Pond (ASPLOS'23)
【Title】Pond: CXL-Based Memory Pooling Systems for Cloud Platforms
【定语描述】the first memory pooling system that both meets cloud performance goals and significantly reduces DRAM cost
Comments
不愧是ASPLOS'23杰出论文,这种文章再给我十年我都写不出来这篇文章一半的水平。感觉像是分析类论文和设计类论文完美合二为一,且仅仅在14页(包含参考文献)内就解释的比较清楚(但也正因如此,有些细节可能就一两句话,还需要进一步思考)。目前功力有限,许多地方还没太明白(比如虚拟加速器等等),这篇文章笔记会陆续迭代更新!
回到文章本身,像之前Memstrata笔记提过的一样,CXL太适合内存池化了。内存池化又非常适合云服务虚拟化场景。在未来的服务器集群或者数据中心,可以预见的是CXL会成为其中一大重要组成部分(阿里也是这么干的)。那CXL内存池就是一个新的场景,存在着许多未发现的问题和早就有的经典的问题。
没有(讨论)CXL的时候,也早就有RDMA内存池等等的概念。类似于延迟的问题也确实很早就应该有提到过。但是内存池的规模对延迟的影响,确实是我第一次在这篇文章中看到的。然后就是application对延迟的sensitive不一样,这也很显而易见。这篇文章就提供了一个非常好的量化数据。一结合,就更凸显了池规模的影响。这些看起来很直觉,但是也确实很重要。另一个大的点就是经典的内存搁浅(Memory Stranding),文章认为对这些Non-usage 的Memory,可以丢进内存池做一个zNUMA节点,完全(几乎)不会对VM产生影响,好处就是提升了利用率,那就能省钱了。相当于省了一大部分服务器内存的投入。那整个数据中心服务器越多,产生的经济效益的数量级就越大。
最后都是用了一个机器学习的模型进行预测,依然是看起来很直觉很简单,但是要确定什么样的指标、什么样的特性、什么样的标签,怎么样定义一个合理的损失,怎么样去减少缓解隐藏学习开销,都是值得深思的问题。以及多个模型如何平衡,平衡问题转化成什么样的优化问题,也是一个巧妙的地方。
例如本文Pond 旨在最大化分配到 CXL 池上的平均内存量,这由延迟不敏感性 (LI) 和未使用内存 (UM) 定义,同时保持错误预测率 (FP) 和超预测率 (OP) 低于目标虚拟机百分比 (TP)。FP和OP分别是LI和TP的函数,这里存在两个参数化的模型。两个模型的平衡通过解决一个基于给定性能降级容限 (PDM) 和达到该容限的目标虚拟机 (TP) 百分比的优化问题来实现。
相关概念
zNUMA
zNUMA(零核心虚拟 NUMA)是一种优化内存分配的机制,它通过创建一个没有 CPU 核心、但有内存的虚拟 NUMA 节点,来提高内存利用率并降低性能损失。
在云计算环境中,虚拟机(VM)通常运行在多个物理核心上。当 VM 被分配到不同 NUMA 节点的核心时,虚拟机内的进程可能需要访问远程内存,这会导致性能下降。因此,云服务提供商通常尝试将虚拟机的内存和核心绑定在同一个 NUMA 节点上,以确保较低的内存访问延迟。
zNUMA 是一种改进的虚拟 NUMA 节点技术,它的关键特点是该 NUMA 节点没有 CPU 核心,只有内存。
zNUMA 的一个重要功能是引导操作系统远离该节点上的内存分配。具体来说,操作系统会优先选择非 zNUMA 节点的内存来进行主要工作负载的分配,因为这些节点有对应的 CPU 核心,性能更好。而 zNUMA 节点则保留用于非关键性内存分配,比如一些闲置或者非时间敏感的数据。很多虚拟机通常不会使用它们所分配的全部内存。在这种情况下,zNUMA 节点可以容纳这些未使用的内存,而不需要对实际分配的内存进行管理调整。这意味着,即使虚拟机分配了大量内存,但未使用的部分可以放置在 zNUMA 节点,不会占用性能关键的本地 NUMA 内存。
由于 zNUMA 节点上的内存不包含关键性数据,虚拟机的性能不会受到影响。即使该内存被分配到了 zNUMA 节点,操作系统的内存管理机制也会确保重要的内存访问发生在有 CPU 核心的 NUMA 节点上。
zNUMA 的使用尤其适用于云计算环境中的虚拟机,这些虚拟机常常没有充分使用它们被分配的内存。例如,Azure 的测量显示,大约 50% 的虚拟机只使用了它们分配内存的一半甚至更少。zNUMA 允许这些未使用的内存进入一个共享池,从而为其他服务器所用,而不会影响当前虚拟机的性能。
Introduction
许多企业和用户在使用公有云时,会通过虚拟机(VM)来运行他们的应用程序或工作负载。虚拟机的好处是可以获得接近于独立服务器的计算性能,而不需要用户自己去管理数据中心的硬件和基础设施。
然而,对于公有云提供商来说,这样的模式带来了一个挑战:他们要在不深入了解用户虚拟机内部运行内容的前提下(即,虚拟机对云服务商来说是不透明的),仍然需要保证高性能,同时控制硬件成本。因此,如何为这些不透明的虚拟机提供既高效又经济的计算资源,成为了云服务商需要解决的难题。
