内核线程,各线程独立监控指定层级、识别热/冷区域并迁移目标区域;
PET方案采用协同工作的双线程架构:
kdemoted负责P块创建、访问追踪与降级操作;
kpromoted专司提升任务。
通常kdemoted管理P块,但提升候选P块也对kpromoted可见,因此我们使用互斥锁防止资源竞争。在评估中,我们将PET与MGLRU及基于DAMON的主动降级方案对比,以凸显这些差异并证明本方法的有效性。
Evaluation
“+” strength
实验图画的很唬人,实验很多
“-” weakness
实验部分严重缺乏了与最近的Tiered Memory Systems的对比。
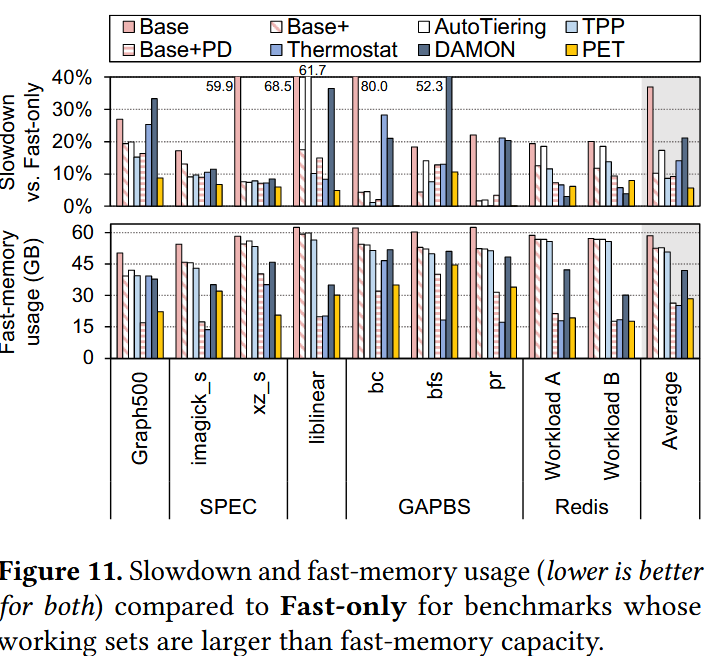
GAPBS是个随机访问比较多的benchmark,PET的机制这么大的P块,即使拆成临时块也容易把这些数据踢出去,所以才有底下这个图的效果;换成`libnear这个在motivation重点强调的trace反而比TPP还是Thermostat高。
像Slowdown这些,说实话也每缓解多少,如果和现在的比较新的Tiered Memory Systems相比,应该是性能比不过的。我是觉得P块粒度热页提升是很违背直觉的。