同时,由于DRAM的扩展性差且只有初步替代品可供选择,它已成为硬件成本的主要部分。例如,在Azure中,DRAM可以占服务器成本的50%,而在Meta中,DRAM占机架成本的40%。通过对Azure生产跟踪数据的分析,我们发现内存闲置是内存浪费的主要原因,也是潜在的大幅成本节省的来源。内存闲置发生在服务器的所有核心已被租用(即分配给客户的虚拟机),但未分配的内存容量仍然存在且无法租用。我们发现,随着更多核心分配给虚拟机,多达25%的DRAM会变成闲置状态。
管存在大量的内存闲置问题,在公共云中减少DRAM使用仍然具有挑战性,因为它有严格的性能要求。例如,现有的进程级内存压缩技术需要处理页错误(page fault),这会增加微秒级的延迟,并且需要放弃静态预分配内存的方式。通过分离式内存(memory disaggregation)进行内存池化是一种有前景的方法,因为闲置的内存可以返回到解耦的内存池中,并供其他服务器使用。不幸的是,现有的池化系统同样有微秒级的访问延迟,并且需要处理页错误或对虚拟机客户系统进行修改。
4个Key Insights
随着池的规模增大,延迟也随之增加。 8-16个sockets的服务器分组也能够实现pooling的大部分好处。
文中的描述是8-16个sockets(就是小规模的pool)的延迟会增加70-90ns,而机架级别的延迟会增加180ns。
21%+的负载对pooling后的延迟增加敏感
结合第一点就突出了small pools的必要性
约一半的虚拟机仅使用了租用内存的一半或更少,虚拟机的 zNUMA 大小与其未使用的内存相匹配时,确实不会出现任何性能影响
这段不太像insights,反而像是说pond这个工作做了什么
主要也是基于机器学习方法的预测,预测的target是(1)VM是否latency sensitive (2)VM未使用的内存余量
预测不准的话,pond还利用监控机制触发缓解措施
ML模型输入的可以监控遥测,不会显著增加开销
提到的Contributions
首次公开对大型公共云提供商内存滞留和未触及内存的特征描述。
首次分析了不同 CXL 内存池大小的有效性和延迟。
Pond,首个基于 CXL 的全栈内存池,适用于云部署,且具备实际可行性和性能。
用于数据中心规模的延迟和资源管理的准确预测模型。这些模型可以实现 1-5% 的可配置性能降低。
广泛的评估验证了 Pond 的设计,包括 zNUMA 的性能以及我们预测模型在生产环境中的表现。我们的分析显示,通过使用跨越 16 个插槽的 Pond 池,我们可以将 DRAM 需求减少 7%,这对应于大型云提供商节省数亿美元的成本*
Background
Hypervisor Memory Management
在公共云中,计算资源通常以虚拟机(VM)的形式提供。虚拟化技术使得单台物理服务器可以运行多个虚拟机,每个虚拟机看起来都像是独立的计算机。Hypervisor负责管理虚拟机的资源,包括内存。为了优化虚拟机的性能并减少管理开销,Hypervisor尽量减少对内存的直接管理。它们通常依赖虚拟化加速器来提高输入/输出(I/O)性能。这些加速器可以帮助减少虚拟化带来的性能损失,使虚拟机的 I/O 操作更高效。直接 I/O 设备分配 (DDA) 和 单根 I/O 虚拟化 (SR-IOV) 是两种常见的虚拟化加速技术。这些技术帮助提升虚拟机的网络和存储性能,减少虚拟化层的中间处理。
DDA 允许虚拟机直接访问物理 I/O 设备,从而减少虚拟化层的开销。
SR-IOV 使得网络设备能够被多个虚拟机共享,同时保持高性能。
在 AWS 和 Azure 等云服务平台上,加速网络是默认启用的。这意味着它们在虚拟机和网络之间的通信中使用这些加速器,以提高数据传输速度和降低延迟。为了使虚拟化加速技术有效,虚拟机监控器需要静态地预分配或“固定”虚拟机的整个地址空间。这意味着在虚拟机运行之前,就已经为它分配了固定的内存空间。这种做法可以确保虚拟机的内存访问不会受到动态分配带来的性能影响。
Memory Stranding
内存闲置是在云计算环境中常见的问题,涉及资源分配和优化。
云服务的性能调优是一个多维装箱(背包)问题,在有限的资源中合理地安排物品,使得资源的利用最大化或浪费最小化。云服务提供商需要解决一个多维的装箱问题,即如何在有限的服务器资源上高效地安排虚拟机。在设计和配置服务器时,很难准确预测未来虚拟机的资源需求。因此,匹配服务器资源与未来虚拟机的实际需求是一项挑战。当实际到达的虚拟机对内存(DRAM)和 CPU 核心的需求与服务器提供的资源不匹配时,就会使得资源的高效利用变得更加困难。
内存闲置的例子就是在一个服务器中,虽然所有 CPU 核心已经被租用,但仍然有未被使用的内存。这种情况下的内存就是“闲置”的,因为虽然它在理论上可以租给客户,但由于所有的 CPU 核心已经被占用,实际租用内存变得不可行。
Resource Stranding
有多种技术可以减少内存资源滞留。例如,超额订阅核心(oversubscribing cores)可以使更多的内存得以出租。然而,因为性能原因,超额订阅仅适用于部分虚拟机。文章说在 Azure 上测量包括启用超额订阅的集群,但仍然显示出显著的Memory Stranding。
What does pond do ?
Pond针对的方法是将一部分内存解耦成一个可以被多个主机访问的池。这打破了服务器的固定硬件配置。通过动态地将内存重新分配给不同的主机,我们可以将内存资源转移到需要它们的地方,而不是依赖于每台单独的服务器在所有情况下都以悲观的方式进行配置。因此,我们可以将服务器的配置接近于平均的 DRAM 到核心的比例,并通过内存池来处理偏差。
CXL Pooling
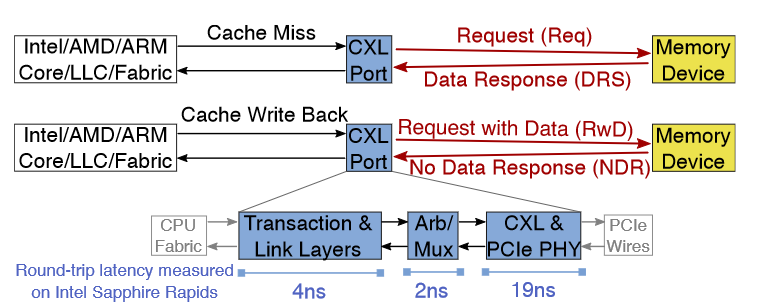
通过 CXL 的池化。CXL 包含多个协议,包括load/store内存语义(CXL.mem)和 I/O 语义(CXL.io)。
CXL.mem将设备内存映射到系统地址空间。当系统的最后一级缓存(LLC)缺失某个缓存行时,会生成对 CXL 端口的请求,该端口将带来缺失的数据行。写回操作也会通过 CXL 进行数据写入。这些操作不涉及页面错误处理或直接内存访问(DMA),从而减少了开销。
类似地,LLC 的写回操作会转换成 CXL 数据写入。以上操作都不涉及页面错误或直接内存访问(DMA)。CXL 内存使用虚拟化监控程序的页表和内存管理单元(MMU)进行虚拟化,因此与虚拟化加速兼容。
CXL.io协议便于设备发现和配置。CXL 1.1 针对直接连接的设备,CXL 2.0 增加了基于交换机的池化功能,而 CXL 3.0 标准化了无交换机的池化和更高的带宽。
CXL.mem 使用 PCIe 的电气接口,并具有定制的链路和事务层,以实现低延迟。使用 PCIe 5.0 时,一个双向 ×8-CXL 端口的带宽在典型的 2:1 读写比下与 DDR5-4800 通道相匹配。CXL 请求的延迟主要由 CXL 端口决定。Intel 测量的 CXL 端口往返延迟为 25ns ,结合预期的控制器侧延迟,导致在基本拓扑中 CXL 读取的端到端开销为 70ns,相较于 NUMA 本地 DRAM 读取。虽然基于 FPGA 的原型报告了更高的延迟,但 70ns 的延迟开销符合行业对基于 ASIC 的内存控制器的期望。
Memory Stranding & Workload Sensitive to Memory Latency
Memory Stranding
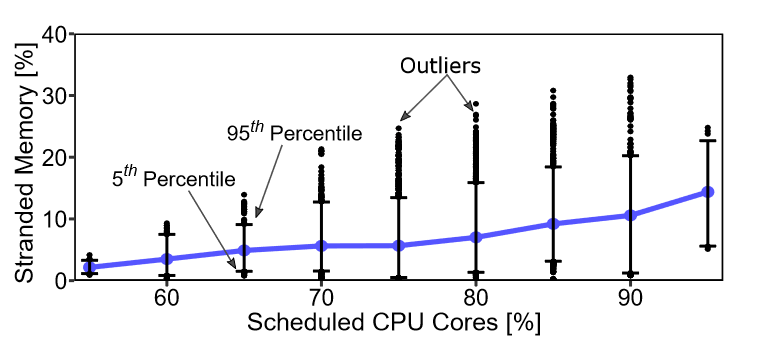
根据这个图,一个有意义的insight是,随着CPU利用率的提高,闲置的内存增多。内存闲置是高度利用节点的产生的负作用,而高度利用的节点与高度利用的集群相关联。
例如,一些快照中的虚拟机组合偏向于计算密集型虚拟机类型,这些类型不需要大量的 DRAM。这可能会导致在低利用率下也出现高闲置情况。在第 95 百分位,闲置率在高利用率期间达到 25%。个别离群点甚至达到 30% 的闲置率。
NUMA Spinning
NUMA(非统一内存访问)架构在多处理器系统中,每个处理器节点都与一定数量的内存紧密相连。为了优化性能,虚拟机监控程序(hypervisor)通常会尽量将虚拟机的计算核心和内存分配到同一个 NUMA 节点上,减少跨节点访问的延迟。
然而,在某些情况下,特别是在系统资源紧张或虚拟机配置不均衡时,虚拟机的核心可能会集中在一个 NUMA 节点,而内存却被分配到另一个节点上,这种现象称为 NUMA 跨越。尽管这种跨越会增加访问延迟,但在 Azure 上,这种情况比较少见:约 2-3% 的虚拟机出现 NUMA 跨越,而跨越的内存页比例不到 1%。
这种跨越情况的出现可能是由于资源分配的限制或系统负载不均匀。在实践中,虚拟机监控程序会尽量避免这种情况,以确保性能最优化,但在资源紧张时,NUMA 跨越是难以完全避免的。
Saving from pooling
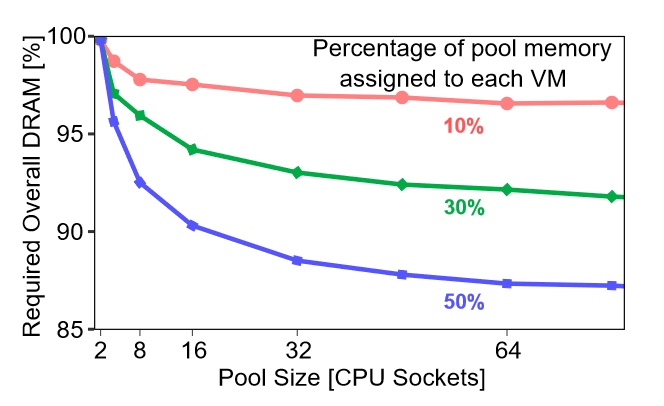
这里提到的Pool Size指的就是CPU Sockets的数量
根据上面这张图,可以得到这样的信息:不管是哪个比例(分配给每个VM的pool memory比例),在Pool Size变得比较大后,能够节省的DRAM非常有限。蓝色的线从32个Sockets到64个Sockets节省的DRAM直观上感觉就1%左右。
本文作者声称观察到在生产环境中,
95th的内存遗留率为 3%-27%,一些异常值达到 36%。
几乎所有虚拟机都适合放在一个 NUMA 节点中。
在 16-32 个socket之间进行内存池化可以减少集群内存需求 10%。这表明,内存池化可以显著降低成本,但这假设了很高比例的 DRAM 可以分配到内存池中。当实现跨 NUMA 节点的 DRAM 池时,提供商必须仔细缓解潜在的性能影响。
VM Memory Usage
据本文作者描述,在Azure中,所有集群中都有大量虚拟机存在未被使用的内存。总体而言,第 50 百分位的未使用内存为 50%。
虚拟机内存使用情况差异很大。
在未使用内存最少的集群中,仍有超过 50% 的虚拟机存在超过 20% 的未使用内存。因此,有大量未使用的内存可以被去聚合而不会造成性能损失。
面临的挑战是:(1)预测虚拟机可能拥有的未使用内存量,以及(2)将虚拟机的访问限制在本地内存上。
Pond要解决的就是这2个问题
Workload Sensitivity to Memory Latency
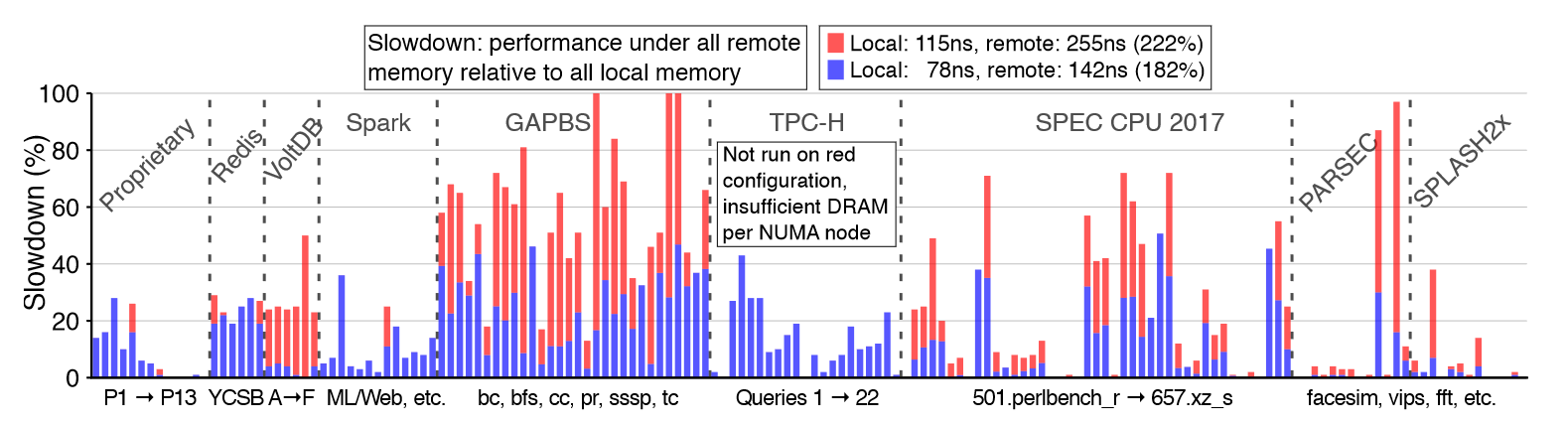
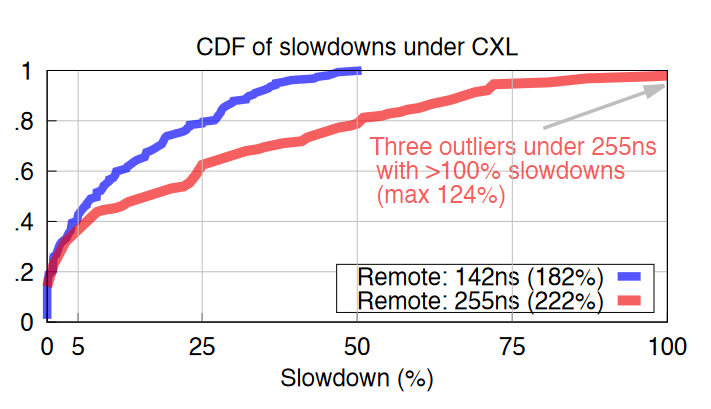
这个工作使用两种模拟 CXL 访问延迟(182%,222%)的场景下对 158 个工作负载进行评估,并与Local NUMA性能进行评估。
在内存延迟增加 182% 的情况下
26% 的 158 个工作负载在 CXL 下的slowdown少于 1%
另外 17% 的工作负载看到的slowdown不到 5%
有 21% 的工作负载面临超过 25% 的slowdown
一般来说,我们发现更高的延迟会放大低延迟下的效果
在 182% 延迟下表现良好的工作负载在 222% 延迟下也趋于表现良好;而在 182% 延迟下受到严重影响的工作负载在 222% 延迟下则受到更大的影响。
所以一个很大的Motivation就是 缓解对那些对延迟敏感的工作负载的 CXL 延迟影响。
如果能够有效识别敏感工作负载,内存池化解决方案可能会很有效
也就是说延迟不敏感的VM需要的memory可以都直接给CXL内存池里的。
Pond Design
整个Pond的设计目标主要包括下面四个
性能可与 NUMA 本地 DRAM 相媲美(低成本、高性能)
为了量化这个问题,文章定义了performance degradation margin (PDM,性能降级边际),以表示相对于完全在 NUMA 本地 DRAM 上运行工作负载的允许的性能下降。Pond 旨在实现一个可配置的 PDM,例如 1%,适用于一个可配置的尾部百分比 (TP) 的虚拟机,例如 98%。
为了实现这种高性能,Pond 使用一个小而快速的 CXL 内存池
由于 Pond 的内存节省来自池化而非超额订阅,Pond 必须在其系统软件层中最小化池的碎片化和浪费
与虚拟化加速器兼容 (硬件兼容性)
Pond 在虚拟机启动时预分配本地和池内存。Pond 在其分配、性能监控和缓解管道(mitigation pipeline)中决定这些分配。该管道使用新颖的预测模型来实现 PDM。
与不透明的虚拟机和客户操作系统/应用程序兼容 (软件兼容性)
使用轻量级的硬件计数器遥测来克服虚拟机的不透明性
主机资源开销低
使用轻量级的硬件计数器遥测来克服虚拟机的主机开销
Hardware Layer
这一段太硬了,说实话不是很想看,总之就是说8-16 socket的延迟比较低
Pond Pool中的Host拥有独立的缓存一致性域,并运行各自的 hypervisor。Pond 使用一种所有权模型,其中pool memory在主机之间显式移动。一个新的外部内存控制器 (EMC) ASIC 使用多个 DDR5 通道通过一组运行在 PCIe 5 速度下的 CXL 端口来实现池内存。
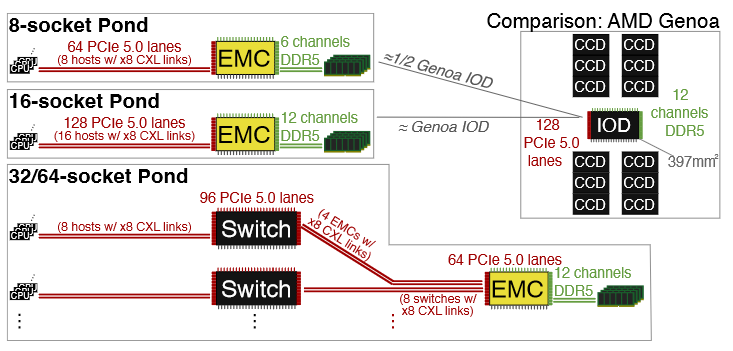
EMC 内存管理。 EMC 提供多个 CXL 端口,并在每个主机上呈现为单个逻辑内存设备 。在 CXL 3.0 中,这种配置被标准化为多头设备 (MHD) 。EMC 通过一个主机管理的设备内存 (HDM) 解码器在每个端口上暴露其全部容量(例如,提供给主机)。主机对每个 EMC 的地址范围进行编程,但最初将其视为离线。Pond 动态分配内存,粒度为 1GB 的内存切片。每个切片在任何给定时间只分配给一个主机,主机会显式地收到有关更改的通知。跟踪 1024 个切片(1TB)和 64 个主机(6 位)需要 768B 的 EMC 状态。EMC 通过检查每个内存访问的权限,即请求者和缓存行切片的所有者是否匹配,来实现动态切片分配。不允许的访问会导致致命的内存错误。
EMC 提供多个 ×8-CXL 端口,这些端口通过片上网络 (NOC) 与 DDR5 内存控制器 (MC) 通信。这些 MC 必须具备与服务器级内存控制器相同的可靠性、可用性和可维护性能力,包括内存错误纠正、管理和隔离。
Pond 的 EMC 的一个关键设计参数是池的大小,这定义了能够使用池内存的 CPU Sockets数量。我 EMC 的 IO、(De)Serializer 和 MC 需求类似于 AMD Genoa 的 397𝑚𝑚2 IO-die (IOD) 。如上图显示,16 插槽 Pond 的 EMC 需求与 IOD 的需求相匹配,而一个小型 8 sockets Pond 则与 IOD 的一半相匹配。因此,最多可以有 16 个sockets直接连接到一个 EMC。池大小为 32-64 的情况下,将结合 CXL switch与 Pond 的多头 EMC。最佳设计点在于平衡较大pool size的潜在节省与较大 EMC 和switch的额外成本。
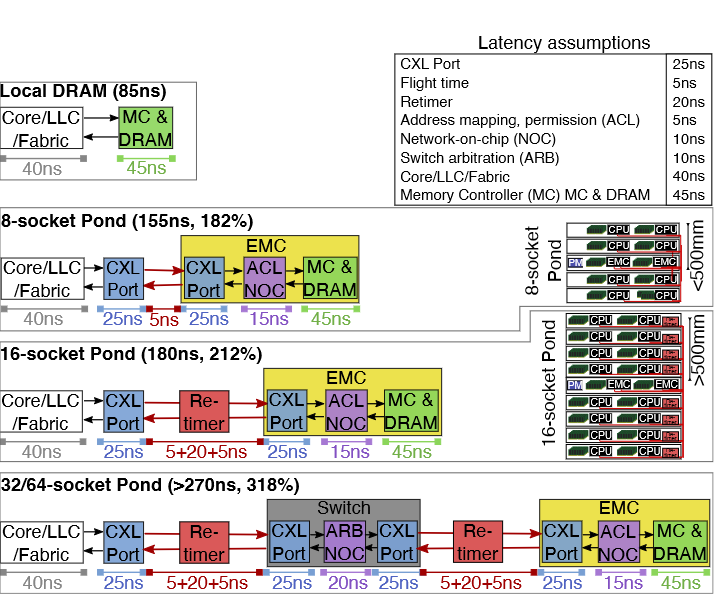
EMC 延迟。 尽管延迟受传播延迟的影响,但主要由 CXL 端口延迟以及任何使用的 CXL 重定时器和 CXL Switch决定。
在数据中心条件下,信号完整性模拟表明 CXL 在超过 500mm 的距离上可能需要重定时器。Switch由于端口/仲裁/NOC 造成至少 70ns 的延迟,估计超过 100ns 。

Pond 在 8 和 16 插槽池下将延迟降低了 1/3,仅比 NUMA 本地 DRAM 增加了 70-90ns
System Software Layer
软件层面有几个组件构成,详细信息请参见论文
Pool Memory Ownership
池管理涉及将 Pond 的内存切片分配给主机,并为池回收这些内存。这包括
实现pool memory分配的控制路径
防止pool memory碎片化。
Failure management 故障管理
Hosts在cacheline粒度上interleave accorss-socket local memory。尽管hosts可能连接到多个EMC,但不会在EMC之间交错内存。这最小化了EMC的影响范围,并便于内存热插拔。EMC故障仅影响在该EMC上拥有内存的虚拟机,而其他EMC上的虚拟机则正常运行。CPU/Host故障是隔离的,相关的池内存将重新分配给其他主机。池管理器故障会阻止重新分配池内存,但不会影响数据路径。
Exposing pool memory to VMs
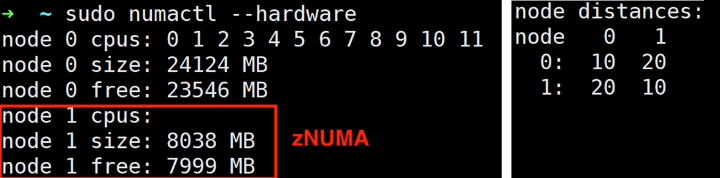
将池内存暴露给虚拟机。使用NUMA本地内存和池内存的虚拟机将池内存视为zNUMA节点。虚拟机监控器通过添加一个内存块(node_memblk)来创建zNUMA节点,但在SLIT/SRAT表中的node_cpuid中没有相应的条目。Guest OS优先从本地NUMA节点分配内存,然后才会使用zNUMA。因此,如果zNUMA的大小设置为未使用的内存量,它将永远不会被使用。下面是一个Linux VM,其中包含NUMA距离矩阵(numa_slit)中的正确延迟。Guest操作系统提供了NUMA感知的内存管理
Reconfiguration of memory allocation
为了保持与虚拟加速器兼容,本地和池内存映射在虚拟机生命周期内通常保持静态。但有两个Exception:
虚拟机的实时迁移
发生内存故障时重新映射页面时
虚拟机监控器会暂时禁用虚拟化加速,虚拟机将回退到较慢的I/O路径。这两种情况都是快速且短暂的,通常在虚拟机的生命周期内只发生一次。
Pond实现了第三种变体,允许Pond对次优内存分配进行一次性修正。
如果主机有可用的本地内存,Pond会禁用加速器,将虚拟机的所有内存复制到本地内存中,然后再次启用加速器。
对于每GB分配给虚拟机的池内存,这大约需要50毫秒
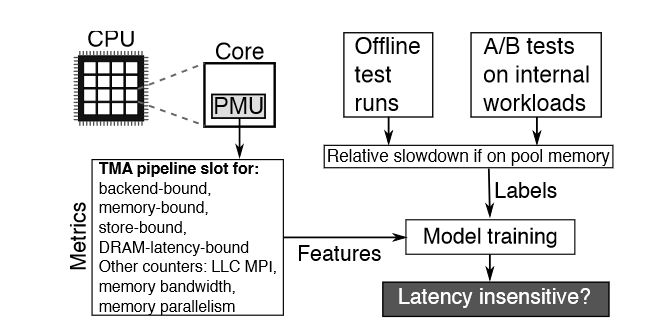
Telemetry for opaque VMs
不透明虚拟机的遥测。Pond 需要两种类型的虚拟机遥测数据。
使用核心性能测量单元(PMU)来收集与内存性能相关的硬件计数器。
具体而言,pond使用顶层分析法TMA。TMA 描述了核心流水线sockets的使用情况。例如,使用“内存绑定”指标,它定义为由于内存加载和存储导致的流水线停顿。图12列出了这些指标。虽然 TMA 是为 Intel 开发的,但其相关部分也适用于 AMD 和 ARM。
使用虚拟机监控器的遥测功能来跟踪虚拟机的未使用页面
利用现有的计数器来跟踪客户机已提交的内存,该计数器通常会高估实际使用的内存量。该计数器适用于98%的Azure虚拟机
Distributed Control Plane Layer
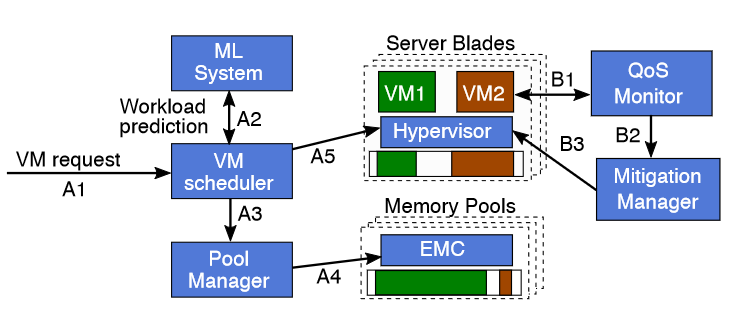
这层的两个主要任务
在虚拟机调度过程中进行内存分配预测
QoS监控和问题解决
对于(1)Predictions and VM scheduling 这个任务
Pond 使用基于机器学习的预测模型来决定为虚拟机分配多少池内存。当虚拟机请求到达后(A1),调度器会向分布式机器学习服务系统查询(A2),以预测该虚拟机需要分配多少本地内存。然后,调度器将目标主机和相关的池内存需求告知池管理器(A3)。池管理器通过配置总线触发EMC和主机的内存上线工作流程(A4)。内存上线速度足够快,不会阻碍虚拟机的启动时间。调度器通知虚拟机监控器在与上线内存量匹配的zNUMA节点上启动虚拟机。内存下线速度较慢,无法在虚拟机启动的关键路径上进行。Pond 通过始终保持一部分未分配的池内存缓冲区来解决这个问题。当虚拟机终止时,主机异步释放相关的内存片段,以补充该缓冲区。
对于(2)QoS monitoring 这个任务
Pond 通过其 QoS 监控器持续检查所有正在运行虚拟机的性能。监控器会查询虚拟机监控器和硬件性能计数器(B1),并使用延迟敏感度的机器学习模型来判断虚拟机的性能影响是否超出 PDM。如果超出,监控器会请求其缓解管理器(B2)通过虚拟机监控器触发内存重新配置(B3)。重新配置后,虚拟机将只使用本地内存。
Prediction Models
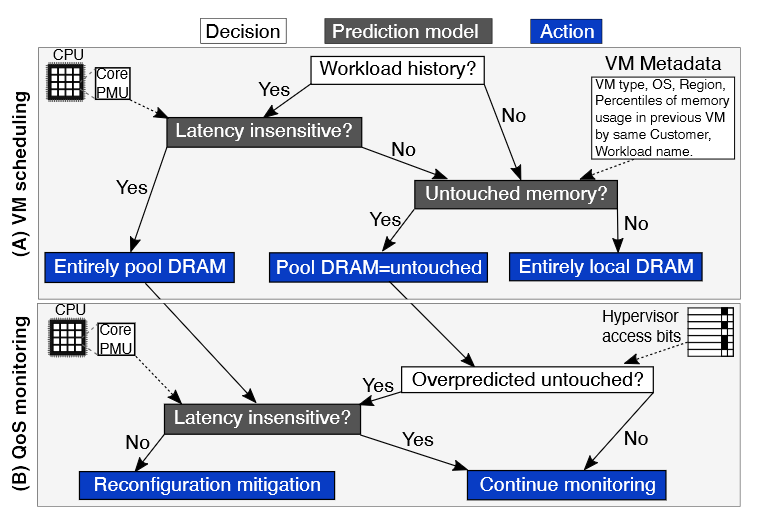
Predictions for VM scheduling (A)
在调度时,首先检查是否可以将工作负载历史与请求的虚拟机相关联。这是通过检查是否有之前具有与请求虚拟机相同元数据的虚拟机来实现的,例如客户ID、虚拟机类型和位置。这基于这样一个观察:来自同一客户的虚拟机往往表现出类似的行为。如果有之前的工作负载历史,就会预测该虚拟机是否可能对内存延迟不敏感,即在仅使用池内存时,其性能将保持在 PDM 之内。对延迟不敏感的虚拟机将完全分配在池 DRAM 上。
单独再写一遍: 来自同一客户的虚拟机往往表现出类似的行为
根据上述图,简单总结一下:
有无历史记录,无历史记录就直接认为latency-sensitive
non-latency-sensitive 直接把pool memory丢给它
latency-sensitive就得再看看Untouched Memory (后面都写成UM)
UM=0,就只分配local DRAM (有一个问题:
Local DRAM满了怎么办 ? 多个VM可以用一个Local DRAM对吧?)UM>0 以GB向下取整,按百分比分配pool memory & zNUMA节点,剩下就是local DRAM
UM要是(预测)过大,就调用QoS缓解器缓解一下
重要的是,Pond 始终保持虚拟机的内存在虚拟机监控器的页表中映射。这意味着即使预测不准确,性能也不会急剧下降。
QoS monitoring (B)
对于 zNUMA 虚拟机,Pond 监控在调度期间是否高估了未使用内存的数量。对于使用内存池支持的虚拟机以及未使用内存少于预测量的 zNUMA 虚拟机,pond使用敏感度模型来确定虚拟机工作负载是否遭受了过多的性能损失。如果没有,QoS 监控器将启动实时虚拟机迁移,将其重新配置为完全分配到本地 DRAM 上。
Model details
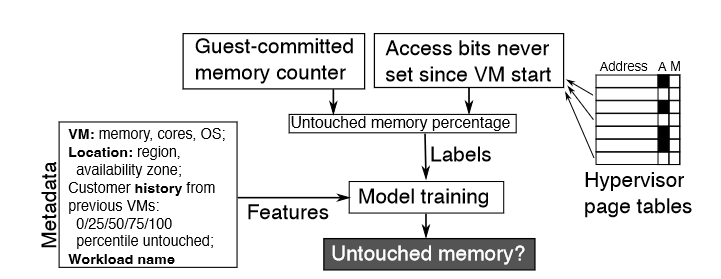
Pond 的两个机器学习预测模型利用 Pond 系统软件层中可用于不透明虚拟机的遥测数据。
(Telemetry for opaque VMs 那一节的图) 展示了延迟不敏感性模型的特征、标签以及训练过程。该模型使用监督学习 ,以核心性能监控单元(PMU)指标作为特征,并以内存池相对于 NUMA 本地内存的slowdown作为标签。Pond 通过离线测试运行和内部工作负载的 A/B 测试获取slowdown样本,并使用这些性能数据重新训练模型。这些特征-标签对每天都会用来重新训练模型。由于核心 PMU 负载较轻,Pond 在虚拟机运行时持续测量核心 PMU 指标。这使得 QoS 监控器能够快速反应,并保留那些对延迟敏感的虚拟机的历史记录。上图展示了未使用内存模型的输入和训练过程。该模型使用监督学习,以虚拟机的元数据作为特征,以每个虚拟机生命周期中的最小未使用内存量作为标签。其最重要的特征是过去一周内某客户虚拟机记录的未使用内存的百分位数范围(如 80%–99%)
Parameterization of prediction models
Pond 的延迟不敏感性模型通过参数化来确保错误预测率 (FP) 保持在目标值以下,即模型错误地将工作负载标记为延迟不敏感,而实际上这些工作负载对内存延迟是敏感的。这个参数强制了一个权衡,因为被标记为延迟不敏感 (LI) 的工作负载百分比是 FP 的函数。
例如,0.1% 的错误预测率可能会导致模型将 5% 的工作负载标记为延迟不敏感。
这个数值应该会变化,那怎样变化呢?0.1%FP导致 LI+5%。那0.2% FP呢 ? 这一定是线性的吗?
同样,Pond 的未使用内存模型也通过参数化来确保超预测率 (Overprediction, OP) 保持在目标值以下,即模型预测的工作负载使用的内存比实际多,从而会使用 zNUMA 节点上的内存页。该参数强制了一个权衡,因为未使用内存 (UM) 的百分比是 OP 的函数。
例如,0.1% 的超预测率可能会导致模型预测 3% 的未使用内存。
由于存在两个模型及其各自的参数,Pond 需要决定如何在两个模型之间平衡错误预测率 (FP) 和超预测率 (OP)。这种平衡通过解决一个基于给定性能降级容限 (PDM) 和达到该容限的目标虚拟机 (TP) 百分比的优化问题来实现。
具体来说,Pond 旨在最大化分配到 CXL 池上的平均内存量,这由延迟不敏感性 (LI) 和未使用内存 (UM) 定义,同时保持错误预测率 (FP) 和超预测率 (OP) 低于目标虚拟机百分比 (TP)。
TP 本质上定义了 QoS Moniter需要参与并启动内存重配置的频率。除了 PDM 和 TP 之外,Pond 没有其他参数,因为它会自动解决来自如下公式的优化问题。模型依赖其各自框架的默认超参数
.png)
Findings
有几个非常有意义,有几个其实就是单纯的实验结果,也算不太上是Findings,只能算是Results。
这怎么不是一种写作技巧呢? (doge
Finding #1
zNUMA 节点在将内存访问限制在本地 vNUMA 节点上非常有效。只有一小部分访问会到达 zNUMA 节点。
作者怀疑这部分原因是由于Guest OS内存管理器的元数据被明确分配在每个 vNUMA 节点上。作者发现,视频工作负载发送的内存访问中少于 0.25% 会到达 zNUMA 节点。同样,另外三个工作负载发送到 zNUMA 节点的内存访问占比为 0.06% 到 0.38%。本地 vNUMA 节点内的访问是分散的。
由于 zNUMA 上的内存访问占比微乎其微,我们预计在正确预测未使用内存的情况下,性能影响也会微不足道。
Finding #2
在对未使用内存的正确预测下,工作负载的减速分布与全部使用本地内存时相似
这个性能结果是预期的,因为 zNUMA 节点很少被访问 (§6.2)。因此,我们的评估可以在对未使用内存的正确预测下假设没有性能影响 (§6.5)。
Finding #3
对于未使用内存的过度预测(以及相应地,局部 vNUMA 节点的规模不足),工作负载会溢出到 zNUMA。许多工作负载会立即受到slowdown的影响。如果更多的工作负载内存溢出到 zNUMA,减速情况将进一步加剧。有些工作负载的减速幅度高达 30-35%,当 20-75% 的工作负载内存溢出时,如果完全分配在池内存上,则减速幅度可达 50%。我们使用访问位扫描来验证这些工作负载确实在积极访问其整个工作集。
将固定比例的池内存分配给虚拟机会导致显著的性能减速。减少这种影响只有两个策略:1)识别哪些工作负载会出现减速;2)在池内存上分配未使用内存。Pond 同时采用这两种策略。
Finding #4
虽然 DRAM 限制与slowdown相关,但我们发现一些例子,即使在只有小百分比的 DRAM 限制情况下,仍然会出现较高的slowdown。例如,多个工作负载在仅有 2% 的 DRAM 限制时就超过了 20% 的slowdown。
这表明预测工作负载是否超过 PDM 的困难性。启发式方法和预测器都会产生统计误差。
Finding #5
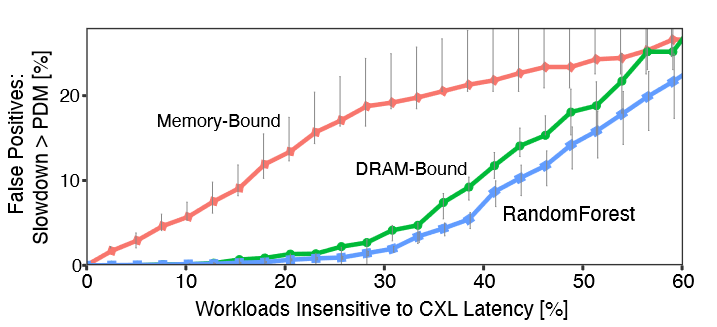
我们发现“DRAM Bound”明显优于“Memory Bound”。我们的随机森林模型的表现略优于“DRAM Bound”。
Finding #6
GBM 模型的准确性比静态策略高出 5 倍。例如,当将 20% 的内存标记为未使用时,GBM 仅过度预测 2.5% 的虚拟机,而静态策略则过度预测 12%。
Finding #7
模型的生产版本表现与模拟模型相似。分布变化导致随时间出现一些波动。
准确预测未使用内存是可行的,并且是一个现实的假设。
Finding #8
Pond 的组合模型通过找到各个模型的最佳组合而优于其单独模型。
Finding #9
在池大小为 16 个sockets时,Pond 在延迟增加 182% 和 222% 的情况下,分别减少了 9% 和 7% 的整体 DRAM 需求。静态策略减少了 3% 的 DRAM。当 PDM 在 1% 到 10% 之间变化,TP 在 90% 到 99.9% 之间变化时,我们发现这三个系统的相对节省效果 qualitatively 相似
Finding #10
在整个仿真过程中,Pond 的池内存离线速度在 99.99% 和 99.999% 的虚拟机启动情况下分别保持在 1GB/s 和 10GB/s 以下